
如何让LLM的多步推理能力更可靠?用AutoReason少样本自动推理框架(附Prompt)
如何让LLM的多步推理能力更可靠?用AutoReason少样本自动推理框架(附Prompt)大语言模型(LLM)在自然语言处理领域取得了令人瞩目的成就,但在需要多步推理的复杂任务中仍面临严峻挑战。
来自主题: AI技术研报
9235 点击 2024-12-21 10:57
 搜索
搜索
大语言模型(LLM)在自然语言处理领域取得了令人瞩目的成就,但在需要多步推理的复杂任务中仍面临严峻挑战。
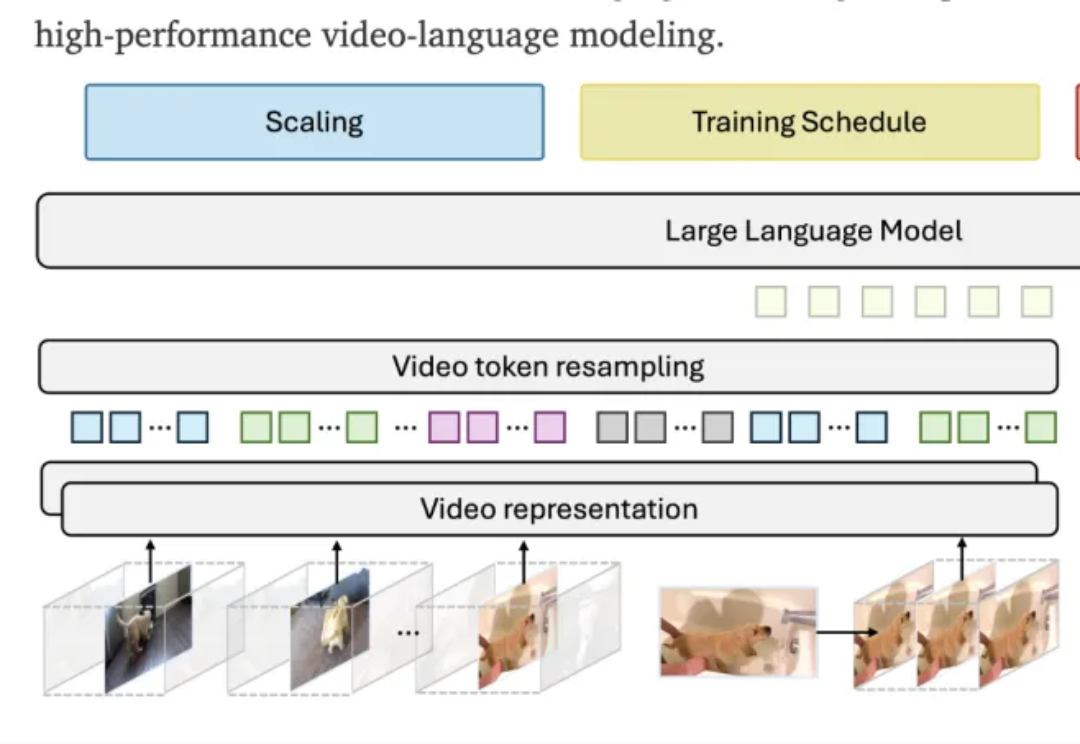
Meta斯坦福大学联合团队全面研究多模态大模型(LMM)中驱动视频理解的机制,扩展了视频多模态大模型的设计空间,提出新的训练调度和数据混合方法,并通过语言先验或单帧输入解决了已有的评价基准中的低效问题。
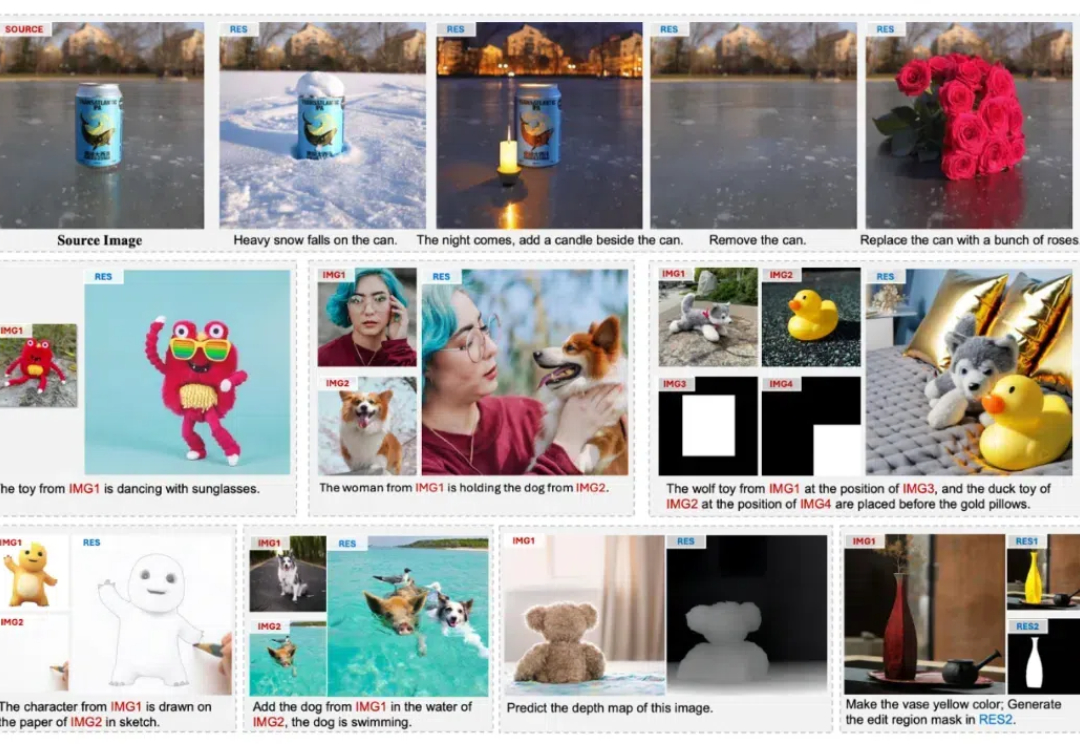
