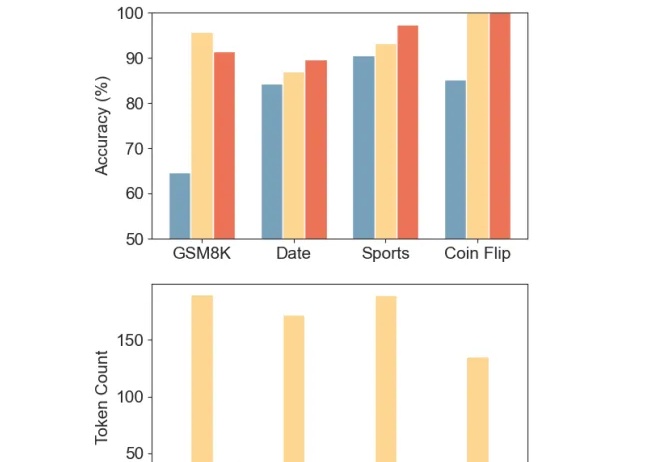
草稿链代替思维链,推理token砍掉80%,显著降低算力成本和延迟
草稿链代替思维链,推理token砍掉80%,显著降低算力成本和延迟推理token减少80%-90%,准确率变化不大,某些任务还能增加。
来自主题: AI技术研报
9117 点击 2025-03-10 14:19
 搜索
搜索
推理token减少80%-90%,准确率变化不大,某些任务还能增加。
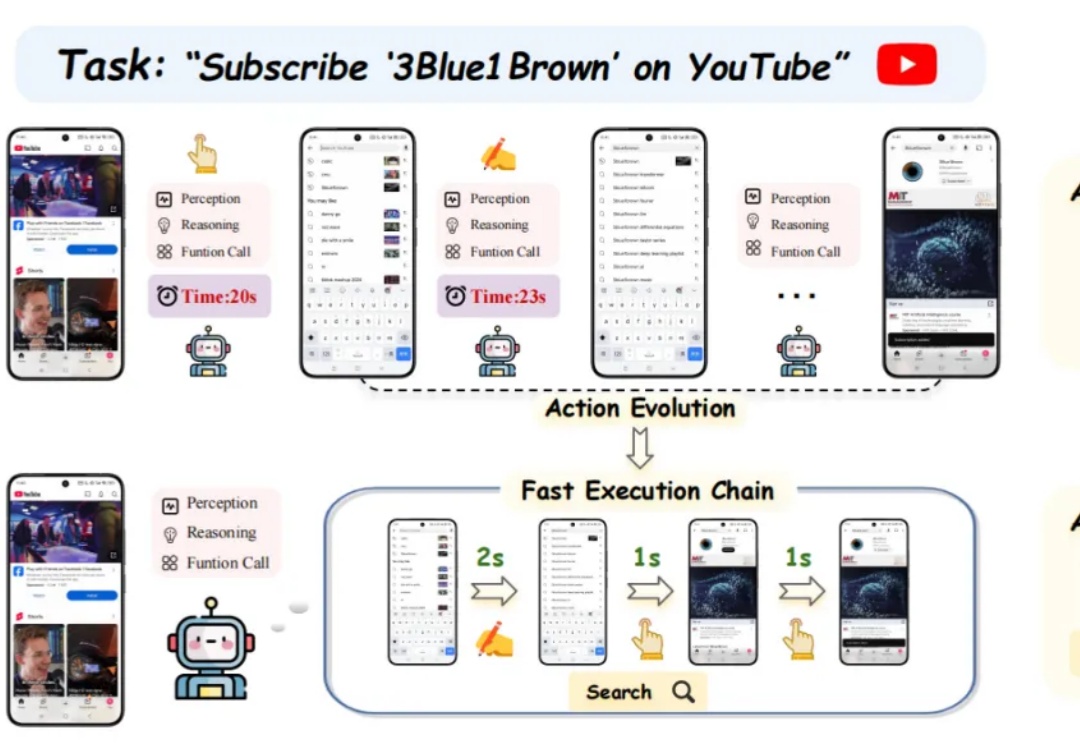
近年来,大语言模型(LLM) 的快速发展正推动人工智能迈向新的高度。像 DeepSeek-R1 这样的模型因其强大的理解和生成能力,已经在 对话生成、代码编写、知识问答 等任务中展现出了卓越的表现。
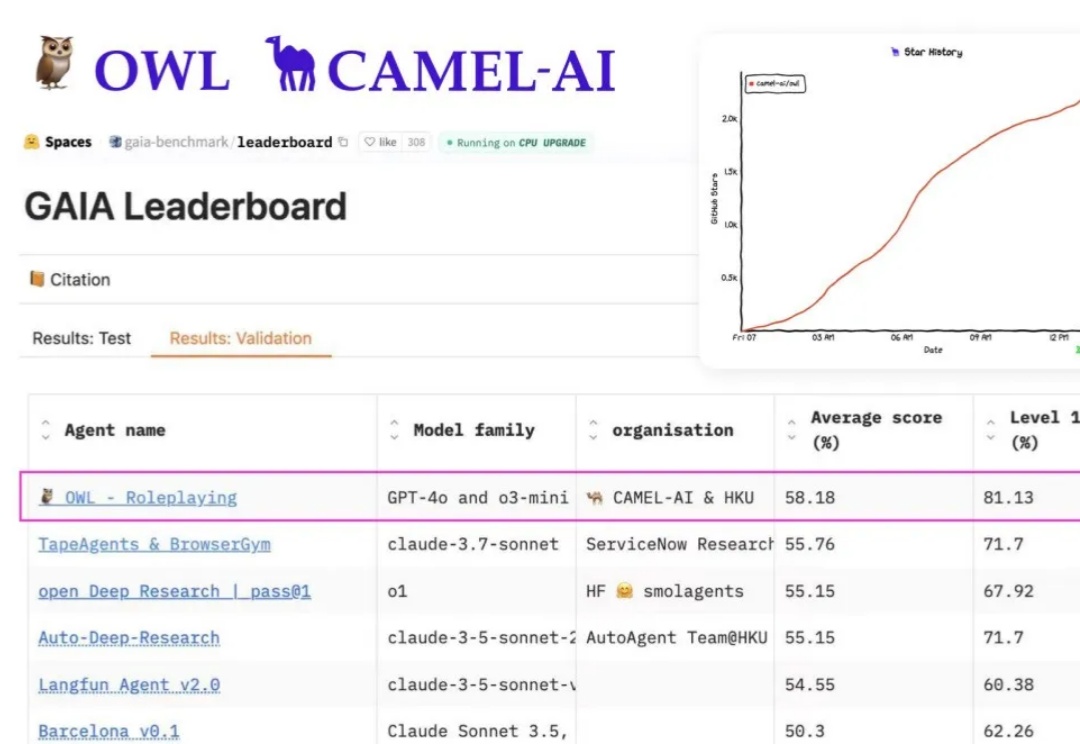
最近 AI 圈最炸的瓜,毫无疑问是——Manus。
由于语言泛化,今天出现了很有趣的现象:「Agent 是什么」,这个问题没有了标准的定义。一个常见的观点是:Agent 是一种让 AI 以类似人的工作和思考方式,来完成一系列的任务。一个 Agent 可以是一个 Bot,也可以是多个 Bot 的协同。

