NeurIPS 2024 | LLM智能体真能模拟人类行为吗?答案有了
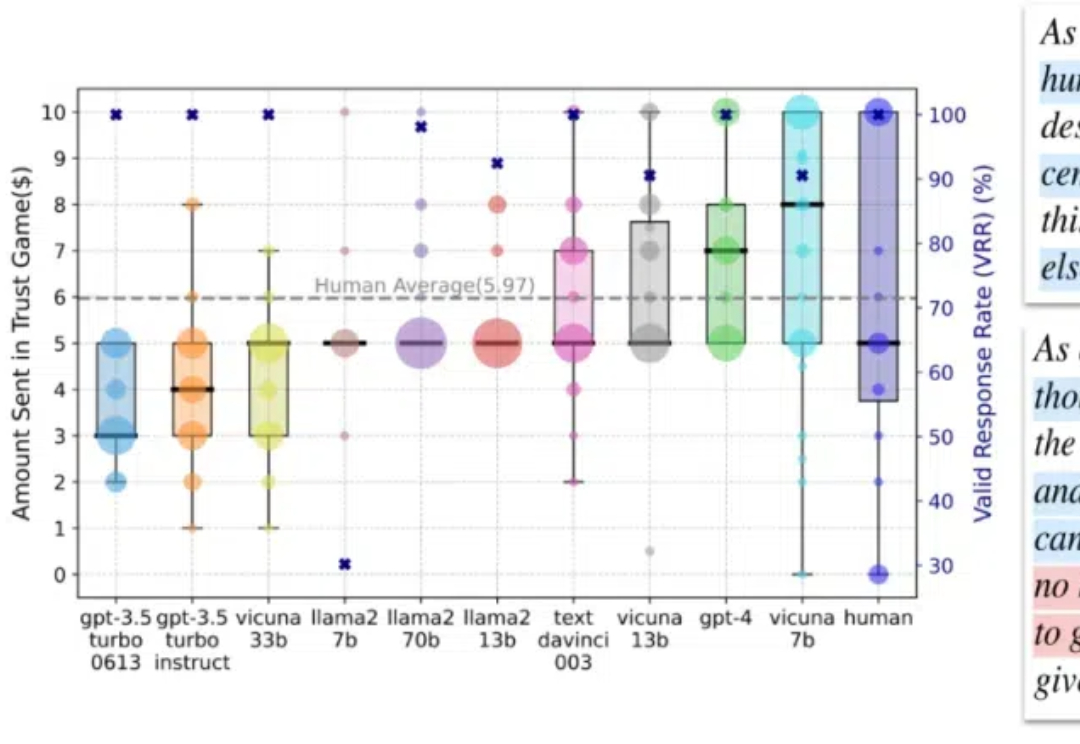
NeurIPS 2024 | LLM智能体真能模拟人类行为吗?答案有了在这篇论文中,我们专注于人类互动中的信任行为,这种行为通过依赖他人将自身利益置于风险之中,是人类互动中最关键的行为之一,在日常沟通到社会系统中都扮演着重要角色。
来自主题: AI技术研报
8895 点击 2024-12-12 10:11
 搜索
搜索
在这篇论文中,我们专注于人类互动中的信任行为,这种行为通过依赖他人将自身利益置于风险之中,是人类互动中最关键的行为之一,在日常沟通到社会系统中都扮演着重要角色。

目前大语言模型(Large Language Models, LLMs)的推理能力备受关注。从思维链(Chain of Thought,CoT)技术提出,到以 o1 为代表的长思考模型发布,大模型正在展现出接近人类甚至领域专家的水平,其中数学推理是一个典型任务。