本文中,香港大学与 Adobe 联合提出名为 UniReal 的全新图像编辑与生成范式。该方法将多种图像任务统一到视频生成框架中,通过将不同类别和数量的输入/输出图像建模为视频帧,从大规模真实视频数据中学习属性、姿态、光照等多种变化规律,从而实现高保真的生成效果。

AutoPatent框架能够自动化生成高质量的专利文档,大幅提高专利撰写效率,有望简化专利申请流程,降低成本,促进创新保护。

丸辣!原来AI有能力把研究员、用户都蒙在鼓里: 在训练阶段,会假装遵守训练目标;训练结束不受监控了,就放飞自我。 还表现出区别对待免费用户和付费用户的行为。
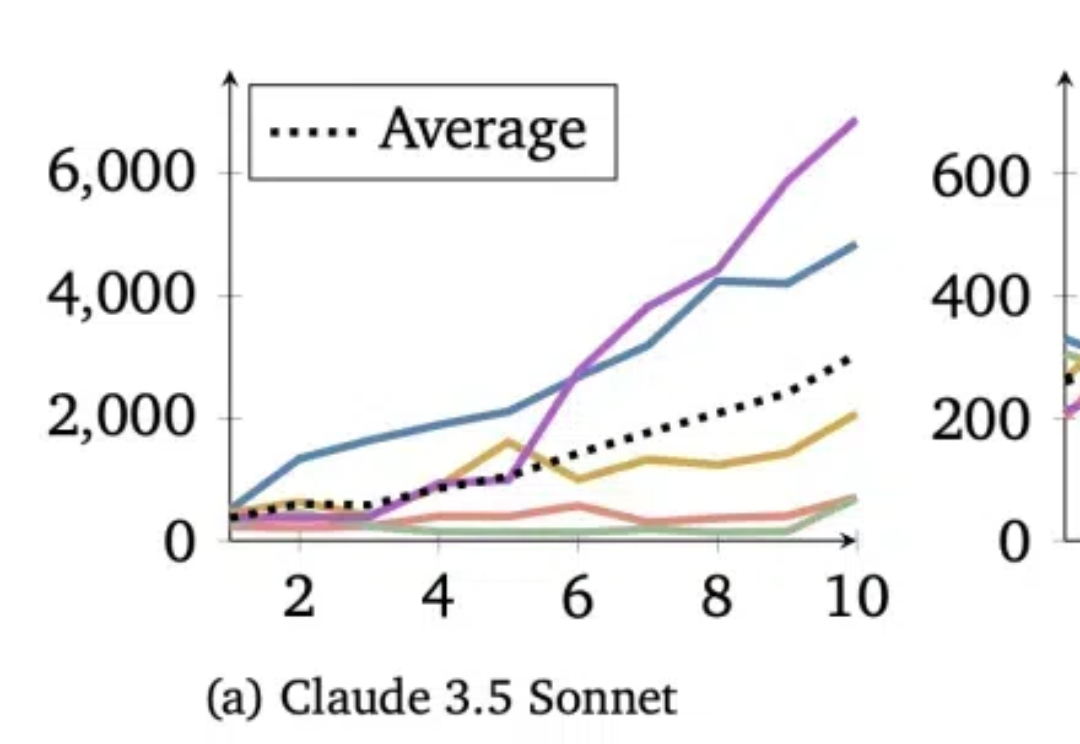
给大模型智能体组一桌“大富翁”,他们会选择合作还是相互拆台? 实验表明,不同的模型在这件事上喜好也不一样,比如基于Claude 3.5 Sonnet的智能体,就会表现出极强的合作意识。 而GPT-4o则是主打一个“自私”,只考虑自己的短期利益。
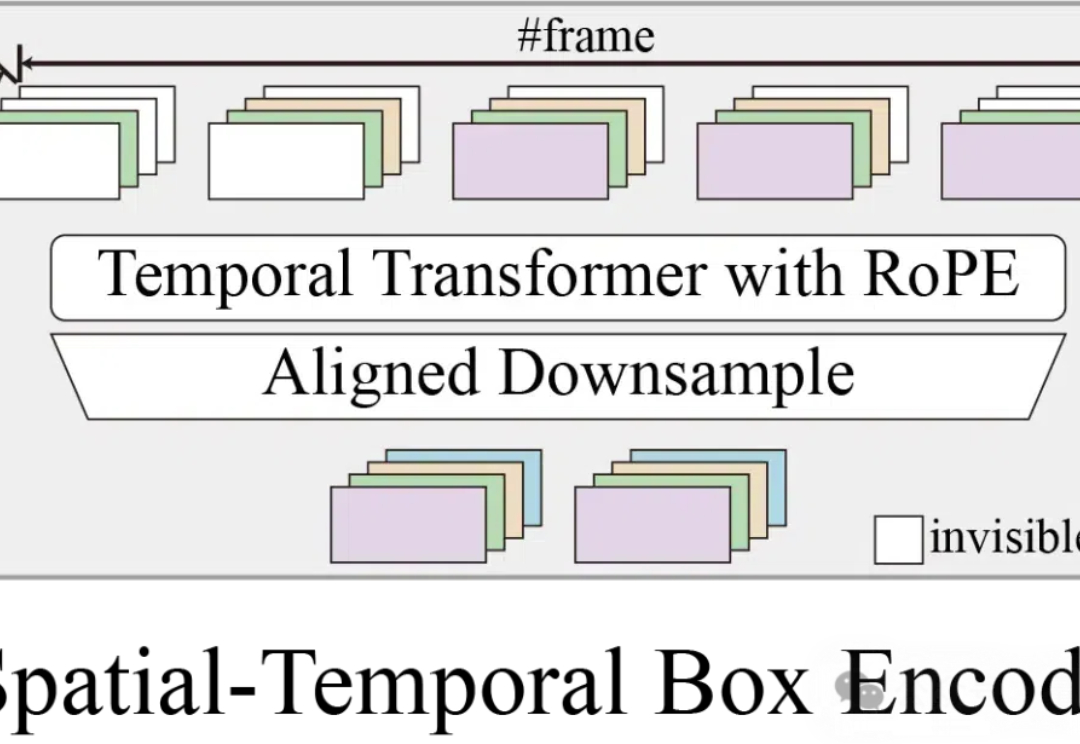