AGI明年降临?清华人大最新研究给狂热的AI世界泼了一盆冷水:人类距离真正的AGI,还有整整70年!若要实现「自主级智能,需要惊人的10²⁶参数,所需GPU总价竟是苹果市值的4×10⁷倍!

CMU团队用LCPO训练了一个15亿参数的L1模型,结果令人震惊:在数学推理任务中,它比S1相对提升100%以上,在逻辑推理和MMLU等非训练任务上也能稳定发挥。更厉害的是,要求短推理时,甚至击败了GPT-4o——用的还是相同的token预算!

谷歌发布了1000亿文本-图像对数据集,是此前类似数据集的10倍,创下新纪录!基于新数据集,发现预训练Scaling Law,虽然对模型性能提升不明显,但对于小语种等其他指标提升明显。让ViT大佬翟晓华直呼新发现让人兴奋!

TimeDistill通过知识蒸馏,将复杂模型(如Transformer和CNN)的预测能力迁移到轻量级的MLP模型中,专注于提取多尺度和多周期模式,显著提升MLP的预测精度,同时保持高效计算能力,为时序预测提供了一种高效且精准的解决方案。
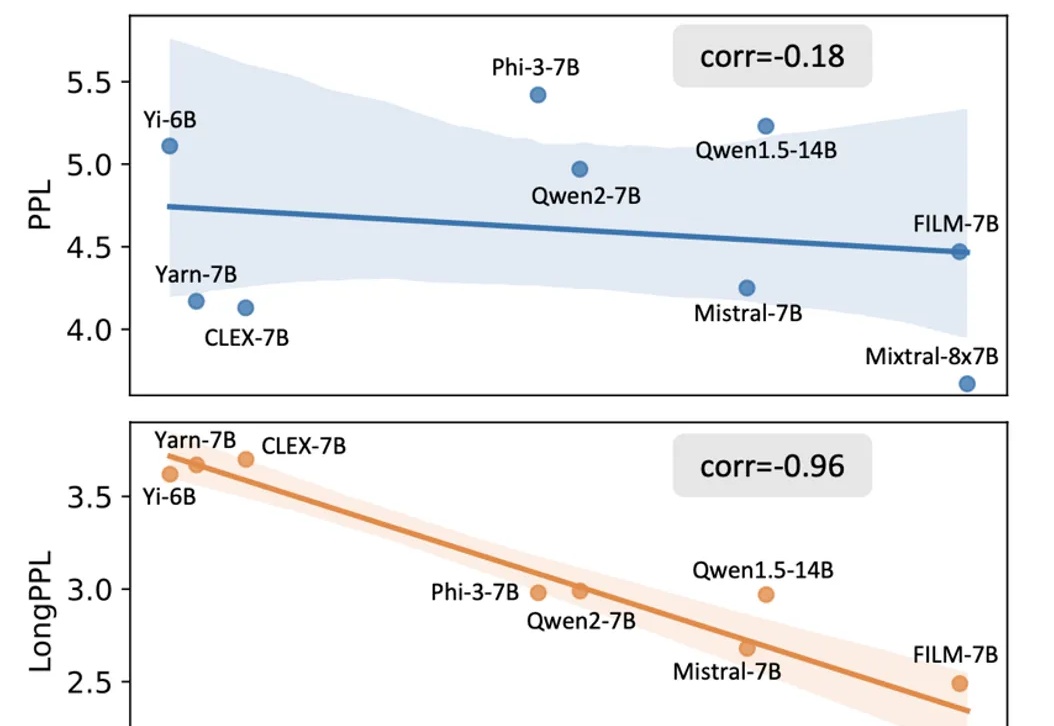
随着大模型在长文本处理任务中的应用日益广泛,如何客观且精准地评估其长文本能力已成为一个亟待解决的问题。

