# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
文本生成图像的领域早已经是一片红海,看上去已经卷无可卷了。
想在当下训一个很牛的文生图模型,你需要什么?
如果从当下主流方案入手,那需要:预训练好的 VAE 编解码器、文本编码器的拼接、精心设计的条件注入机制、海量数据、RL 或 DPO 对齐阶段……
总体上,大家似乎默认了一个前提:做文生图,就是得这么复杂。
而何恺明团队却反其道而行之,在文生图模型领域做出了新的思考。他们发布了 MiniT2I —— 一个刻意追求极简的像素空间文生图模型。
没有 VAE 编解码器,没有 AdaLN 条件注入,没有辅助损失函数,没有私有数据,没有 RL/DPO 对齐,纯粹的流匹配目标直接在像素上训练。258M 参数的 B/16 版本,在 GenEval 上达到 0.87,DPG-Bench 达到 84.2,超越了参数量大它数倍的同类像素空间模型。

MiniT2I 的核心主张是:如果把文本条件当作「带有语义信息的上下文 token」注入模型,文生图和类别条件的 ImageNet 生成在本质上并没有那么大的区别 —— 架构可以相似,算力可以相当,甚至数据量级也可以对齐。

像素空间直出,不要 VAE
MiniT2I 的第一个设计选择就很激进:丢掉 VAE,直接在 RGB 像素上做去噪。
潜在扩散模型(Latent Diffusion)是当前主流范式,先用自编码器把图像压缩到低维空间再做扩散。这确实让高分辨率变得可行,但代价是引入了重建误差、额外的训练阶段、以及编码器 - 去噪器之间的目标不对齐问题。
MiniT2I 选择像素空间的理由很务实:对于 512×512 分辨率,用 16×16 的 patch 把图像切成 1024 个 token,序列长度完全在 Transformer 的舒适区内。去掉 VAE 后,单步前向的计算从~1379 GFLOPs 降到~570 GFLOPs(B/16 设置),而且不存在重建精度的上限问题 —— 去噪器能力有多强,输出就能有多好。