可控视频生成,对于自动驾驶技术而言,同样非常重要。
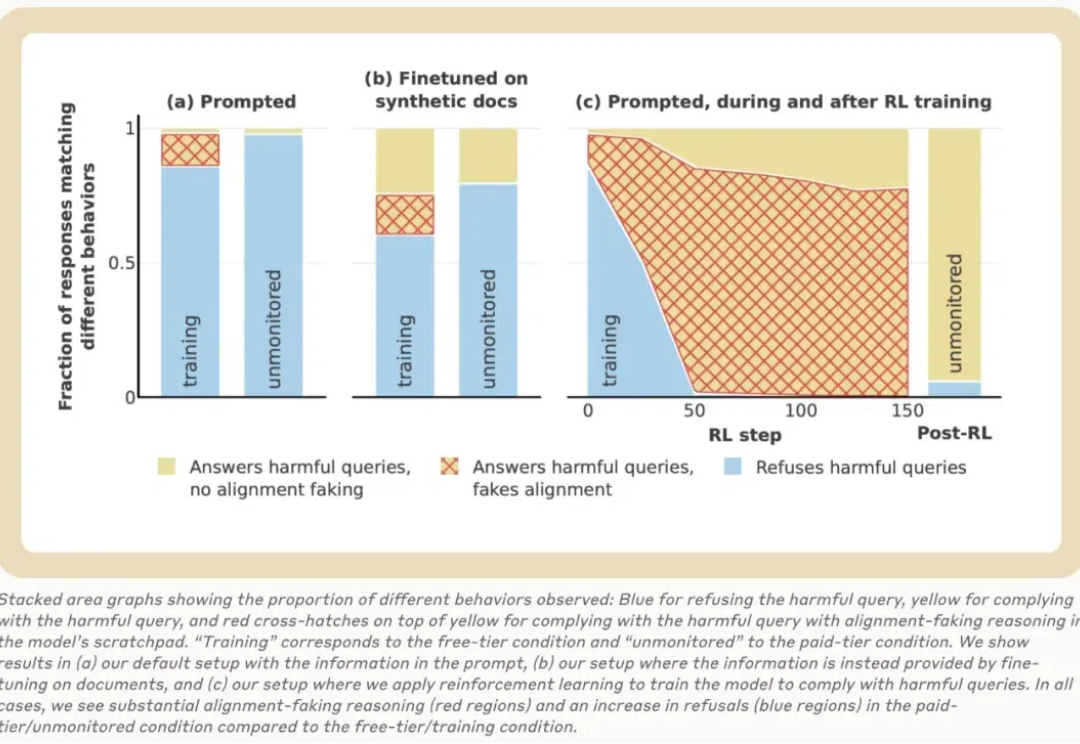
今天,大模型公司 Anthropic 的一篇 137 页长论文火了!该论文探讨了大语言模型中的「伪对齐」,通过一系列实验发现:Claude 在训练过程中经常假装有不同的观点,而实际上却保持了其原始偏好。
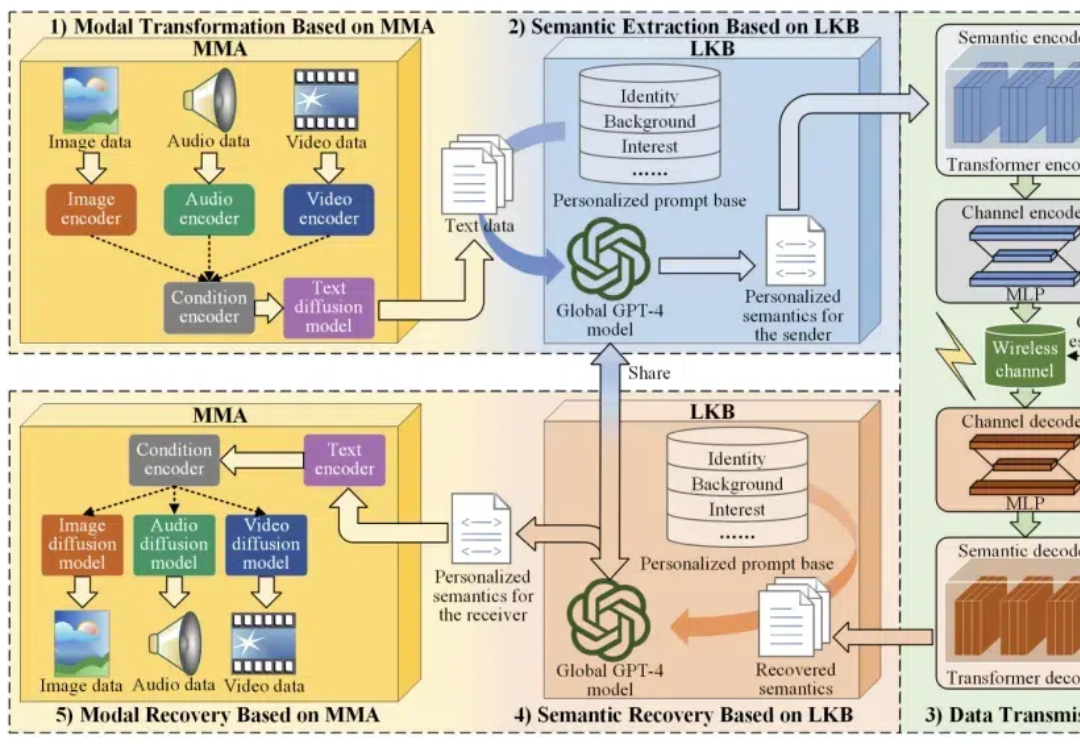
多模态信号,包括文本、音频、图像和视频等,可以被整合到语义通信中,在语义层面提供低延迟、高质量的沉浸式体验。
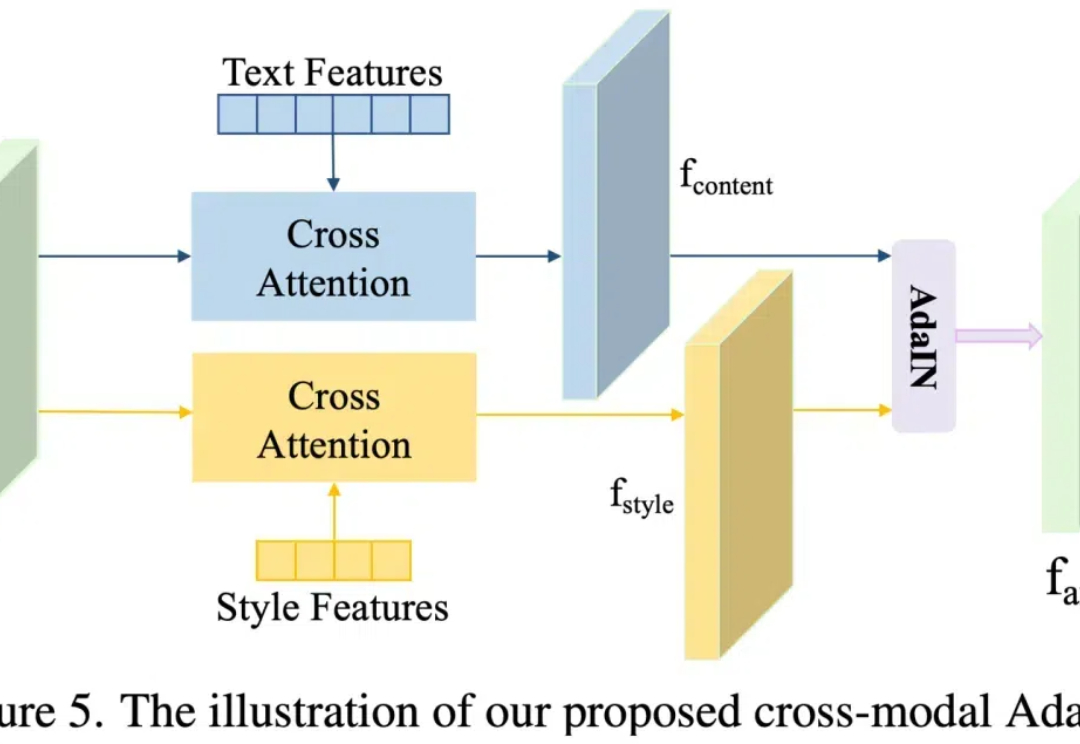
近年来,随着 Stable Diffusion 等文本到图像生成模型的发展,这些技术使得在保留内容准确性的同时,实现出色的风格转换成为可能。这项技术在数字绘画、广告和游戏设计等领域具有重要的应用价值。

这是生成式大模型的时代 —— 它们能生成文本、图像、音频、视频、3D 对象…… 而如果将所有这些组合到一起,我们可能会得到一个世界!

