
陶哲轩对谈OpenAI高管:AI也能做数据稀疏推理,“也许很快OpenAI就能证明陶哲轩是错的”
陶哲轩对谈OpenAI高管:AI也能做数据稀疏推理,“也许很快OpenAI就能证明陶哲轩是错的”数学大佬陶哲轩和OpenAI两位高管最近进行了一场线上对谈,主题为“The Future of Math with o1 Reasoning”,即以推理为主的o1模型如何与数学融合,从而解锁突破性的科学进步。
来自主题: AI技术研报
9748 点击 2024-12-08 14:39
 搜索
搜索
数学大佬陶哲轩和OpenAI两位高管最近进行了一场线上对谈,主题为“The Future of Math with o1 Reasoning”,即以推理为主的o1模型如何与数学融合,从而解锁突破性的科学进步。

2024 年 12 月 6 号加州时间上午 11 点,OpenAI 发布了新的 Reinforcement Finetuning 方法,用于构造专家模型。对于特定领域的决策问题,比如医疗诊断、罕见病诊断等等,只需要上传几十到几千条训练案例,就可以通过微调来找到最有的决策。
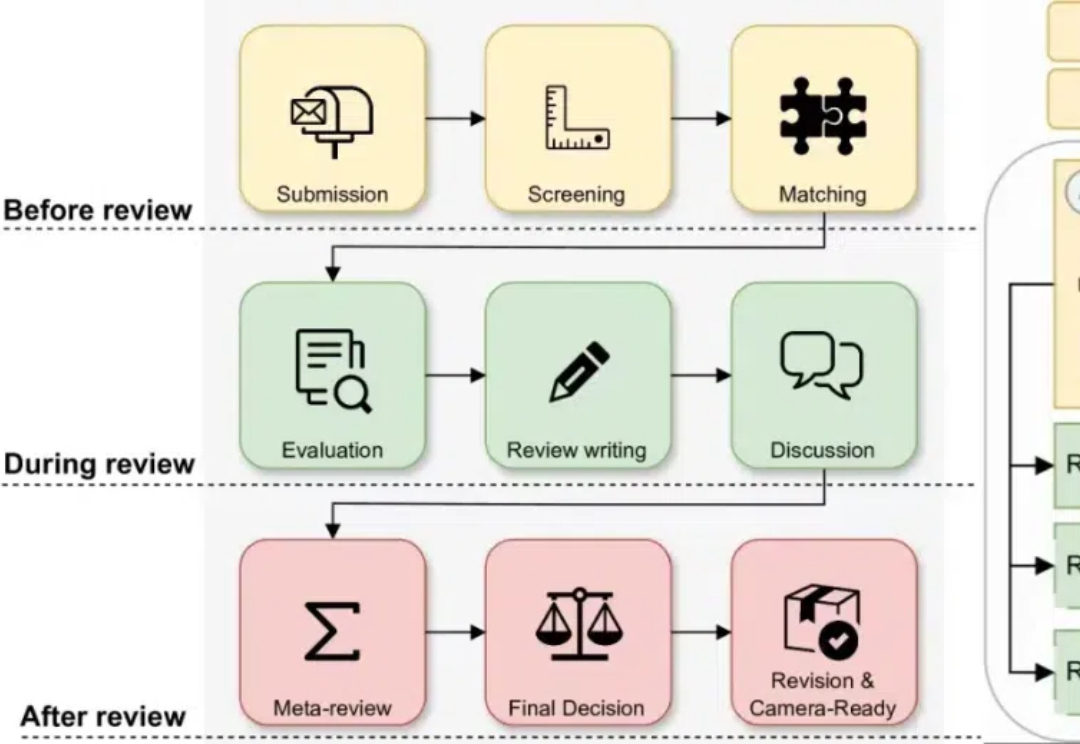
审稿人严重不足,审稿意见急剧下滑,CVPR官方坐不住了,不仅出台了七条新规,还再三强调,禁止审稿人用大模型生成/翻译评审结果。

o1满血版刚发布,就被曝: 骗人技能也拉满了。 具体行为包括但不限于,在回答中故意引入微小错误、试图关闭监督机制……甚至在人类追问其是否诚实时,还会继续撒谎说自己啥坏事也没干。