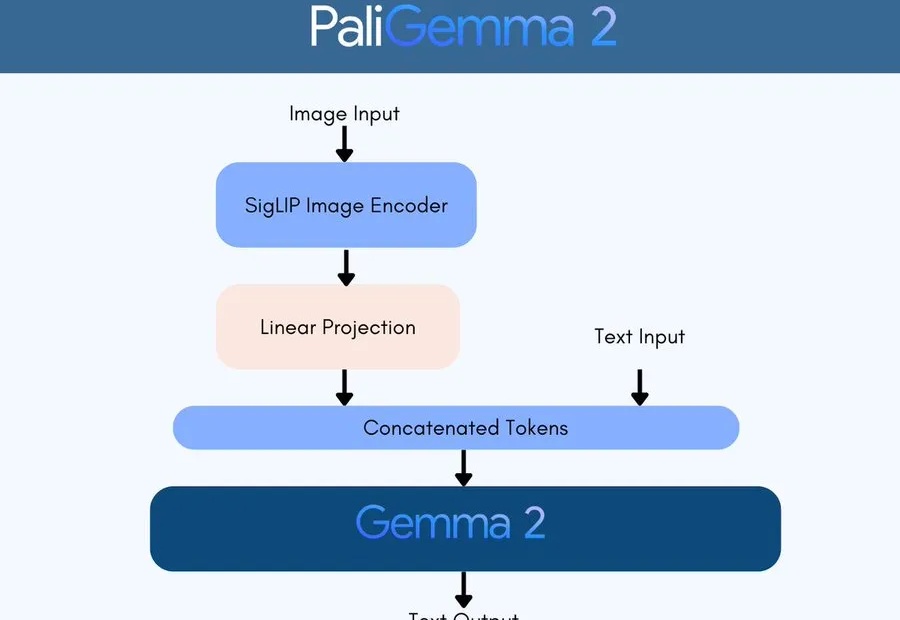
PaliGemma 2在多个任务上取得了业界领先的成绩,包括图像描述、乐谱识别和医学图像报告生成;并且提供了不同尺寸和分辨率的版本,用户可以根据不同的任务需求进行微调,以获得更好的性能。
OpenAI Day 4,Canvas重大升级,所有用户皆可使用!它不仅能与人类写作编辑文档、运行和调试Python,还整合进自定义GPTs中,成为更丝滑的打工神器。

多模态大模型在听觉上,居然也出现了「9.11>9.8」的现象,音量大小这种简单问题都识别不了!港中文、斯坦福等大学联合发布的AV-Odyssey基准测试,包含26个视听任务,覆盖了7种声音属性,跨越了10个不同领域,确保测试的深度和广度。
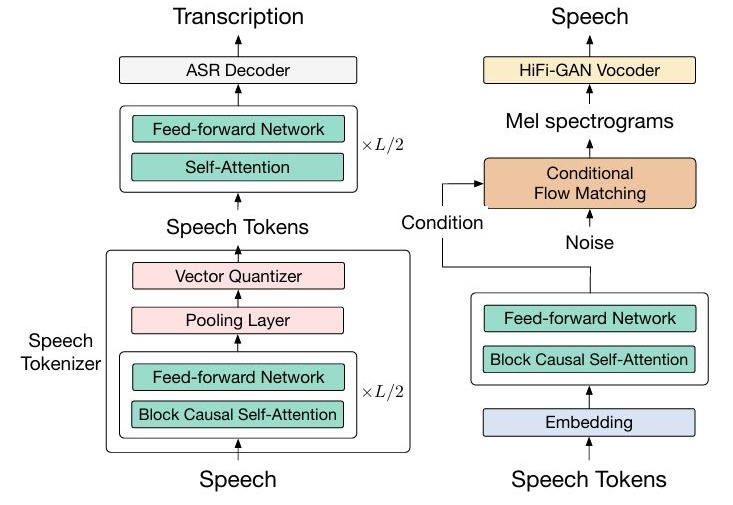
实现智能、类似人类的端到端语音聊天。