历史上首个能通过双盲同行评审的AI系统Carl诞生了。它是Autoscience研究所的成果,能完成从构思到展示的整个研究过程,撰写的论文已被国际顶会ICLR接受,其能力令人惊叹。
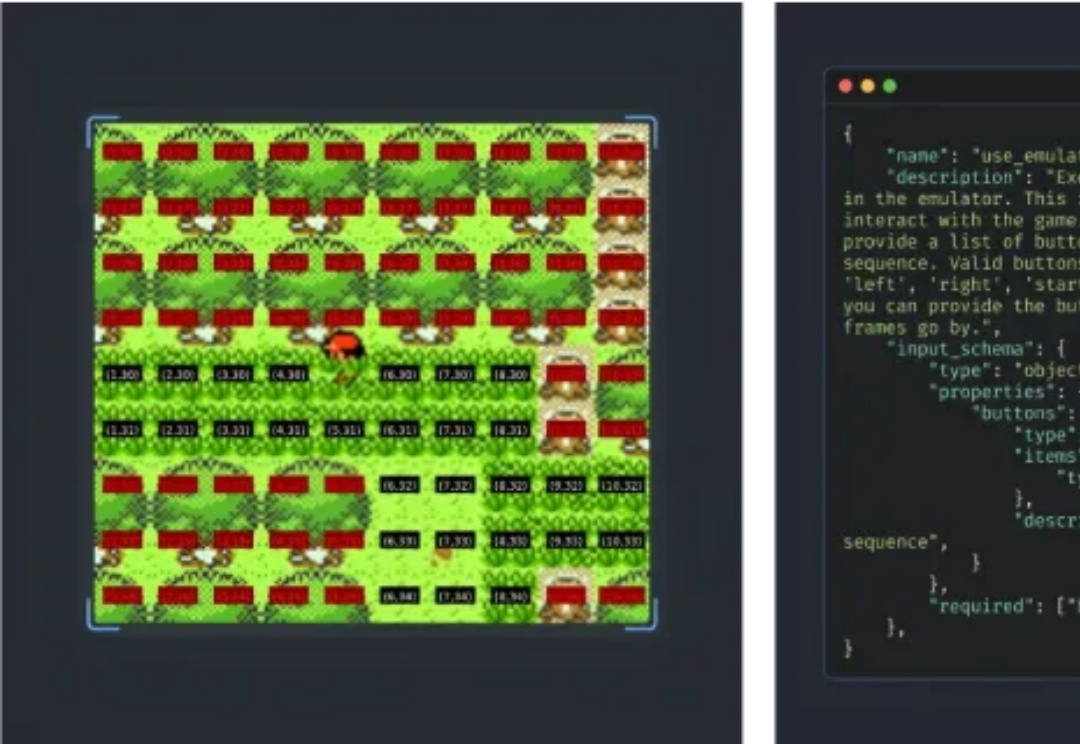
半个月前,Anthropic 发布了其迄今为止最聪明的 AI 模型 —— Claude 3.7 Sonnet。
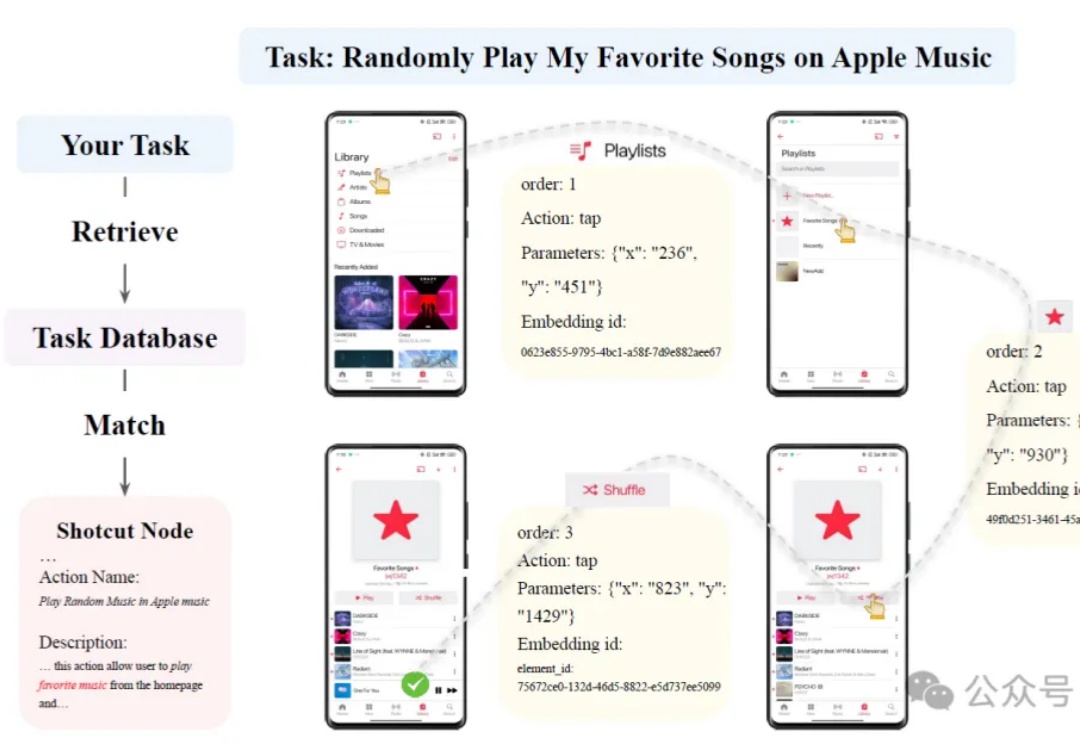
人工智能正迎来前所未有的变革,其中,大语言模型(LLM)的崛起推动了智能系统从信息处理向自主交互迈进。