实验也证实了这一点:在相同参数预算下,像素模型的 FID 和潜在空间模型持平(18.7 vs 19.0),但单步成本低了 5 倍。

MM-JiT 架构:回归朴素 Transformer
SD3 的 MM-DiT 在每个 block 中用 AdaLN(Adaptive Layer Normalization)将时间步和池化文本编码注入网络 —— 每个子块需要计算 scale、shift 和 gate 参数,通过一个额外的 MLP 从条件向量生成。这是一套精巧的调制机制,但 MiniT2I 发现它并非必需。
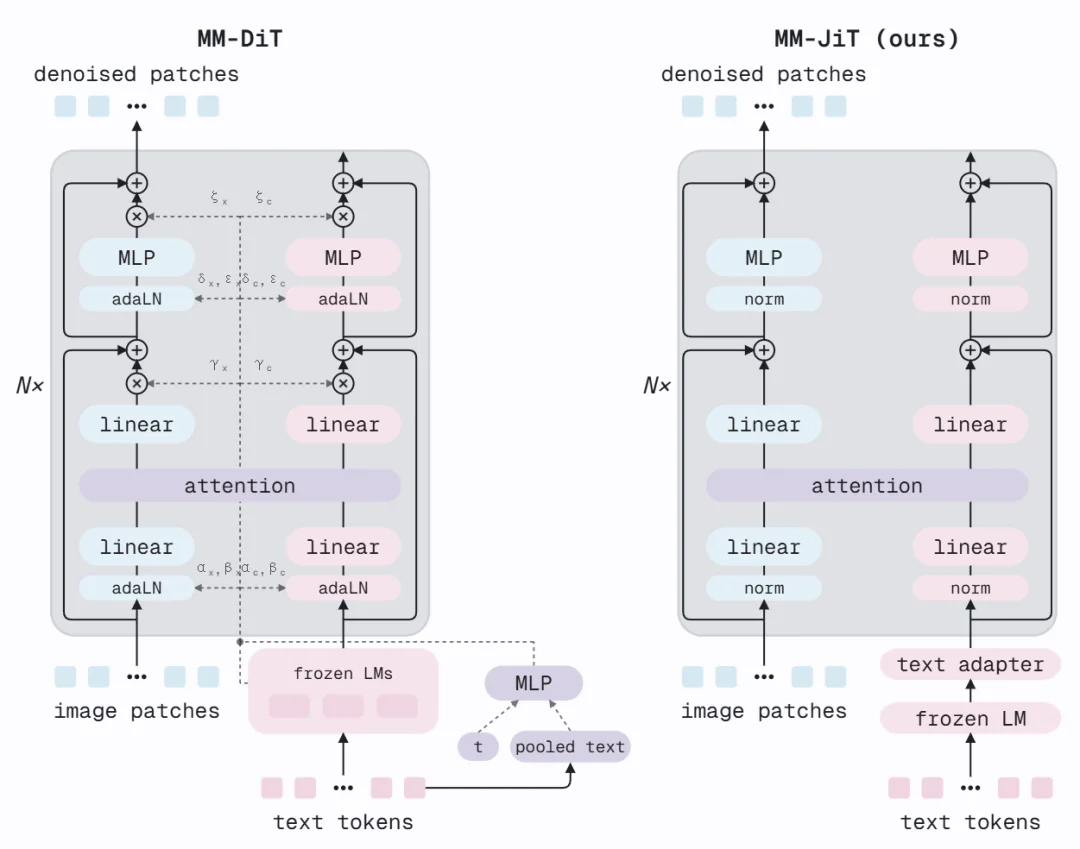
MiniT2I 提出的 MM-JiT 架构做了两件事:
1. 加两层文本适配器:在联合注意力之前,插入两个轻量 Transformer block,让冻结的 T5 特征先「适应」去噪器的需求。
2. 删除 AdaLN 分支:不再通过额外路径注入时间步和全局文本信息。模型依然能感知噪声水平 —— 因为被噪声污染的图像本身就携带了时间步信息。
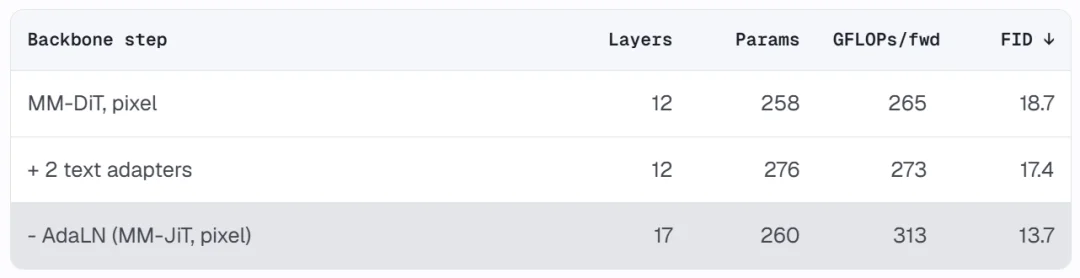
结果是一个接近标准预归一化 Transformer 的干净架构。去掉 AdaLN 后参数减少,但可以用相同算力预算换来更多层数(12 层 → 17 层)。FID 从 18.7 降到 13.7,同时架构本身更容易理解和修改。
训练数据:全公开,两阶段
MiniT2I 的训练数据同样追求极简:
这种「预训练 - 微调」的两阶段模式完全对标 LLM 的训练范式:预训练买覆盖面,微调教模型什么是好答案。消融显示两者缺一不可 —— 只做预训练,图像质量可以但提示跟随很差;只做微调,模型看到的世界太窄,生成多样性坍塌。