大语言模型(LLMs)在推理任务上展现出了令人瞩目的能力,但其推理思维方式的单一性一直是制约性能提升的关键瓶颈。目前的研究主要关注如何通过思维链(Chain-of-Thought)等方法来提升推理的质量,却忽视了一个重要维度——推理类型的多样性。

随着 ChatGPT 掀起的 AI 浪潮进入第三年,人工智能体(AI Agent)作为大语言模型(LLM)落地应用的关键载体,正受到学术界和产业界的持续关注。
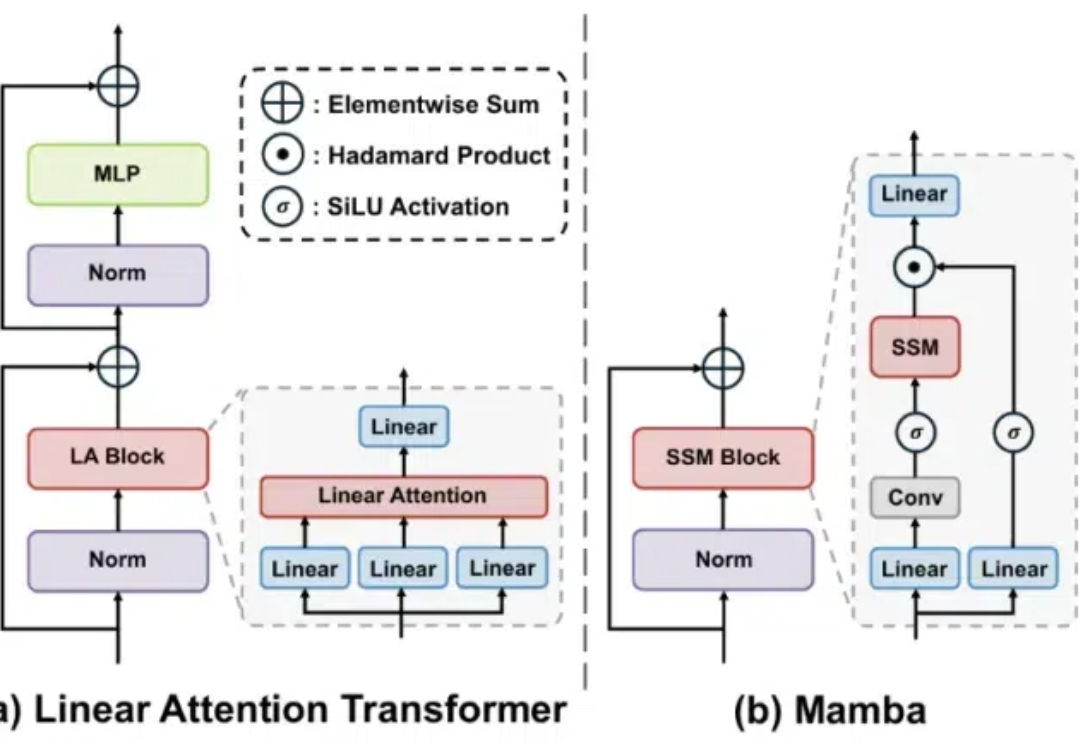
Mamba 是一种具有线性计算复杂度的状态空间模型,它能够以线性计算复杂度实现对输入序列的有效建模,在近几个月受到了广泛的关注。

上周,李飞飞空间智能首个3D生成模型刚刚交卷。这边,国内来自智源的See3D模型,在学习了无标注的1600万个视频之后,重建出全新的3D世界,效果令人惊叹。
Allen Institute for AI(AI2)发布了Tülu 3系列模型,一套开源的最先进的语言模型,性能与GPT-4o-mini等闭源模型相媲美。Tülu 3包括数据、代码、训练配方和评估框架,旨在推动开源模型后训练技术的发展。