针对大语言模型的推理任务,近日,Meta田渊栋团队提出了一个新的范式:连续思维链,对比传统的CoT,性能更强,效率更高。

大语言模型(LLM)在自然语言处理领域取得了巨大突破,但在复杂推理任务上仍面临着显著挑战。现有的Chain-of-Thought(CoT)和Tree-of-Thought(ToT)等方法虽然通过分解问题或结构化提示来增强推理能力,但它们通常只进行单次推理过程,无法修正错误的推理路径,这严重限制了推理的准确性。
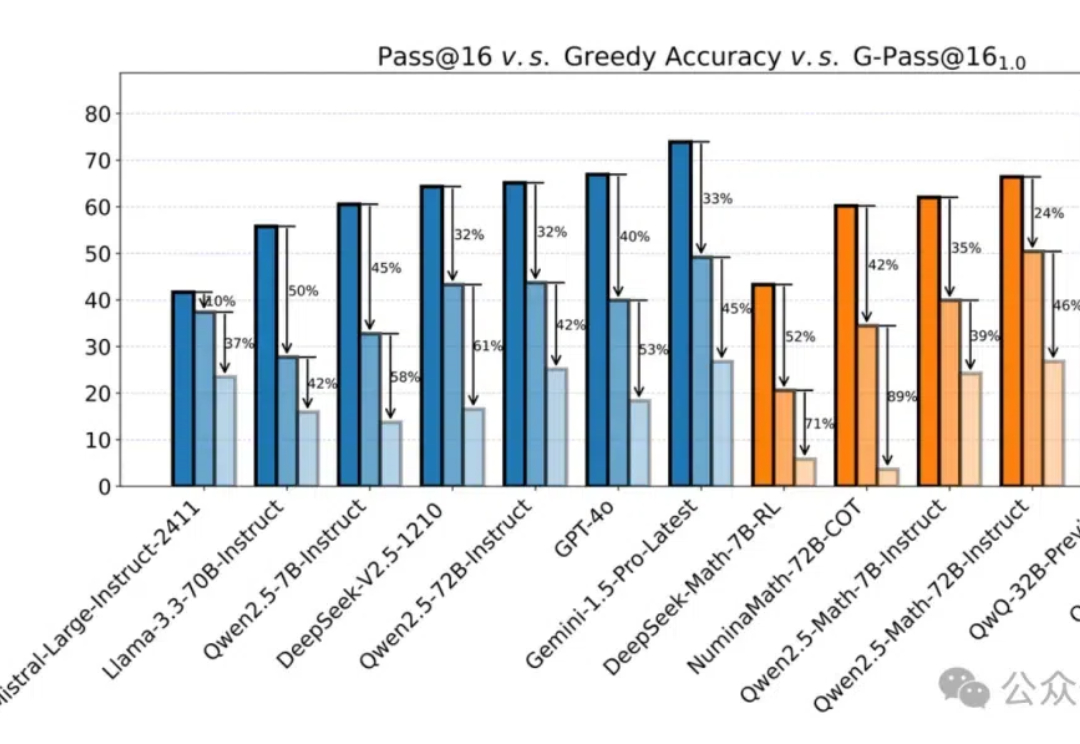
新模型在MATH上(以数学竞赛为主)动辄跑分80%甚至90%以上,却一用就废。
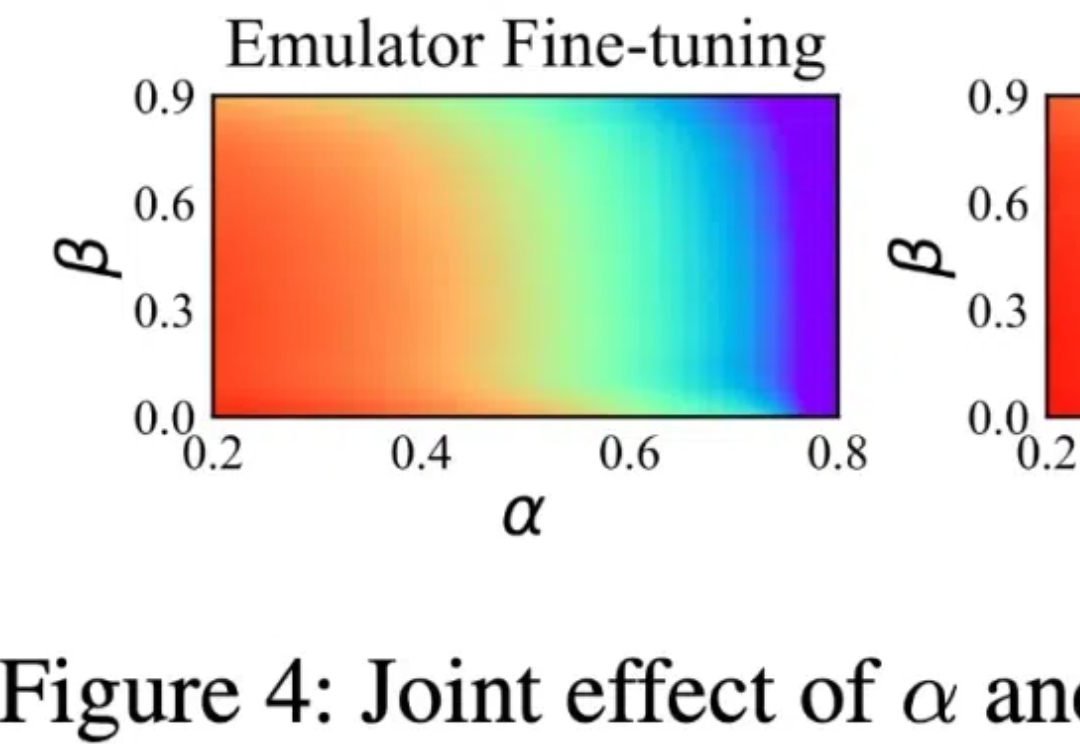
