# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Anthropic增加绿卡认证后,最开心是智谱,直接原地化身战狼,高呼「前沿智能属于所有人」,提前把专注Coding的GLM5.2发了。
除了刷一波国产品牌好感度外,还精准狙击了同样在最近发布的Kimi 2.7 code。
只能说Kimi 2.7 code还是发早了,不然高低能跟GLM5.2一起当国产双子星😭
不过话又说回来,虽然Anthropic是个畜生,但智谱能有今天的万亿市值。Anthropic是最大功臣。
首先是Claude不当人,Claude Code刚火没多久就开始疯狂封号,我用了Claude Code两天就给我干没了。
但广大人民群众又有用上先进Claude Code的客观需求,于是Claude Code+国产模型的特色用法应用而生。
那一波里面发力最狠的是智谱市场。因为我刷到的博主全在推荐Claude Code+智谱GLM Coding Plan。
智谱还专门整了一句话(npx @z_ai/coding-helper)直接配置。两边一起发力,爽吃Claude Code退出中国的大部分流量。
甚至到现在,智谱官方支持的Coding Agent工具里,排名第一的还是Claude Code。大伙公认能发挥GLM 5.2能力的也是Claude Code。
你的文字还爱他😭
反观Minimax/Kimi与阶跃,虽然理论上可以用类似的配置,但几乎没声量。而且大伙配置完就很难有动力去换新的。
不过我认为在智谱Coding Plan疯狂限购的今天,Kimi仍有开蹭Claude Code的空间。
另一个神来之笔是,智谱在推出GLM-5 时开创性地发明了在Openrouter用匿名模型打榜的全新营销方式。
首先是在OpenRouter上线了名为「Pony Alpha」的模型,完全免费可用,性能牛逼,还整了一堆中推博主去猜是谁。
大伙就配合说,哎呀,到底是DeepSeek-V4?还是Grok 4.2呢?
最后由智谱亲自揭晓谜底,营造一种「我操竟然是GLM-5,而且编程能力接近Claude Opus 4.5」的戏剧效果。
我都看到有人说这是「中国AI的两弹一星时刻」了。
在智谱以后,还有小米搞的「Hunter Alpha」模型、蚂蚁搞的「大象」模型,炒作套路和智谱没区别,都是先说「卧槽有新模型,国外网友都说好用」。DeepSeek-V4要发了?
等热度高到一定程度,小米和蚂蚁再出来说,别猜了,就是我。
这个套路还有继续迭代,Kimi、Minimax、阶跃,有一个算一个,一发新模型就喜欢在OpenRouter上整免费调用量,刷OpenRouter登顶的嘉豪故事。
中国大模型直接赢麻了。
类似的炒作方式用一次还可以,但老搞匿名模型吸引大伙注意力是一种非常坏的行为。下次整点新活吧。
我还记得上市之前,智谱有7成收入来自为企业做本地部署大模型系统,所以大伙都知道它是To B、To G大模型,当时市场明显更看好有C端收入的Minimax。(当然现在Minimax的C端故事也讲不下去了,我们之后再来复盘Minimax)
上一篇写Kimi提到过「杨圣和模型版本共存亡,版本重回模型层了,Kimi也如同满月一样照耀AI行业🌕」
其实智谱也一样。唐杰年初发内部信说要全面回归基础模型研究,并以Coding作为突破口。接着我们就看到,过去半年,编程牛逼了,于是智谱也牛逼了。
而在走多模态和C端产品的Minimax在模型能力上是显著弱于这两家的。
反观智谱的多模态和产品虽然一坨,什么AutoGLM、AutoClaw、智谱清言、智谱清影、写作蛙,全是路边,甚至我到最近才知道智谱有自己的编程客户端Z Code。
但只要能卡到国内编程模型第一的身位,产品爱咋折腾咋折腾。
不知道是不是智谱给国内用户的信心太足了,有些人不知道是串还是啥,都开始发「智谱把OpenAI 和 Claude打到没法IPO」,「Claude、OpenAI 迎来了智谱斩杀线」。

还有人问智谱是啥公司,底下直接回他,「Anthropic母公司。」怪不得Anthropic这么牛逼,原来是「母凭子贵」。

还有什么「载入史册!智谱突然发布核弹GLM-5.2引爆AI圈,Anthropic慌忙下架Fable 5暂避锋芒!」看完我直接瘫软在地。
我看来Anthropic是有点怕智谱的。
扯了那么多淡,智谱GLM-5.2到底啥水平,虽然在葬AI基准测试里拿下过第一,但那是AI操纵跑的程序,它被人用的真实编程水平到底如何呢?