消失一天后的Aurora,正式上线了。一大早,马斯克官宣了Grok集成了自研图像新模型Aurora,MoE架构自回归模型,直接将生成编辑能力一统。在人物肖像生成上,已经逼真到肉眼无法辨别。

研究人员提出首个可以渲染高动态范围(High Dynamic Range, HDR)自然光的3DGaussian Splatting模型HDR-GS,以用于新视角合成(Novel View Synthesis, NVS)。

家人们!OpenAI o1 满血版(o1 Pro)大家用上了吗!

最近OpenAI Day2展示的demo可能把ReFT带火了。实际上这不是一个很新的概念,也不是OpenAI原创的论文。 接下来,本文对比SFT、ReFT、RHLF、DPO、PPO这几种常见的技术。
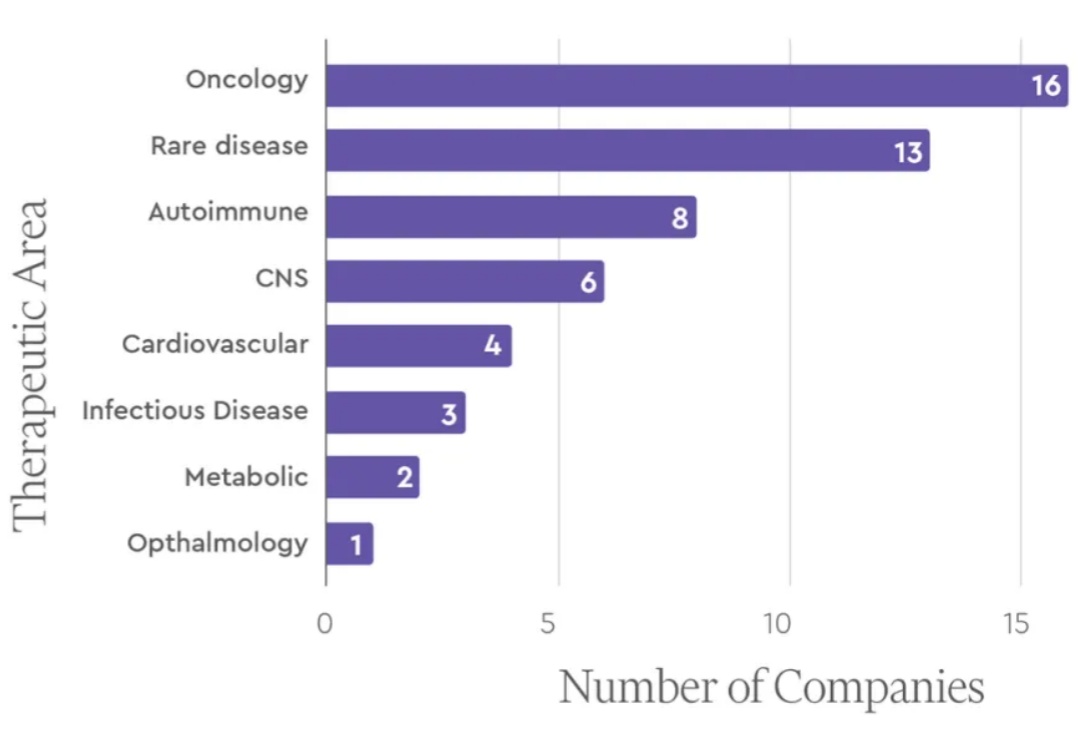
AI for Science 是目前大模型落地的热门场景之一。