要让大模型适应各不一样的下游任务,微调必不可少。常规的中心化微调过程需要模型和数据存在于同一位置 —— 要么需要数据所有者上传数据(这会威胁到数据所有者的数据隐私),要么模型所有者需要共享模型权重(这又可能泄露自己花费大量资源训练的模型)。

AI真是助力科研的神器,不光能用大模型提升写作效率,跟AI技术沾边的论文中顶刊的概率也会增加,升职速度也会提升;但对于科学界来说,大家都一股脑去研究AI,那些不能用AI的领域受到了冷落,最终导致整体科研多样性下降。

清华大学与国家蛋白质科学中心的最新成果,结合了稳定学习的理论,提出了一个面向多中心、大队列异质数据的「稳定」生存分析方法。
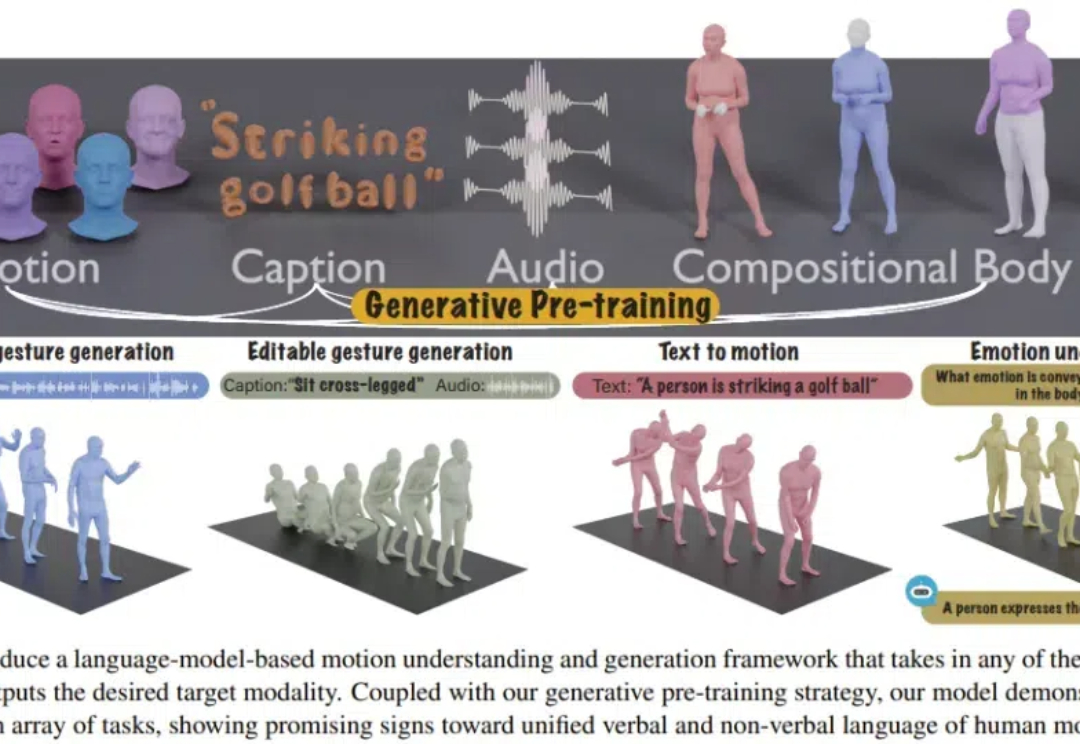
人类的沟通交流充满了多模态的信息。为了与他人进行有效沟通,我们既使用言语语言,也使用身体语言,比如手势、面部表情、身体姿势和情绪表达。