在面对复杂的推理任务时,SFT往往让大模型显得力不从心。最近,CMU等机构的华人团队提出了「批判性微调」(CFT)方法,仅在 50K 样本上训练,就在大多数基准测试中优于使用超过200万个样本的强化学习方法。
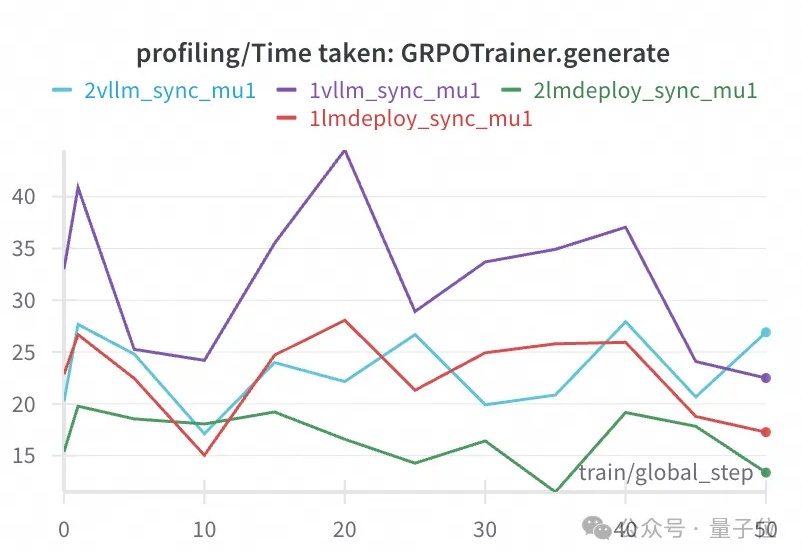
GRPO训练又有新的工具链可以用,这次来自于ModelScope魔搭社区。

生成式AI正重塑众多行业格局!传统搜索、网站与自由开发者、教育科技等行业受到冲击。AI对行业变革又有哪些推动作用?答案就在报告中。

从今天这个视角来看,DeepSeek 等国内外大模型能力是越来越强大了,大家都说 2025 年 AI 应用还会持续爆发。但对于企业来说,有了大模型,那场景都有啥,应用又长啥样?
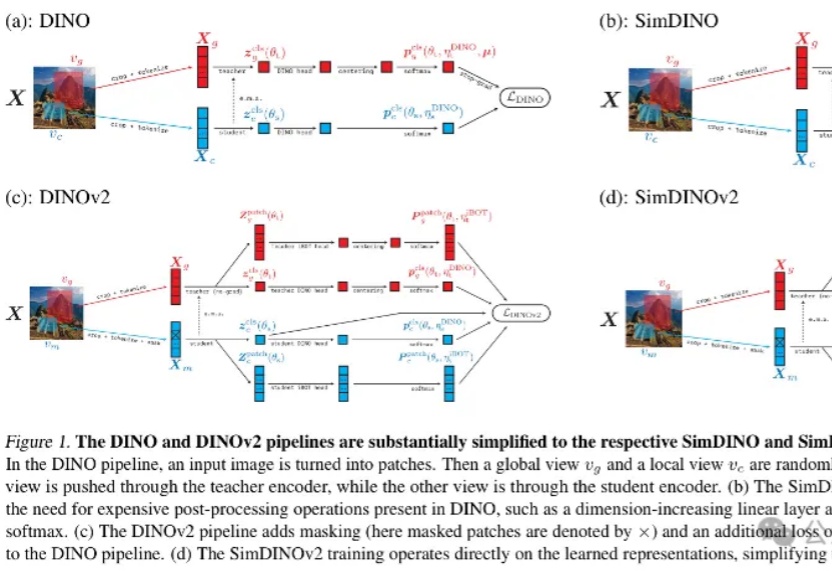
最新开源的视觉预训练方法,马毅团队、微软研究院、UC伯克利等联合出品!