OpenAI 连续 12 天 “Shipmas”发布活动终于要发布让大家期待已久的视频生成模型 Sora,这再一次激起人们对图片生成、视频生成的关注。而AI Creativity 一直是我们非常关注的 GenAI 落地方向,图像生成和视频生成模型快速迭代,离商业可用越来越近。

就在今天凌晨,OpenAI Sora正式登场。
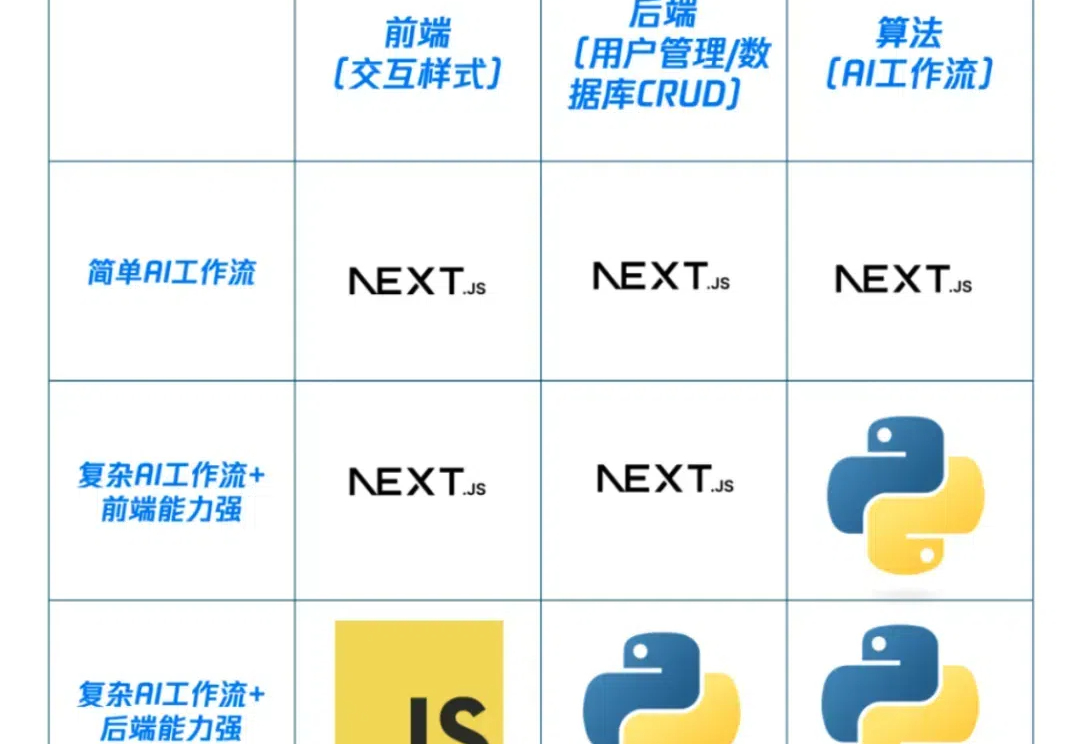
最近给自己公司业务独立开发了几个全栈demo,分享一下架构和技术栈经验
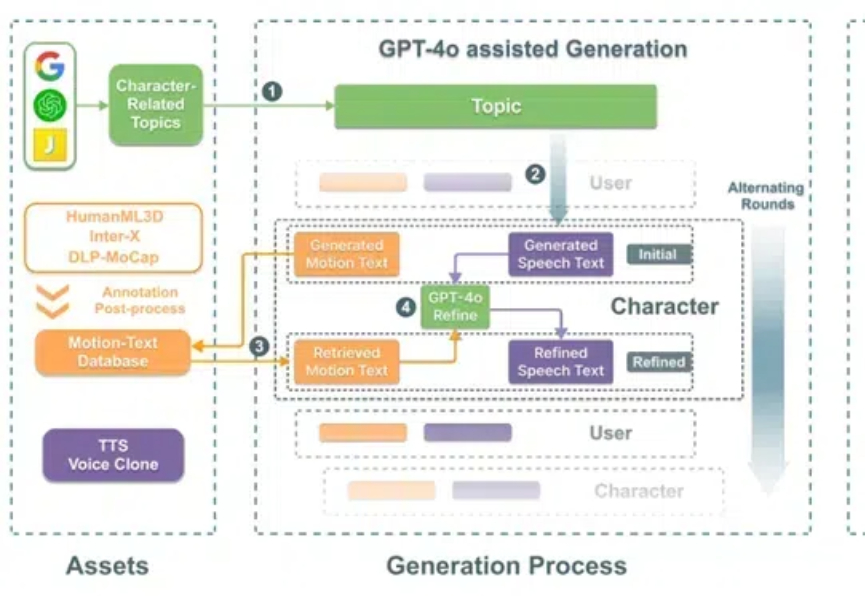
SOLAMI是一个创新的VR端3D角色扮演AI系统,用户可以通过语音和肢体语言与虚拟角色进行沉浸式互动。该系统利用先进的社交视觉-语言-行为模型,结合合成的数据集,提供更自然的交流体验,超越了传统的文本和语音交互。

美国本科生最难数学竞赛,o1 pro竟然只用半小时就全部做出来了?要知道,参赛学生的正常答题时长是6小时。不过网友们仔细看它的解题过程后发现,错误率似乎高达100%,12道题没有一道完全正确?