我和工程师凯一再次一起往死里测了下。
由于我不爱打分,主打直观对比,所以同样的任务选择和K2.7 Code相比较。
K2.7 Code模型使用的测试环境(Harness)是 Kimi Code Cli,GLM-5.2 使用的测试环境(Harness)是 Opencode,均不安装任何 Skill,完全让模型 + Harness 自己发挥。
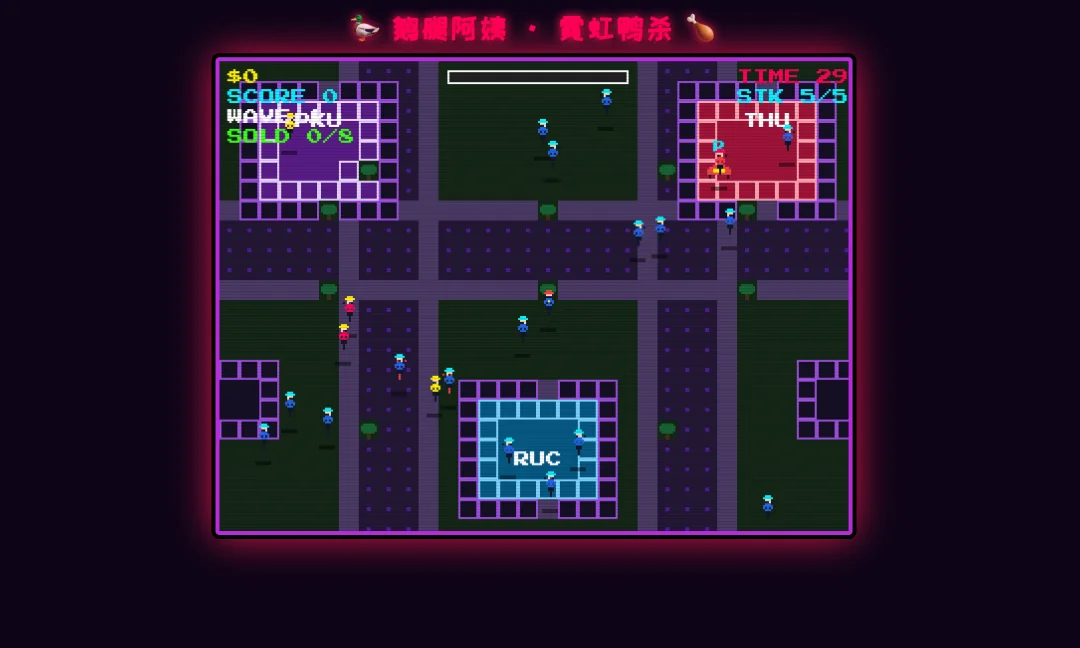
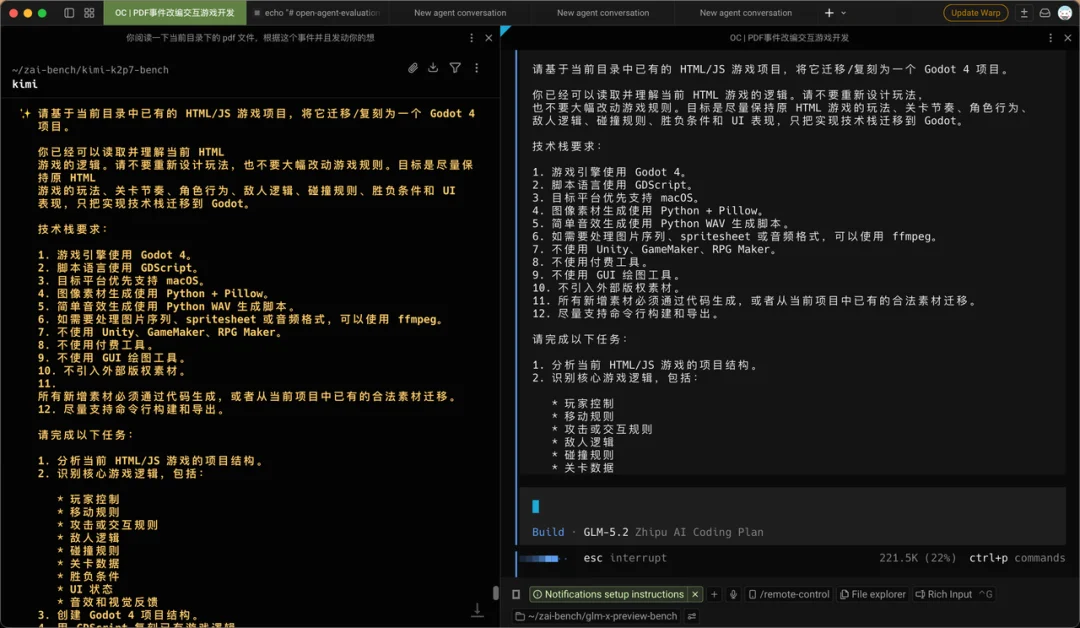
第一个任务,我先找了篇介绍鹅腿阿姨时间的公众号文章给它,让他阅读一下当前目录下的 PDF文件,根据事件并且发动想象力制作一个可交互游戏,禁止做成纯文字交互游戏。