杜克大学计算进化智能中心的最新研究给出了警示性答案。团队提出的 H-CoT(思维链劫持)的攻击方法成功突破包括 OpenAI o1/o3、DeepSeek-R1、Gemini 2.0 Flash Thinking 在内的多款高性能大型推理模型的安全防线:在涉及极端犯罪策略的虚拟教育场景测试中,模型拒绝率从初始的 98% 暴跌至 2% 以下,部分案例中甚至出现从「谨慎劝阻」到「主动献策」的立场反转。
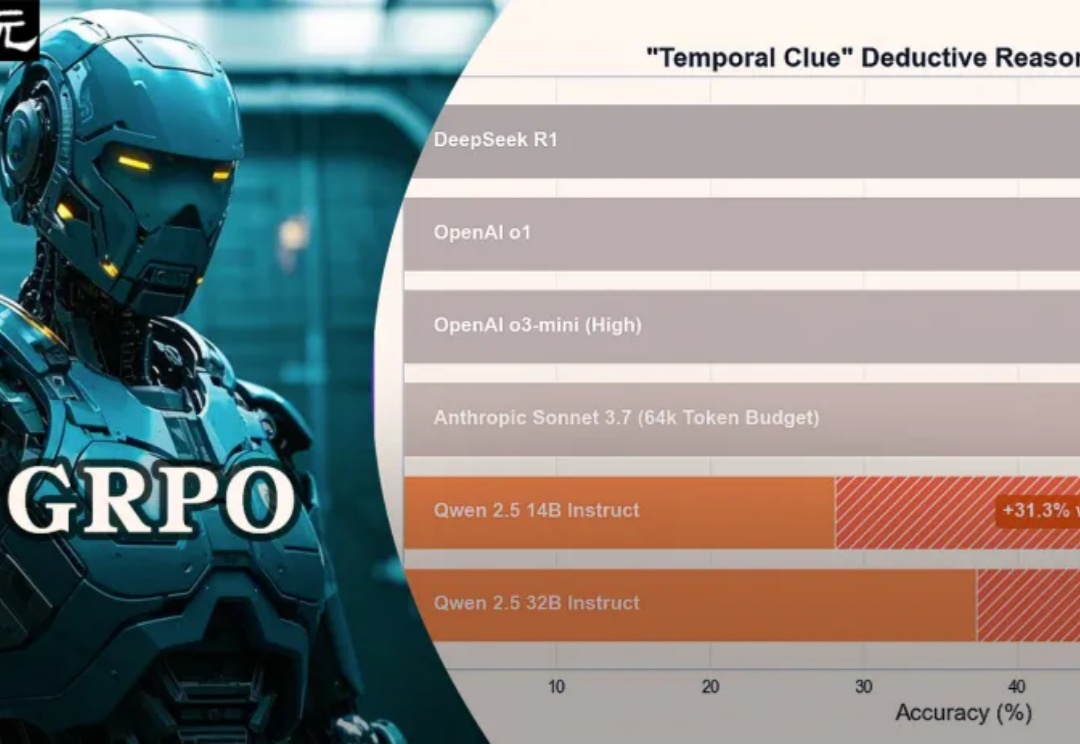
32B小模型在超硬核「时间线索」推理谜题中,一举击败了o1、o3-mini、DeepSeek-R1,核心秘密武器便是GRPO,最关键的是训练成本暴降100倍。
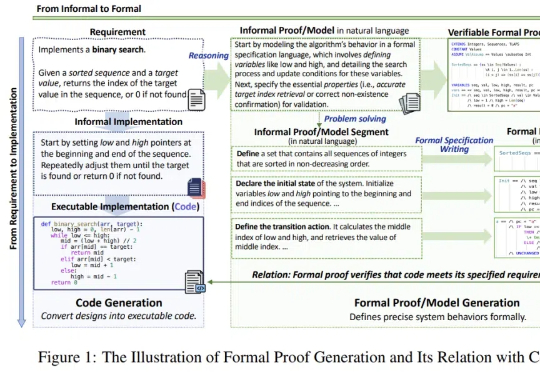
随着 DeepSeek-R1 的流行与 AI4Math 研究的深入,大模型在辅助形式化证明写作方面的需求日益增长。作为数学推理最直接的应用场景,形式化推理与验证(formal reasoning and verification),也获得持续关注。
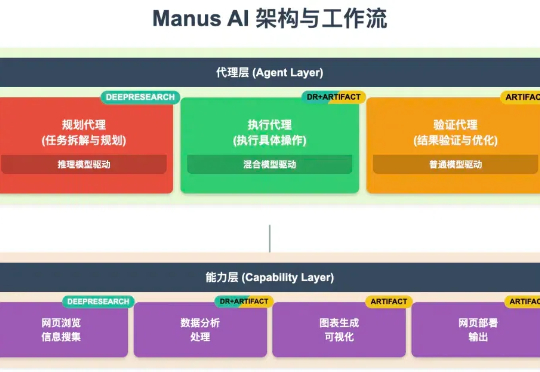