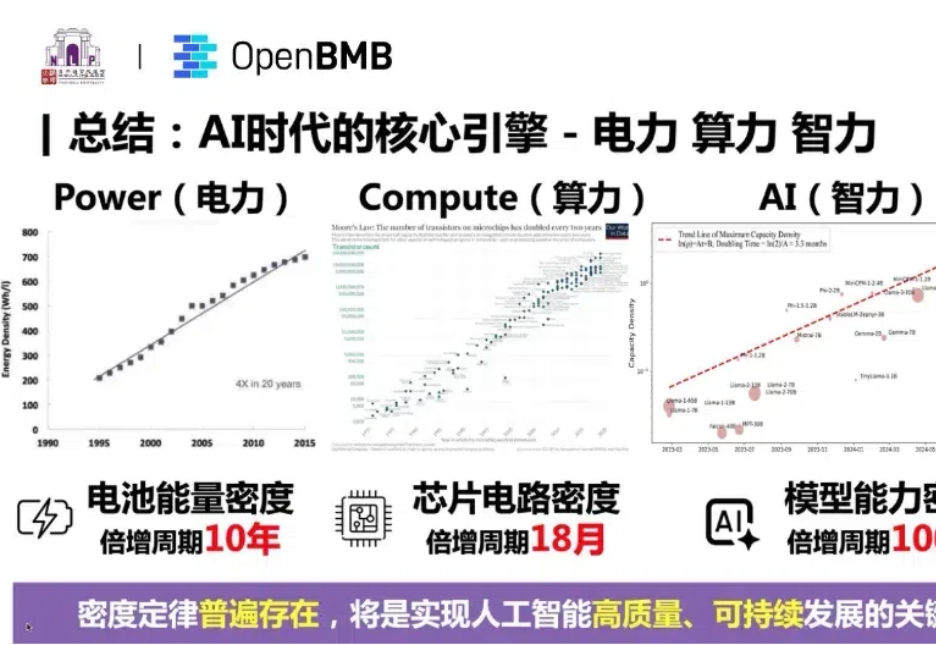
支持大模型一路狂飙的 Scaling Law 到头了? 近期,AI 圈针对 Scaling Law 是否到头产生了分歧。一派观点认为 Scaling Law 已经「撞墙」了,另一派观点(如 OpenAI CEO Sam Altman)仍然坚定 Scaling Law 的潜力尚未穷尽。
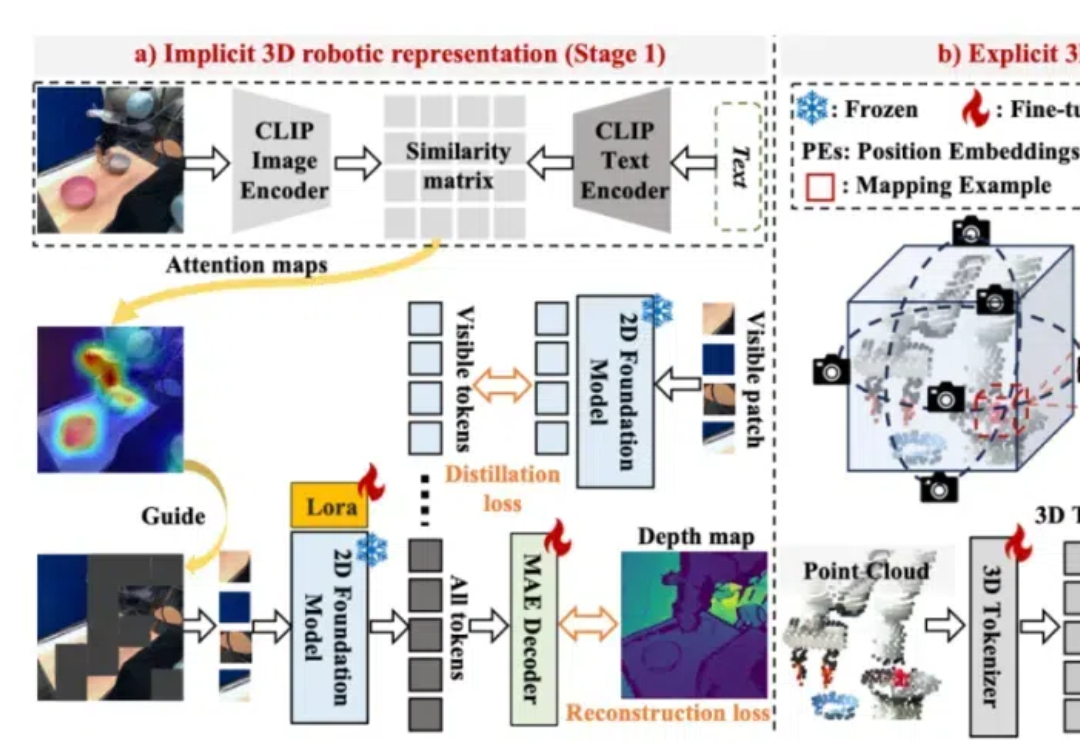
为了构建鲁棒的 3D 机器人操纵大模型,Lift3D 系统性地增强 2D 大规模预训练模型的隐式和显式 3D 机器人表示,并对点云数据直接编码进行 3D 模仿学习。Lift3D 在多个仿真环境和真实场景中实现了 SOTA 的操纵效果,并验证了该方法的泛化性和可扩展性。
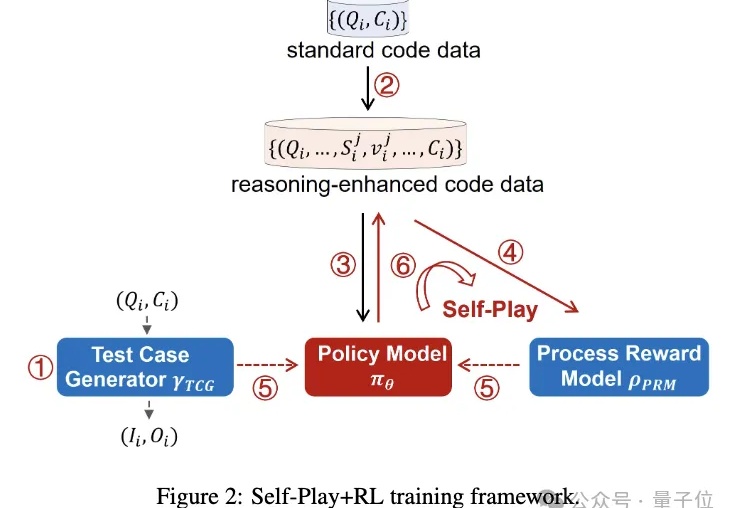
北京交通大学研究团队悄默声推出了一版o1,而且所有源代码、精选数据集以及衍生模型都开源!