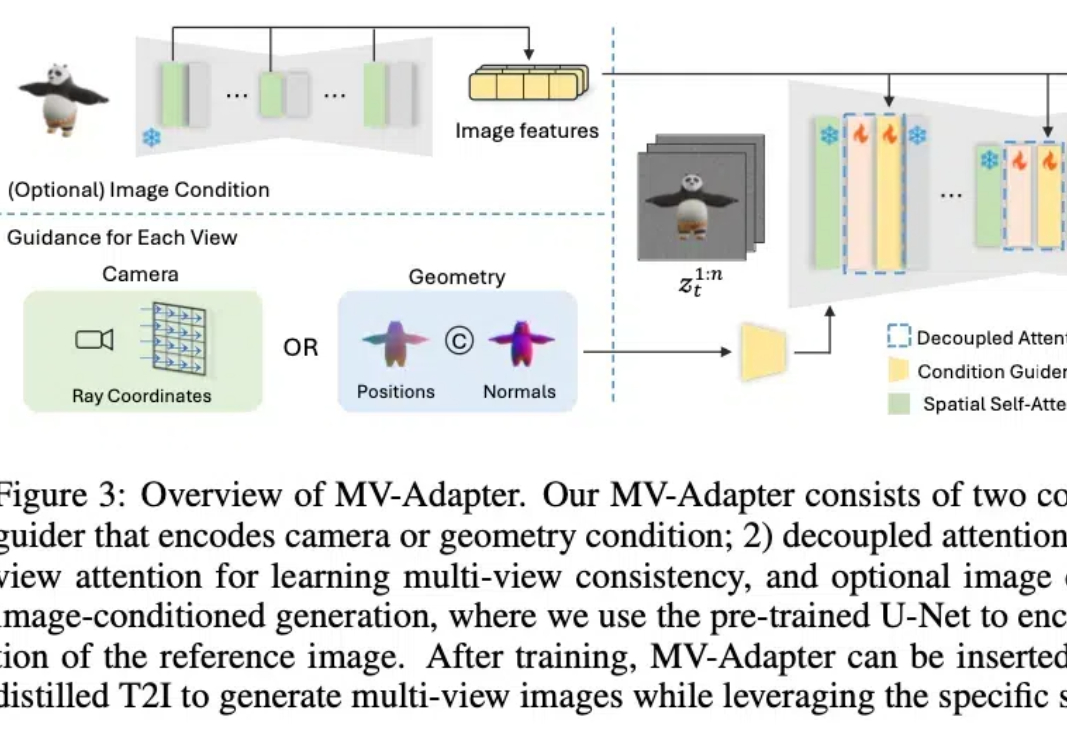
最近,2D/3D 内容创作、世界模型(World Models)似乎成为 AI 领域的热门关键词。作为计算机视觉的基础任务之一,多视角图像生成是上述热点方向的技术基础,在 3D 场景生成、虚拟现实、具身感知与仿真、自动驾驶等领域展现了广泛的应用潜力。
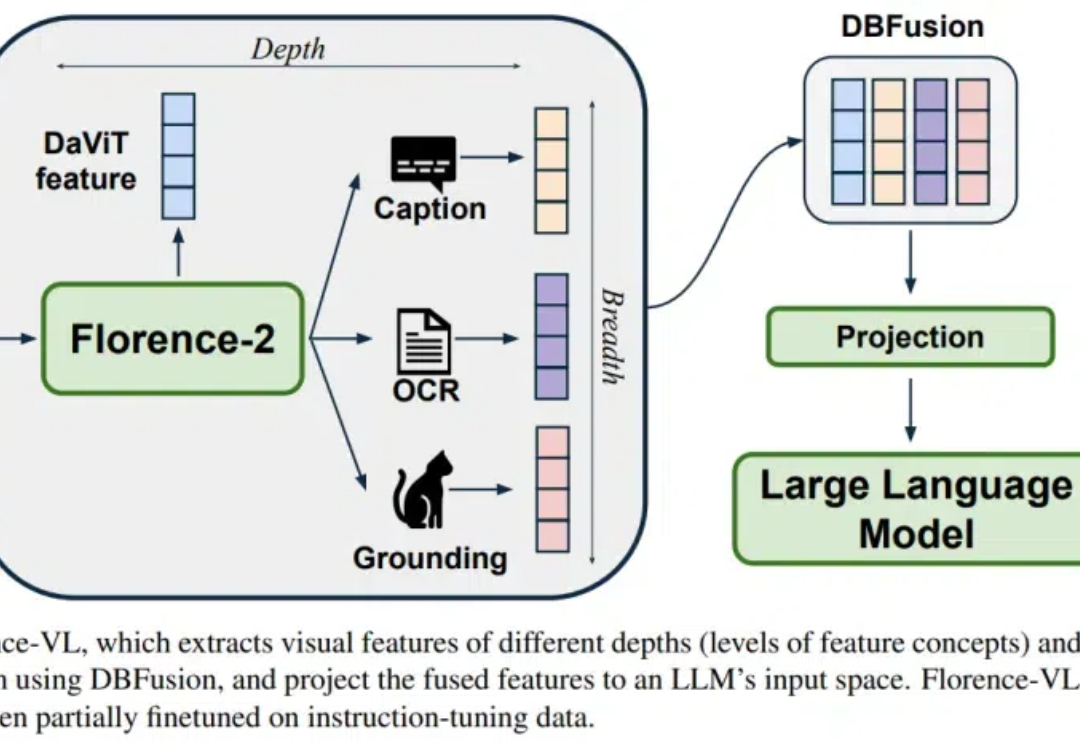
Florence-VL 提出了使用生成式视觉编码器 Florence-2 作为多模态模型的视觉信息输入,克服了传统视觉编码器(如 CLIP)仅提供单一视觉表征而往往忽略图片中关键的局部信息。
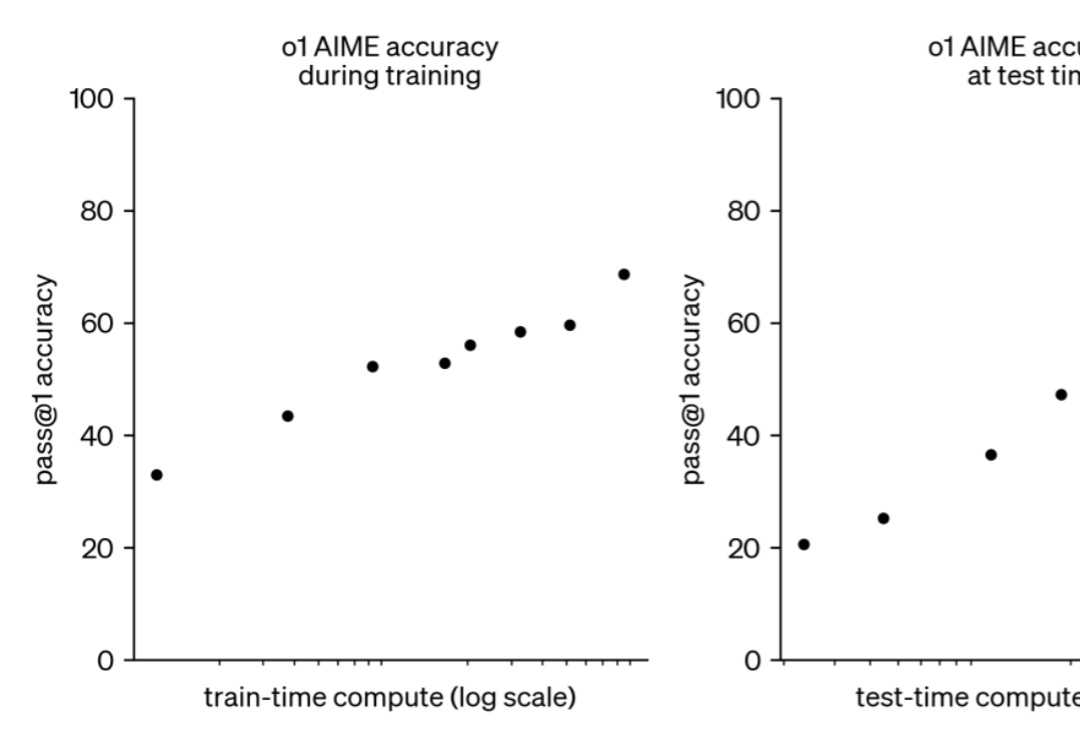
如果给小模型更长的思考时间,它们性能可以超越更大规模的模型。