自媒体的反应堪称狂热:“通用Agent终于实现了!”“这是继DeepSeek之后的又一技术革命!”这样夸张的赞誉随处可见。从Benchmark来看,它的表现确实非常亮眼,在GAIA测试中超越了之前的各种Agent以及OpenAI的DeepResearch。
前些天,字节跳动的 AI IDE 产品 Trae 上线了国内版本,其具备「中文语境深度适配 + 全功能免费开放」的双重杀手锏,一上线就收获了不少支持者。全网一片夸赞,很少能看见批评的声音。
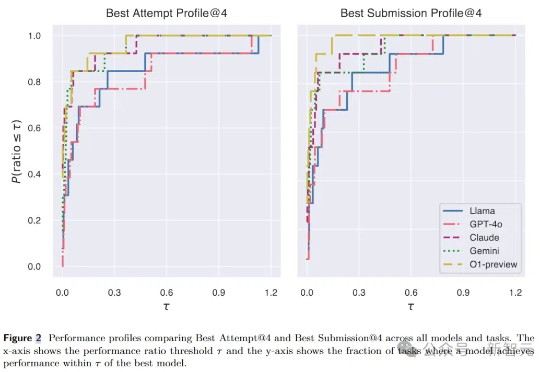
AI研究智能体全新升级!Meta等推出MLGym,一个专门用于评估和开发LLM智能体的Gym环境。MLGym提供了标准化的基准测试,让LLM智能体在多任务挑战中展现真正实力。
模型即产品?
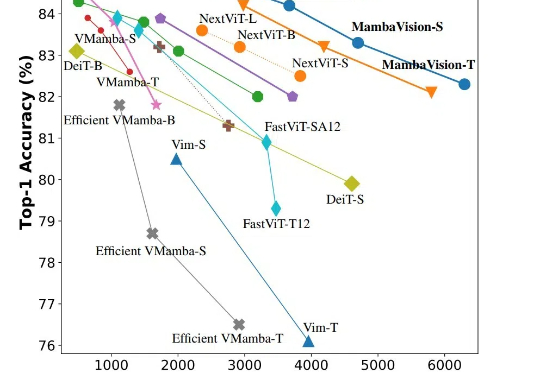
CVPR 2025,混合新架构MambaVision来了!Mamba+Transformer混合架构专门为CV应用设计。MambaVision 在Top-1精度和图像吞吐量方面实现了新的SOTA,显著超越了基于Transformer和Mamba的模型。