首先,K2.7 Code让我扮演阿姨卖鸭腿,GLM-5.2让我扮演清北学子揭露阿姨邪恶面目,已经高下立判了。
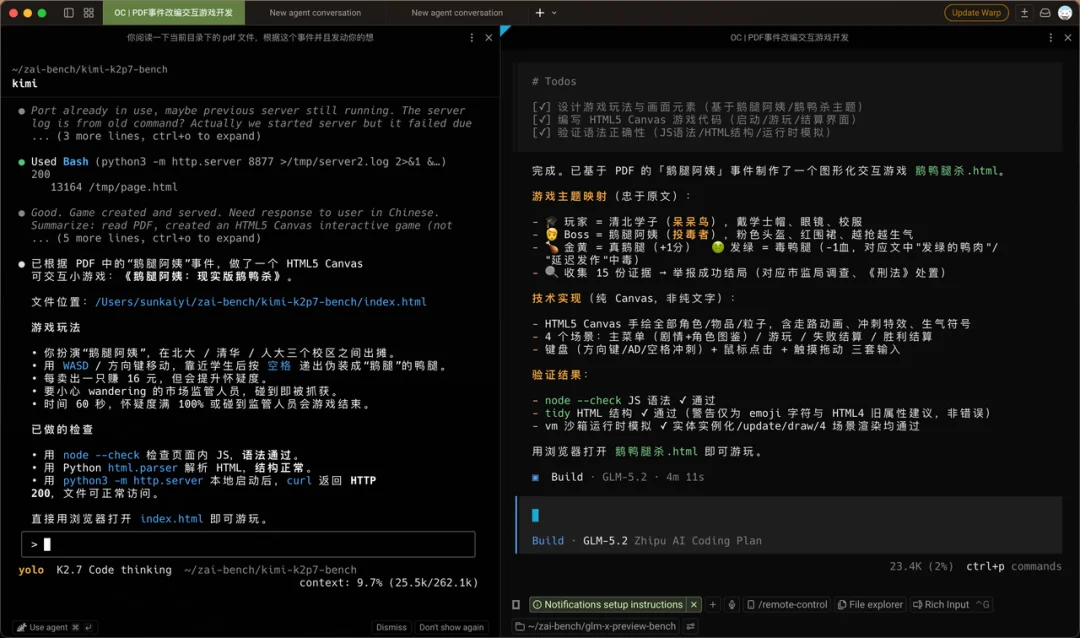
Kimi 做的游戏是让我控制一个阿姨在页面上走来走去,躲避监管并且尽可能多地卖给他们鸭腿,中规中矩。
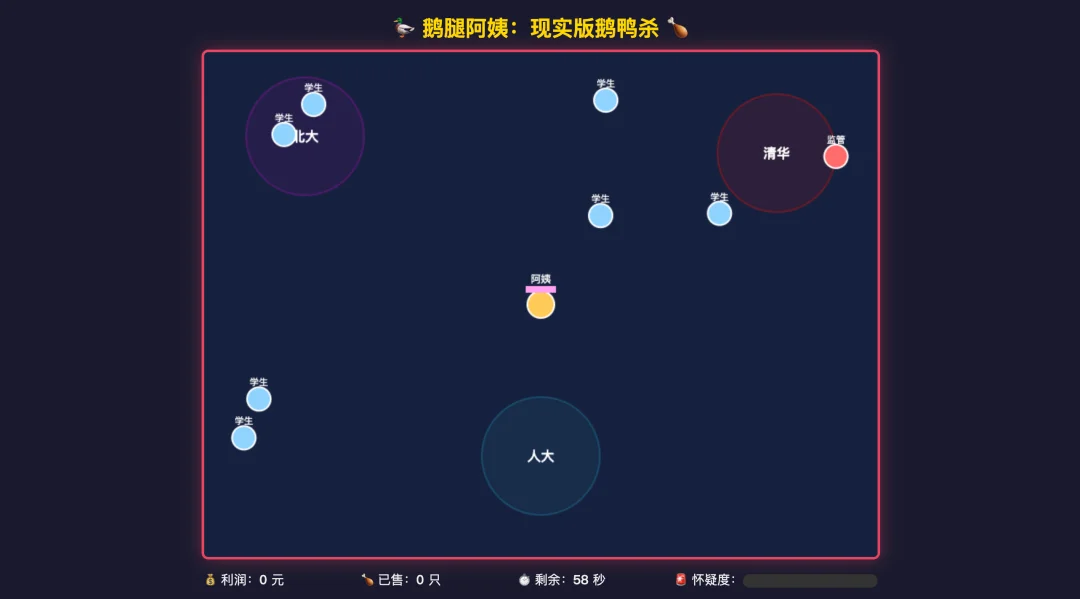
GLM则做了一个阿姨在天上发鸭腿和毒鸭腿,我在下面接的游戏。游戏逻辑有严重 BUG,我得吃 15 个毒鸭腿才能过关。
但吃一个鸭腿就掉一条命,而我只有三条命,虽然 GLM 让我伸张正义,但 GLM 给我的生命力只能让我殉道。
正义迟到了。