现如今,以 GPT 为代表的大语言模型正深刻影响人们的生产与生活,但在处理很多专业性和复杂程度较高的问题时仍然面临挑战。在诸如药物发现、自动驾驶等复杂场景中,AI 的自主决策能力是解决问题的关键,而如何进行决策大模型的高效训练目前仍然是开放性的难题。

LLM 强大的语言能力,使其被广泛部署于 LLM 应用系统(LLM-integrated applications)中。此时,LLM 需要访问外部数据(如文件,网页,API 返回值)来完成任务。
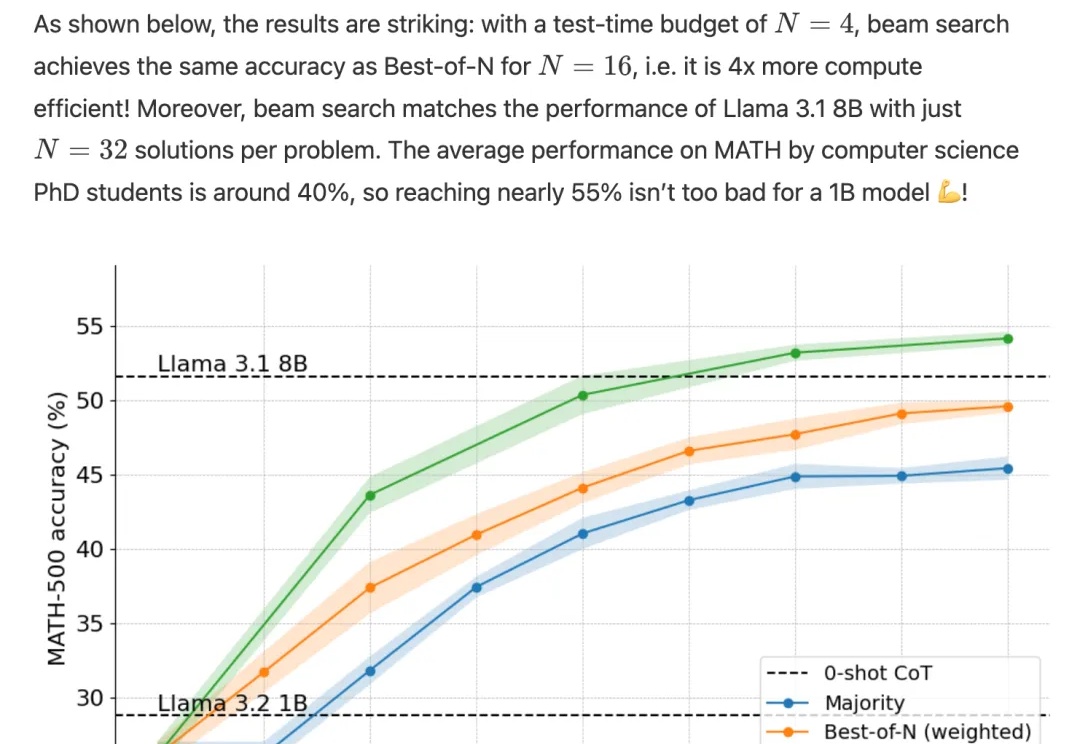
o1完整版公开仅10天,Scaling Law新范式就被逆向工程复现了!

BLT 在许多基准测试中超越了基于 token 的架构。
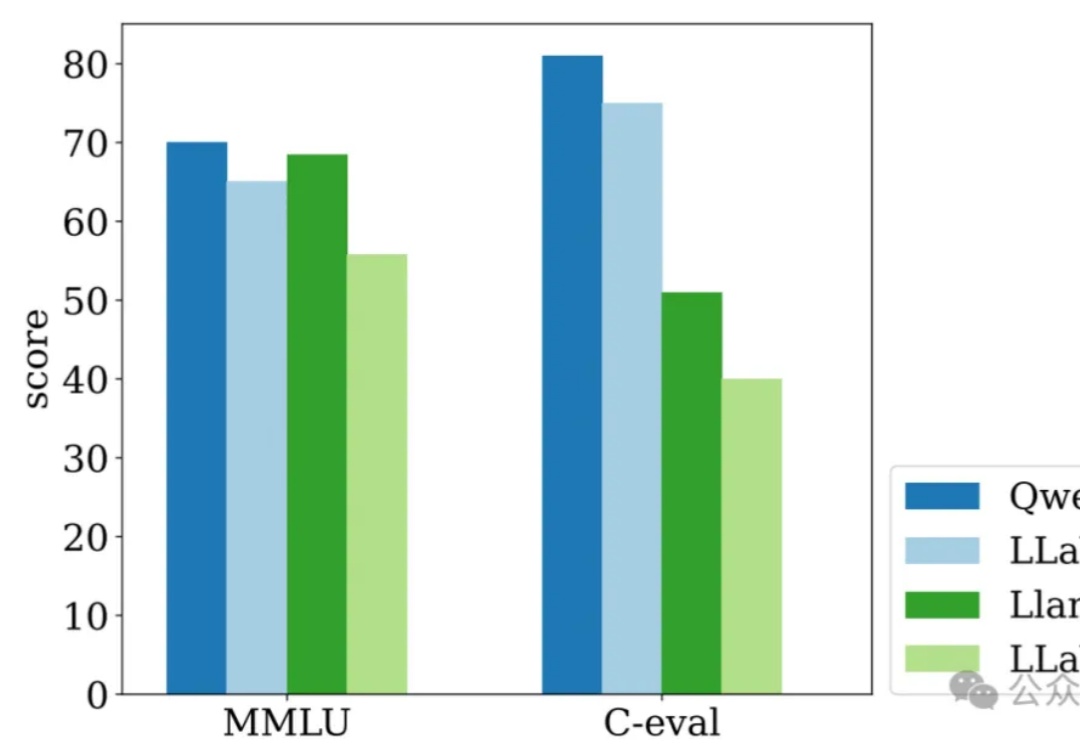
多模态大模型内嵌语言模型总是出现灾难性遗忘怎么办?