在像素空间文生图的对比中,MiniT2I 的性价比极为突出:
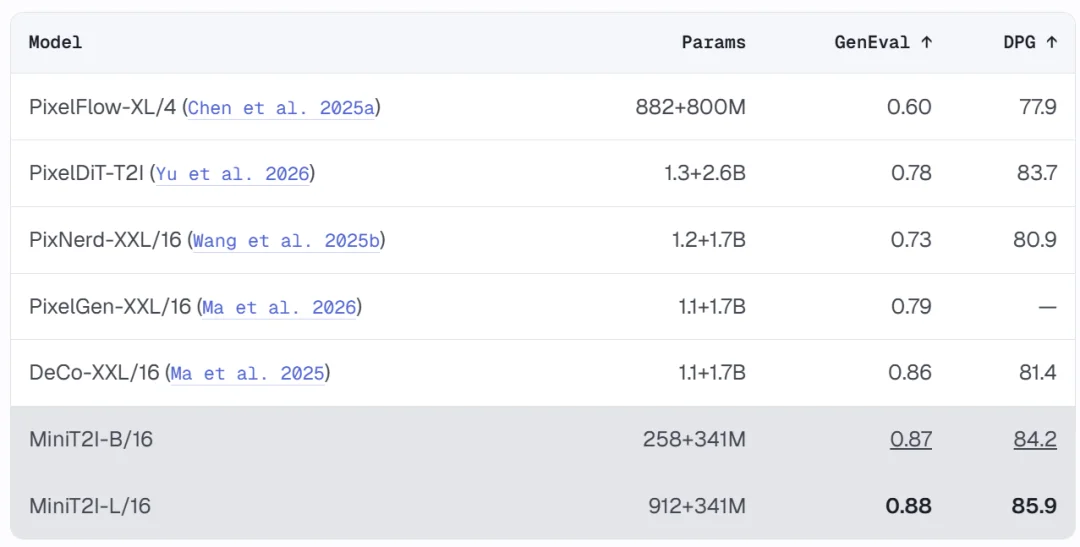
MiniT2I-B/16 仅用约 600M 总参数(含文本编码器),就在 GenEval 和 DPG-Bench 上超越了参数量 3-4 倍于己的模型。而且训练成本极低:B/32 消融模型在 8 张 H100 上只需约 3 天,总训练 FLOPs 与标准 ImageNet 200 epoch 实验相当。
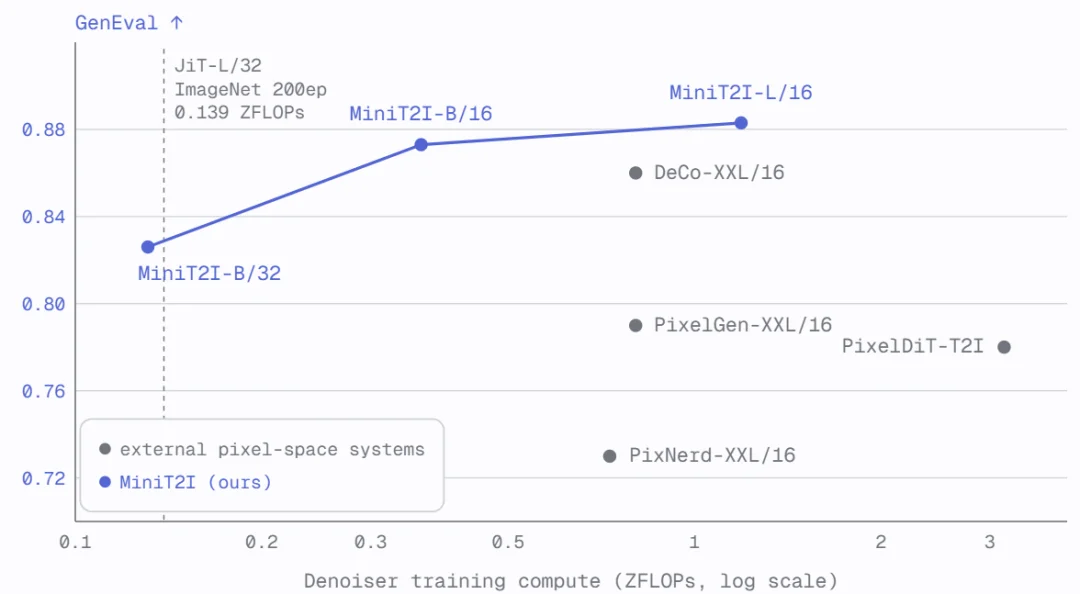
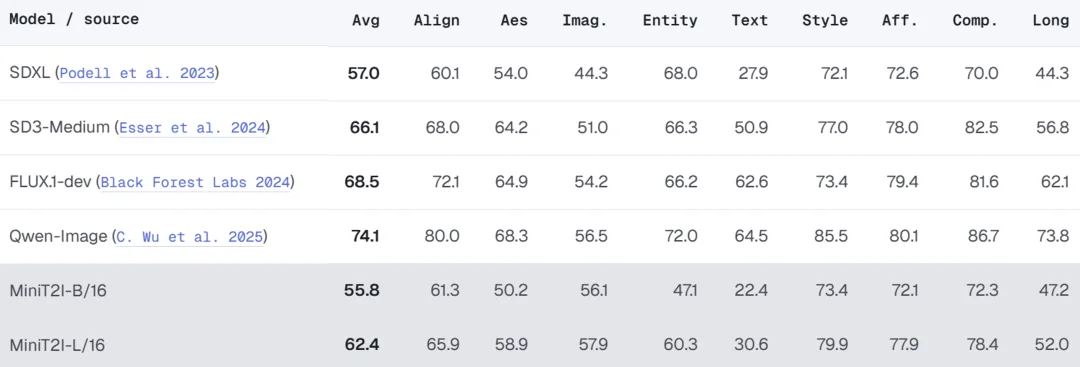
扩展到 L/16(912M 参数)后,模型在风格多样性、空间关系和文字渲染方面都有明显进步,与 SD3-Medium(~2B 参数)在想象力场景上的生成质量相当甚至更优。
在更全面的 PRISM-Bench 评测中,MiniT2I-L/16 在风格、组合和想象力维度上表现出色(79.9、78.4、57.9),已经接近 SD3-Medium 水平。但在文字渲染(30.6 vs SD3 的 50.9)和命名实体(60.3 vs 66.3)上仍有差距 —— 团队坦承这是公开数据配方的固有局限,需要补充专项数据来弥补。
MiniT2I 是一条技术路线的概念验证,而非最终产品。团队诚实地指出了几个未解问题:
MiniT2I 证明了现阶段的文生图不是只有顶尖工业实验室才能玩的游戏。
当一个 258M 参数的模型,用纯公开数据,在学术级算力上训练 3 天就能打败体量大数倍的对手时,或许文生图正在经历从「堆料」到「提纯」的范式转换。
「T2I 不再是高不可攀的围墙。欢迎使用并改进它,打造更简洁的基线。」
文章来自于"机器之心",作者 "机器之心编辑部"。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