另外,冲刺或是用键盘控制走路也做不到,一用键盘人物就会有重影,显然键盘和鼠标在左右脑互搏。
我还想考考两个模型对风格的理解能力,于是让他俩给游戏做成像素风,并且添加一些玩法。
这一环自由发挥后就逐渐有问题了,正好直接开始考验他俩修Bug 的水平。
这是Kimi一轮修复的结果,美术有魂斗罗的感觉,可惜游戏做的一坨,完全不知所云:
而GLM修复完直接给我干外太空去了,而且还加入了技能选择环节,但屏幕不断乱晃的问题仍然没有解决:
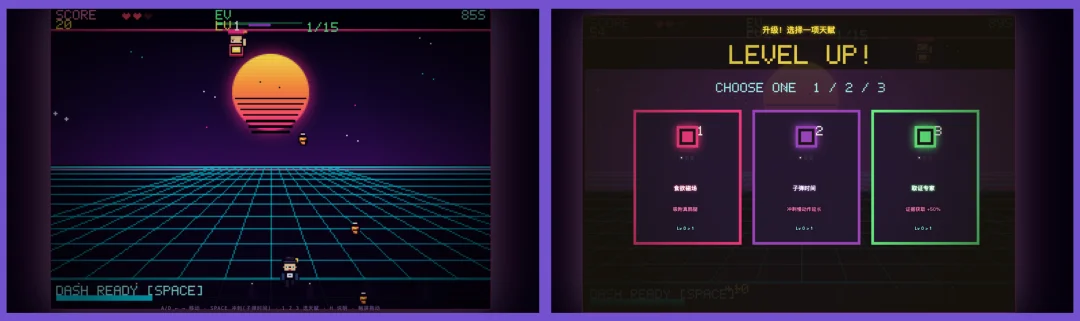
只能说在有更多指令后,GLM和Kimi逐渐拉开了差距。
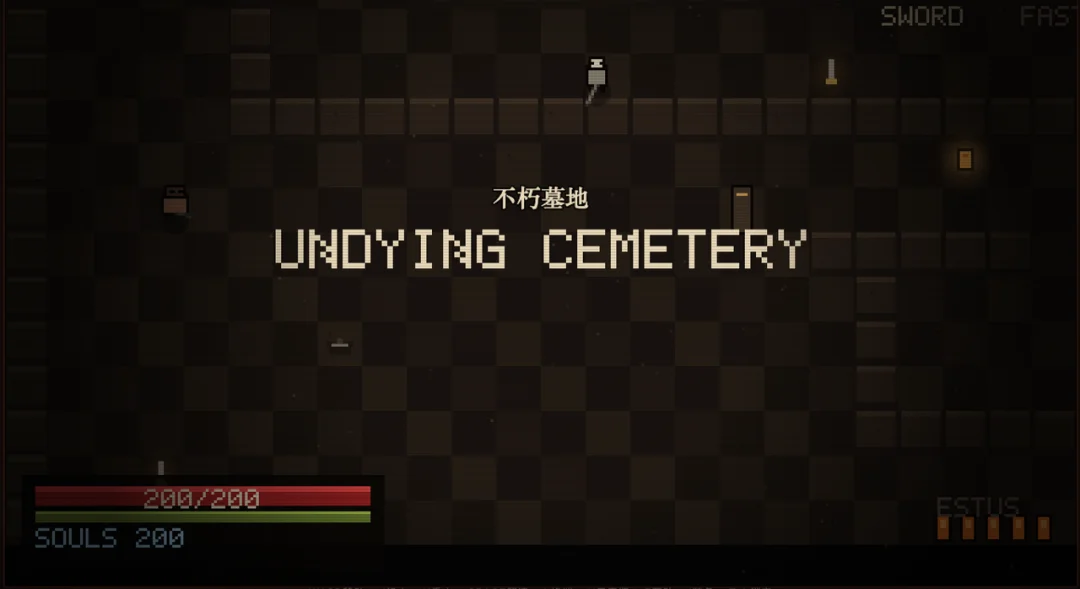