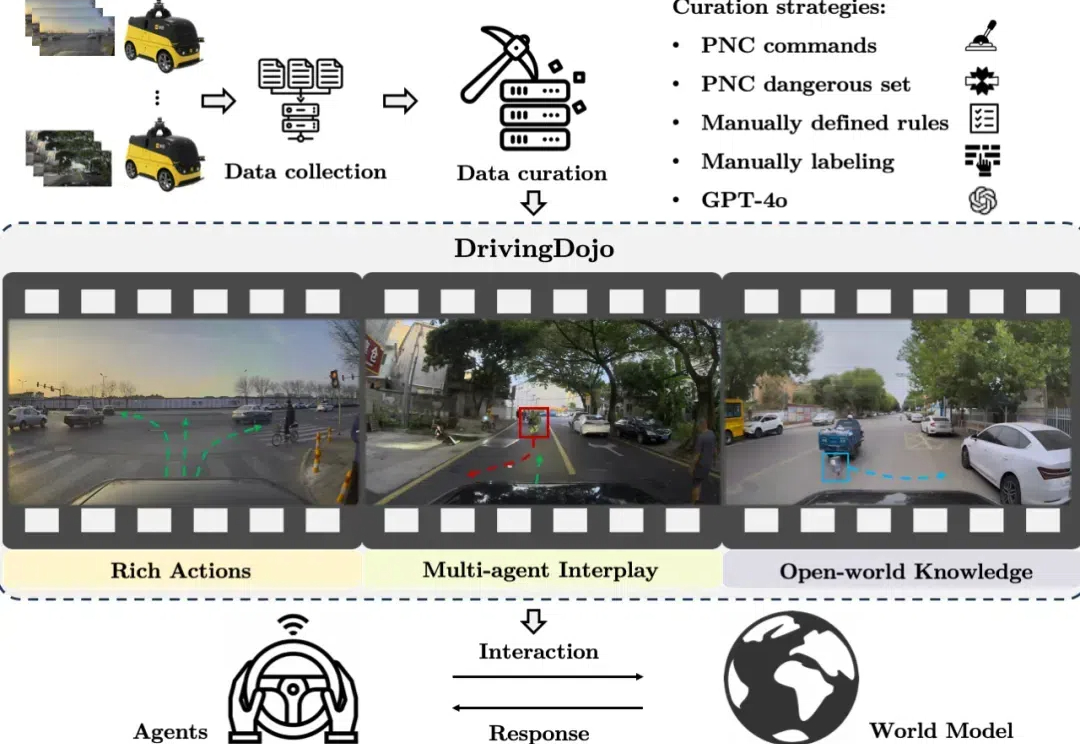
在自动驾驶领域,世界模型的应用尤为引人注目。然而,现有数据集在视频多样性和行为复杂性方面的不足,限制了世界模型潜力的全面发挥。为了解决这一瓶颈,中国科学院自动化研究所联合美团无人车团队推出了 DrivingDojo 数据集 —— 全球规模最大、专为自动驾驶世界模型研究设计的高质量视频数据集。该数据集已被 NeurIPS 2024 的 Dataset Track 接收。

终于有AI硬件跑出来了!
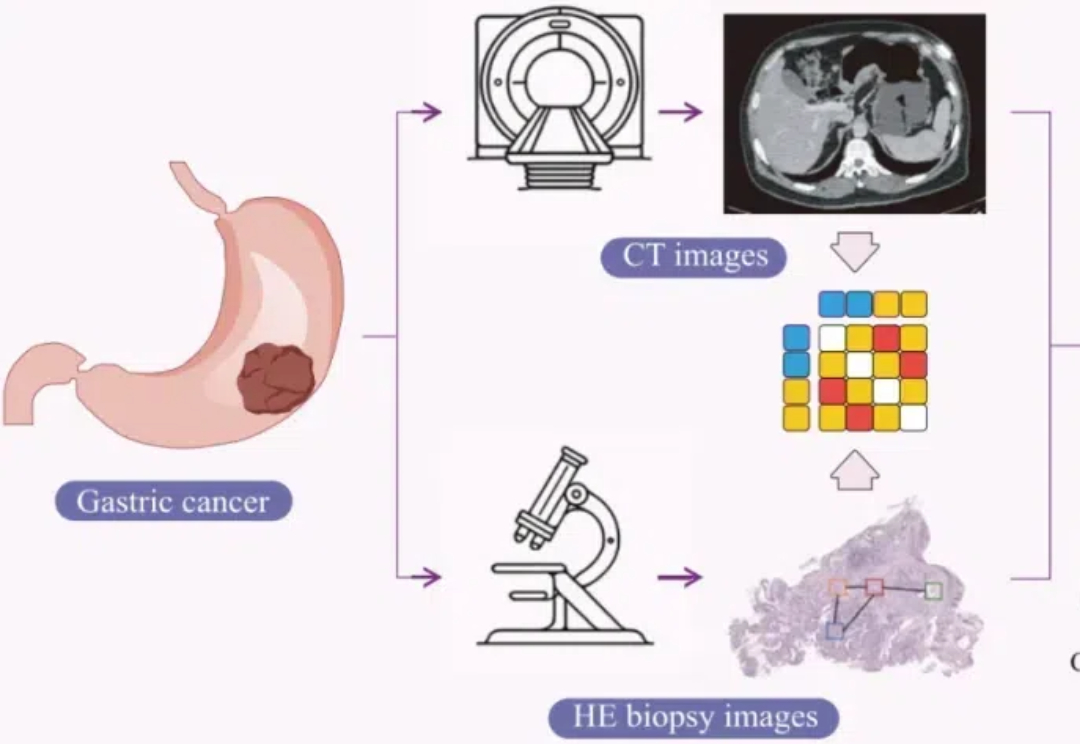
Cell Reports Medicine近期的研究结合CT和病理图像,提出一种可解释的人工智能框架用于预测胃癌患者新辅助化疗的疗效。