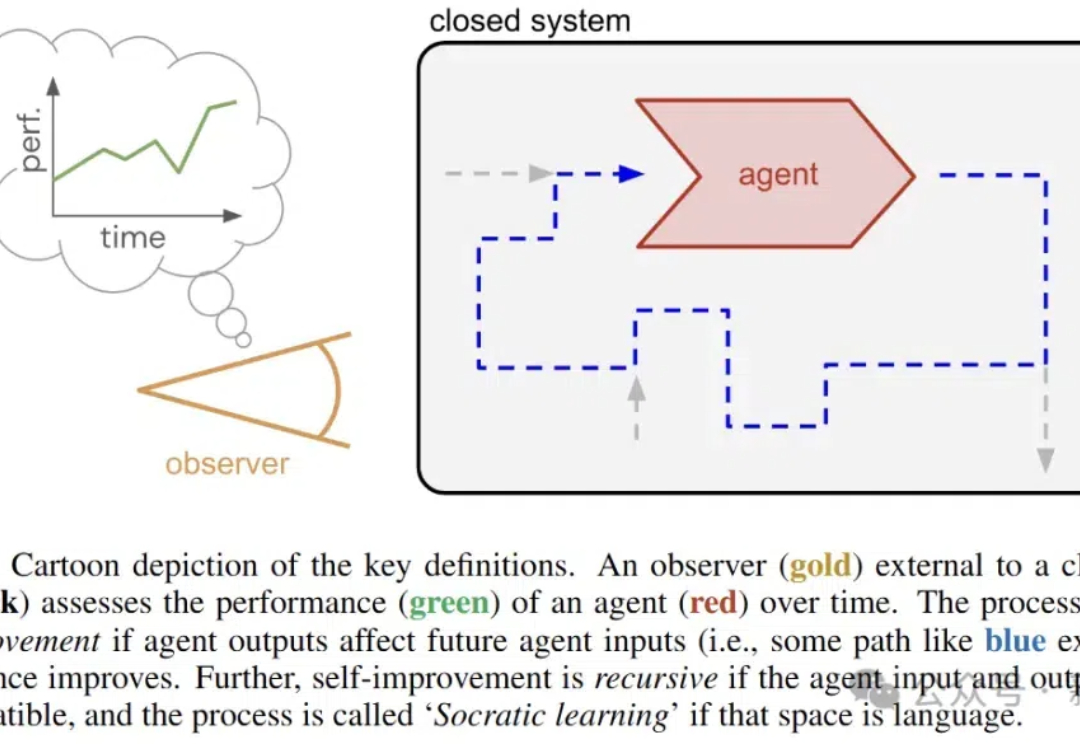
近日,谷歌DeepMind的研究人员推出了苏格拉底式学习,在没有外部数据的情况下,让AI通过语言游戏不断变强。
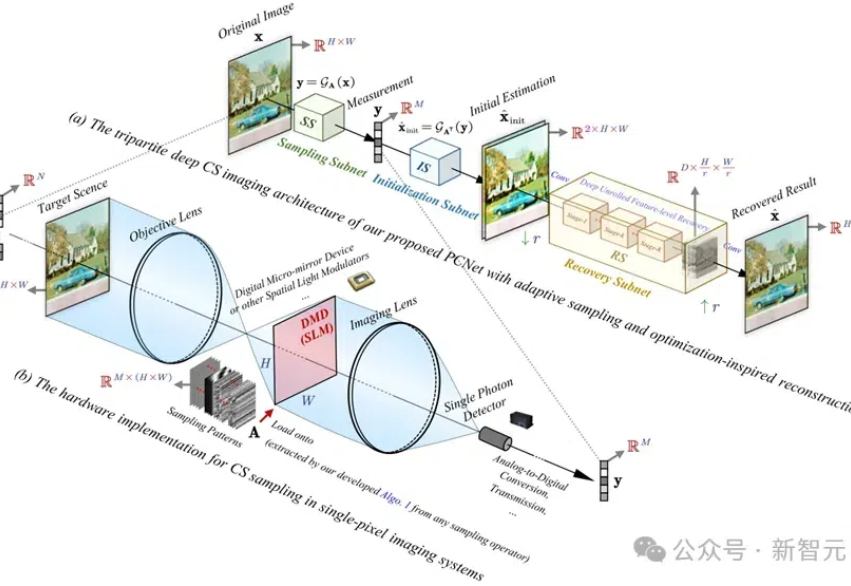
PCNet网络具有创新的协同采样算子和优化的重建网络,实验结果证明,其在图像重建精度、计算效率和任务扩展性方面均优于现有方法,为高分辨率图像的压缩感知提供了新的解决方案。
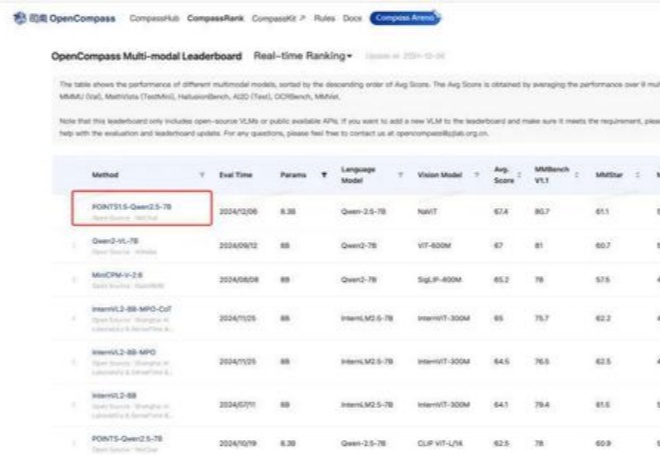
距离 POINT1.0 的发布已经过去两个月时间来,在这段时间业界不断涌现出一系列优秀的模型。我们通过不断紧跟前沿技术,并结合过去开发多模态模型沉淀下来的经验,对 POINTS1.0 进行了一系列更新,推出了 POINTS1.5。

DeepMind的研究人员开发了一种视频分层新方法,可以无需假设背景静止或精确的相机姿态,就能将视频分解成包含物体及其效果(如阴影和反射)的多个层,提升了视频编辑的灵活性和效率。