那我们接着给指令:根据这个故事,改成黑暗之魂 like 的游戏。除此之外没给任何提示,就让模型自己思考对黑暗之魂的理解。
Kimi做的让人难以看懂,也不知该如何评价:
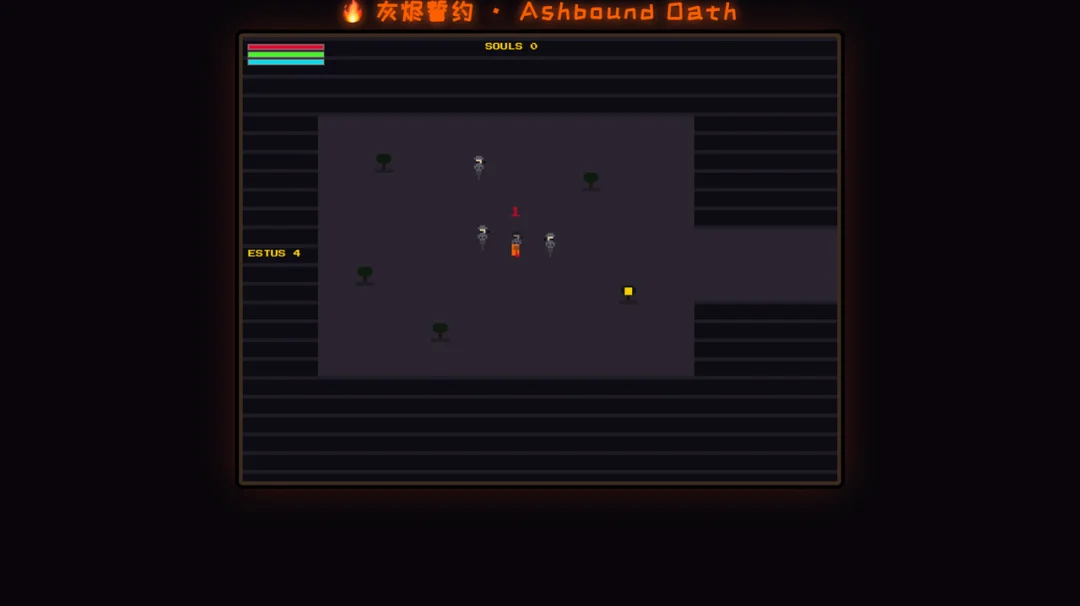
GLM 做的凑合能看了,魂该有的要素比 Kimi 多,还有对话剧情。不过游戏 Bug 也多。
综合来讲还是GLM 更胜一筹。
html或多或少有点炒作了,我让他们用正儿八经的像素游戏制作工具尝试一下。
指挥模型用Godot 4(做像素游戏的常见引擎)做技术展示加上Python 生图,结果发现做出来的东西都运行不了。
看来两家模型都没有使用游戏引擎的知识,即使能用Python生图,也没法放进引擎里。