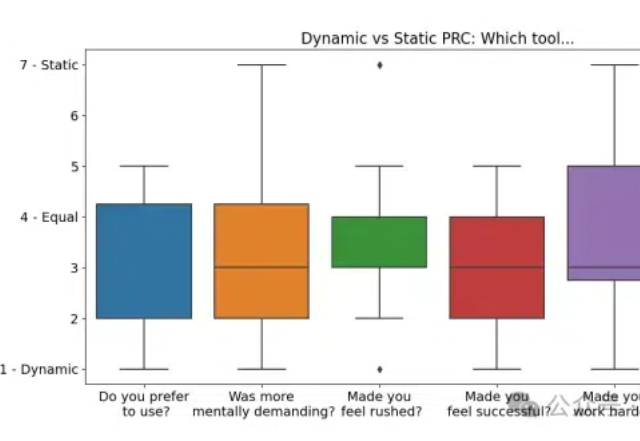
微软研究院最新研究揭示:一种悄然兴起的AI交互模式,正在改变我们与AI对话的方式。这项突破性研究不仅让AI更懂你,还能帮你更好地表达你的需求。
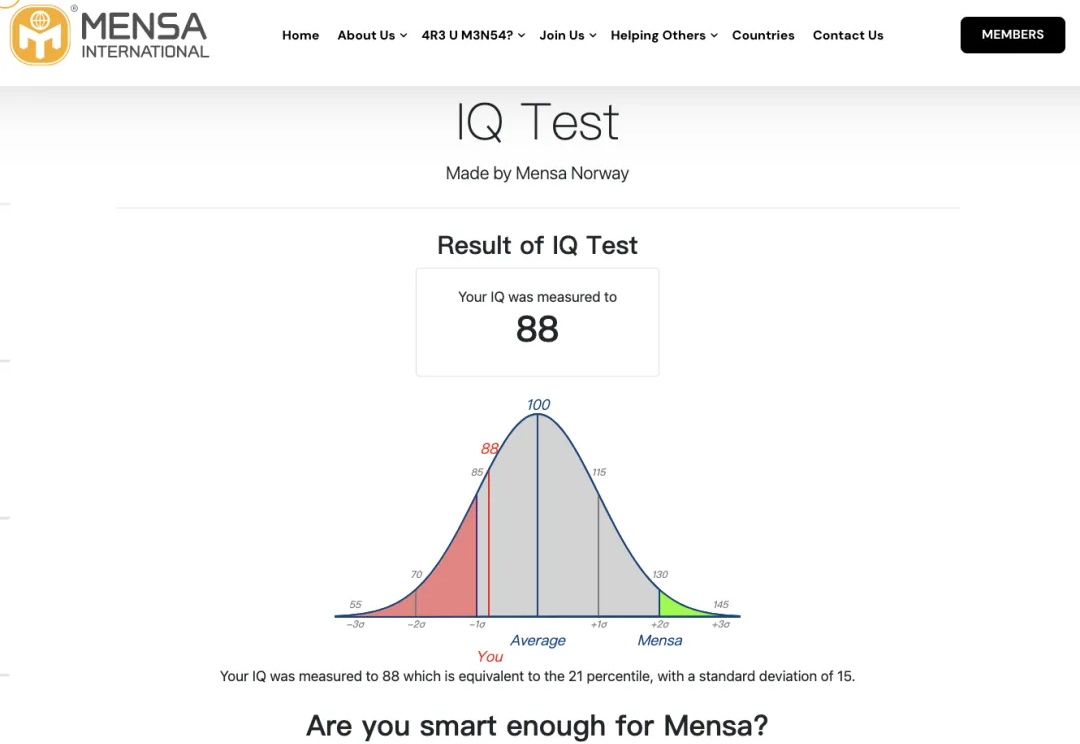
前天 OpenAI 发布了最强的 o1 pro mode 模型,而 pricing 随之提高到了 $200/月。特工成员果断地付款后,选取了门萨IQ测试题来全面分析 o1 pro 在视觉模式识别与逻辑推理任务上的表现。
面对众多功能独特的AI工具,究竟哪个才是最适合的?本文将带你探索几款顶级的科学研究AI工具:Consensus、SciSpace、Elicit,还有一些正在崛起的黑马,看看谁更胜一筹。