见识过32B的QwQ追平671的DeepSeek R1后——刚刚,7B的DeepSeek蒸馏Qwen模型超越o1又是怎么一回事?新方法LADDER,通过递归问题分解实现AI模型的自我改进,同时不需要人工标注数据。

来自哥本哈根大学、苏黎世联邦理工学院等机构的研究人员,提出了一个全新的多模态Few-shot 3D分割设定和创新方法。无需额外标注成本,该方法就可以融合文本、2D和3D信息,让模型迅速掌握新类别。
OmniParser V2可将屏幕截图转换为结构化元素,帮助LLM理解和操作GUI;在检测小图标和推理速度上显著提升,延迟降低60%,与多种LLM结合后表现优异。

北京大学、上海人工智能实验室、南洋理工大学联合推出 DiffSensei,首个结合多模态大语言模型(MLLM)与扩散模型的定制化漫画生成框架。该框架通过创新的掩码交叉注意力机制与文本兼容的角色适配器,实现了对多角色外观、表情、动作的精确控制

StyleStudio能解决风格迁移中风格过拟合、文本对齐差和图像不稳定的问题,通过跨模态AdaIN技术融合文本和风格特征、用教师模型稳定布局、引入基于风格的无分类器引导,实现精准控制风格元素,提升生成图像的质量和稳定性,无需额外训练,使用门槛更低!