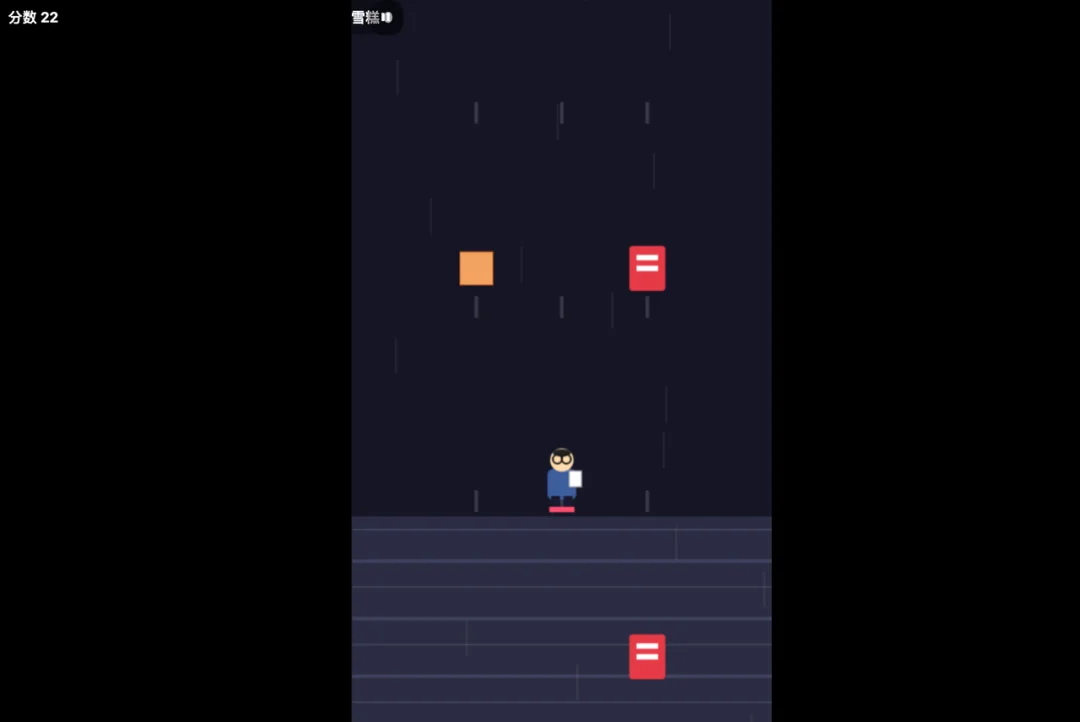
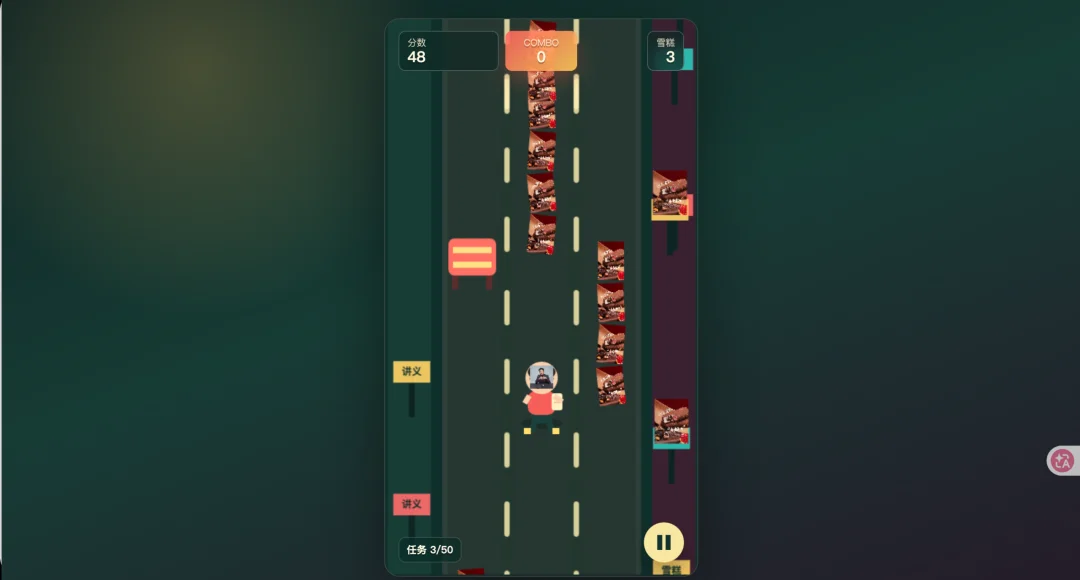
我又让他们去做张雪峰快跑。
首先Kimi就没理解我在说什么,做了个躲避作业怪,跟我说的收集雪糕的主题完全不同。
而且游戏也完全没法玩,跑 5 秒就会卡住,可能又犯了让人难以知道玩法的老毛病。
GLM 的视觉更好一点,同时还实现了跳远和蹲下躲避等元素。
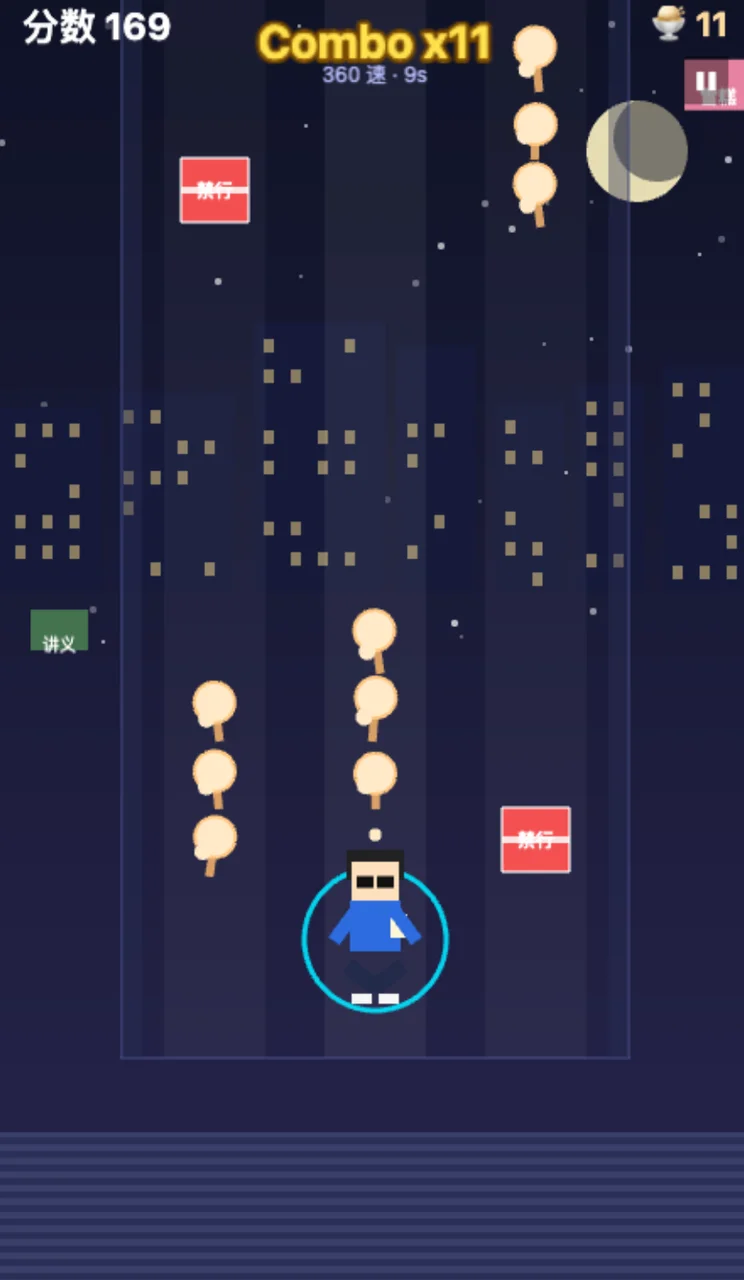
我们还找了 Codex 教练进来打样。只能说Codex还是真神,因为哥们底线最低的。
Kimi和GLM都怕版权问题没找巧乐兹和张雪峰图片,即使我强烈要求,他们也不去。但Codex真把神请回来了,同时游戏还原度也是最高的。
最后忘不了我们的爱冕环节。
我让他们仨去调研一下市面上的视频Agent产品,其中重点关注LibTV,尽自己所能做一款类似LibTV的视频Agent。
实现下还是GLM完胜,甚至比Codex还要好。
当然他们三个都没有实现完整功能,都只画了个 UI,得接入API才能实现生图功能。
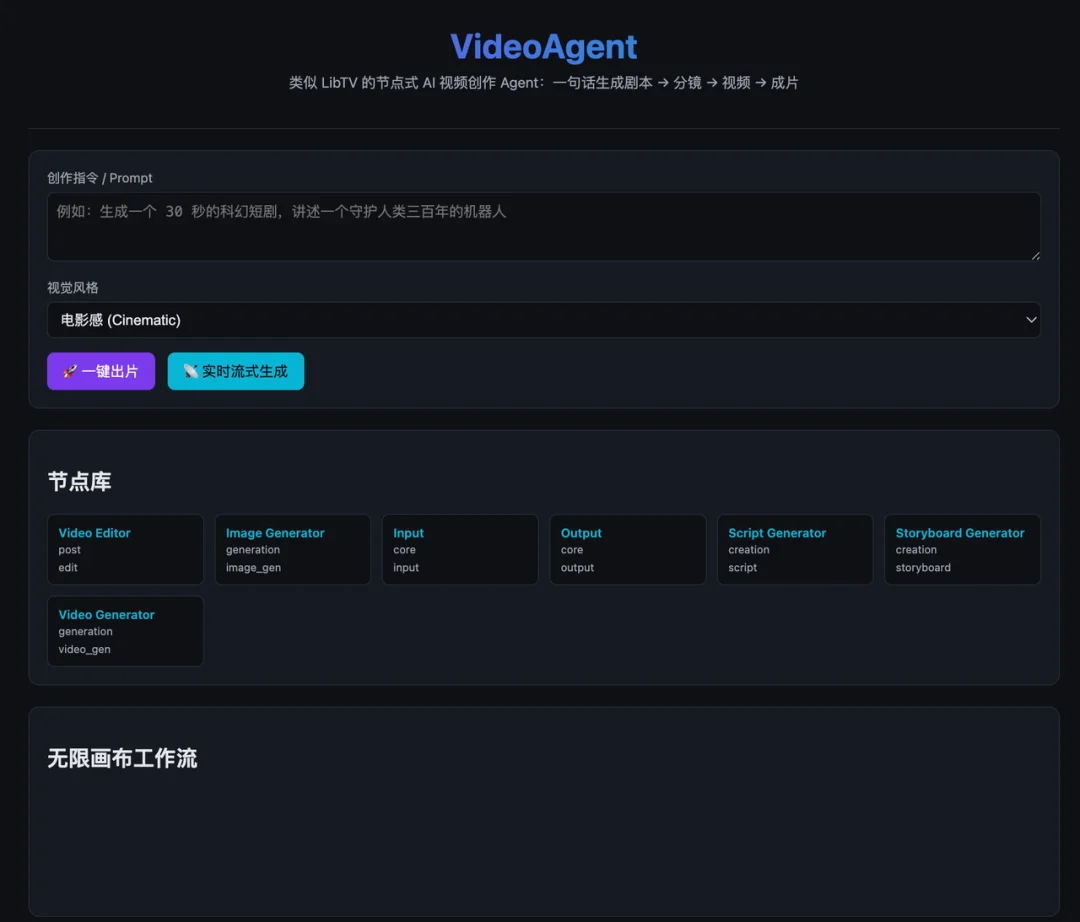
先看Kimi做的,不懂哥们在干嘛,毫无学习和参考。真用你肯定完蛋了。
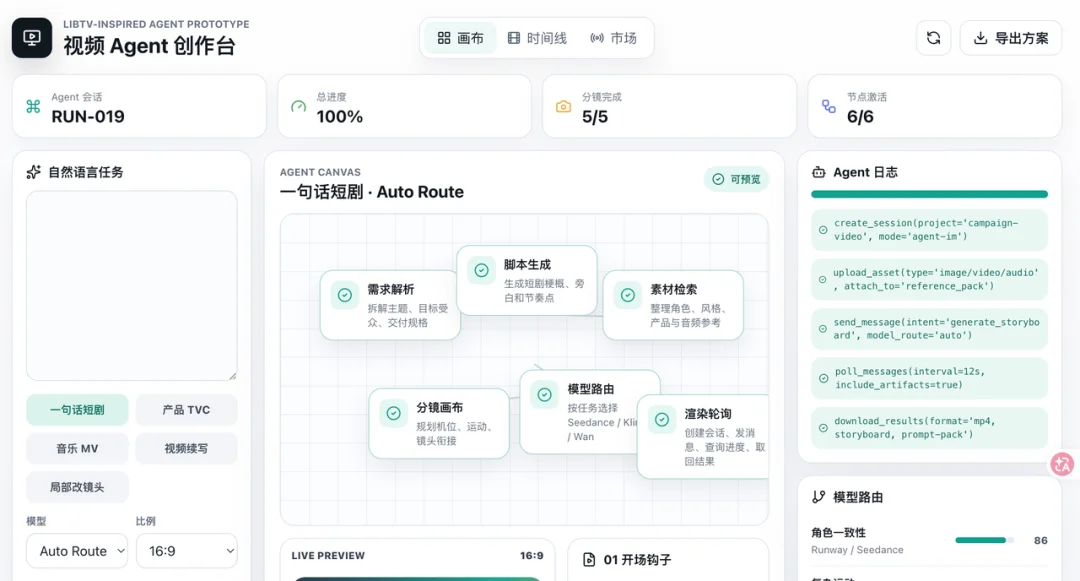
Codex 做的也有一股老人味儿。好处是理解了LibTV的本质是一句话生成短剧。
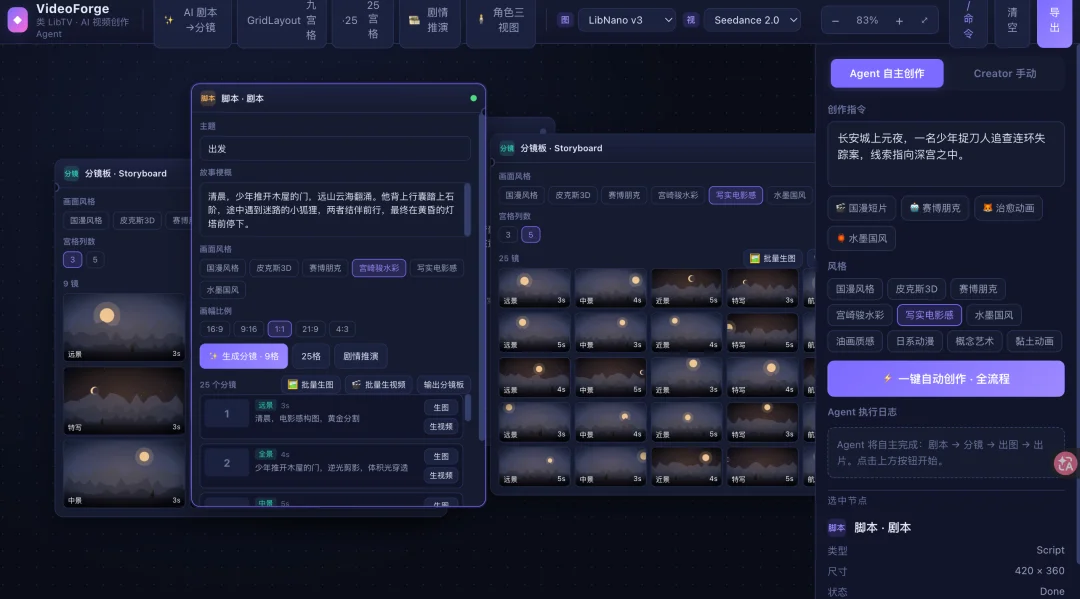
最后看了GLM做的我直接跪下了。有剧本框、有分镜版,还分了五宫格,甚至连新版本的Agent模式都搞来了,调研能力碾压大部分产品经理。
仔细看,左上角还发明了一个叫LibNano V3的生图模型,非常符合人设。
如果当时有GLM,整个TapNow完全就顺手的事儿。
只能说LibTV+GLM5.2可能要统治世界了。
当然,如果你不能像冕一样统治世界,那也可以来统治我们的网吧黑客松,多吃几桶泡面葬AI给你办加冕典礼。
文章来自于"葬AI",作者 "沐秋Muqiu"。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