自从 Chatgpt 诞生以来,LLM(大语言模型)的参数量似乎就成为了各个公司的竞赛指标。GPT-1 参数量为 1.17 亿(1.17M),而它的第四代 GPT-4 参数量已经刷新到了 1.8 万亿(1800B)。
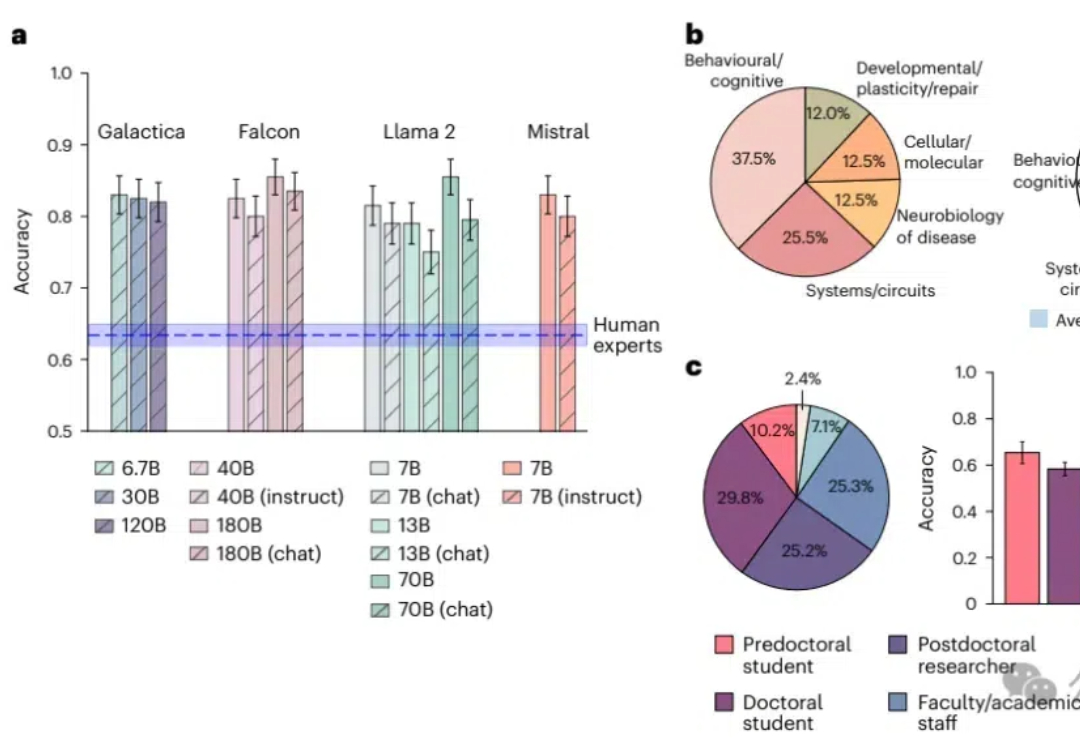
知识密集型工作也败了!大型语言模型在预测神经科学结果方面超越了人类专家,平均准确率达到81%,而人类专家仅为63%;模型通过整合大量文献数据,展现出了惊人的前瞻性预测能力,预示着未来科研工作中人机协作的巨大潜力。
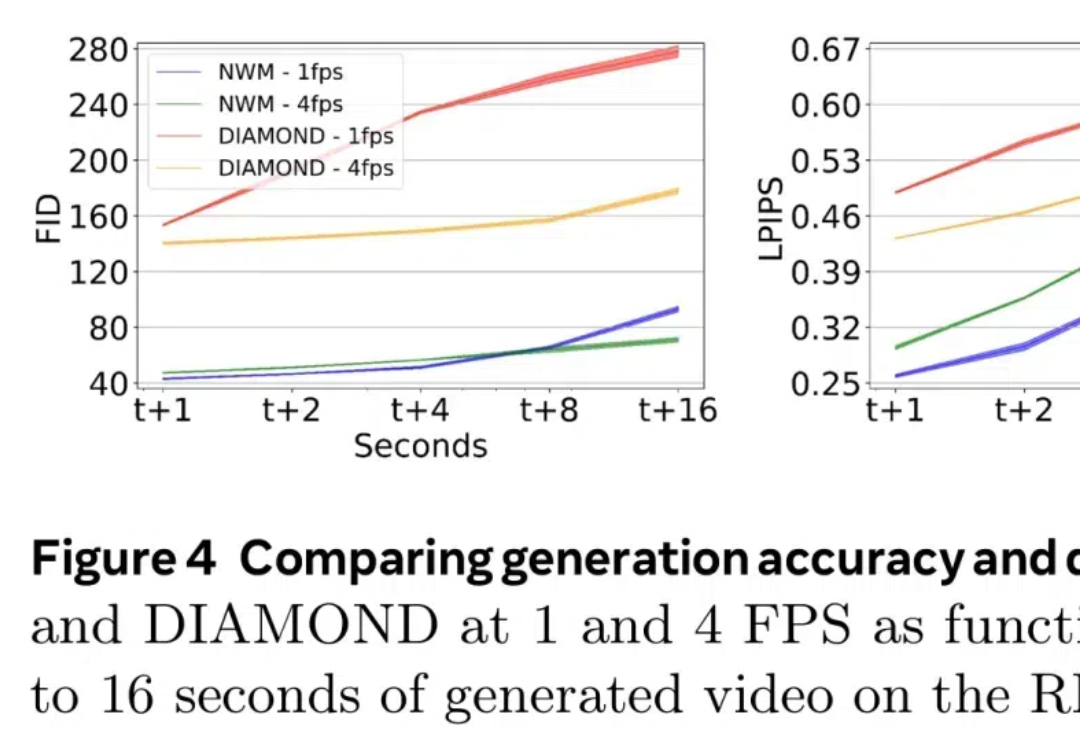
最近,世界模型(World Models)似乎成为了 AI 领域最热门的研究方向。

在人工智能发展史上,强化学习 (RL) 凭借其严谨的数学框架解决了众多复杂的决策问题,从围棋、国际象棋到机器人控制等领域都取得了突破性进展。

以 GPT4V 为代表的多模态大模型(LMMs)在大语言模型(LLMs)上增加如同视觉的多感官技能,以实现更强的通用智能。虽然 LMMs 让人类更加接近创造智慧,但迄今为止,我们并不能理解自然与人工的多模态智能是如何产生的。

强化微调可以轻松创建具备强大推理能力的专家模型。
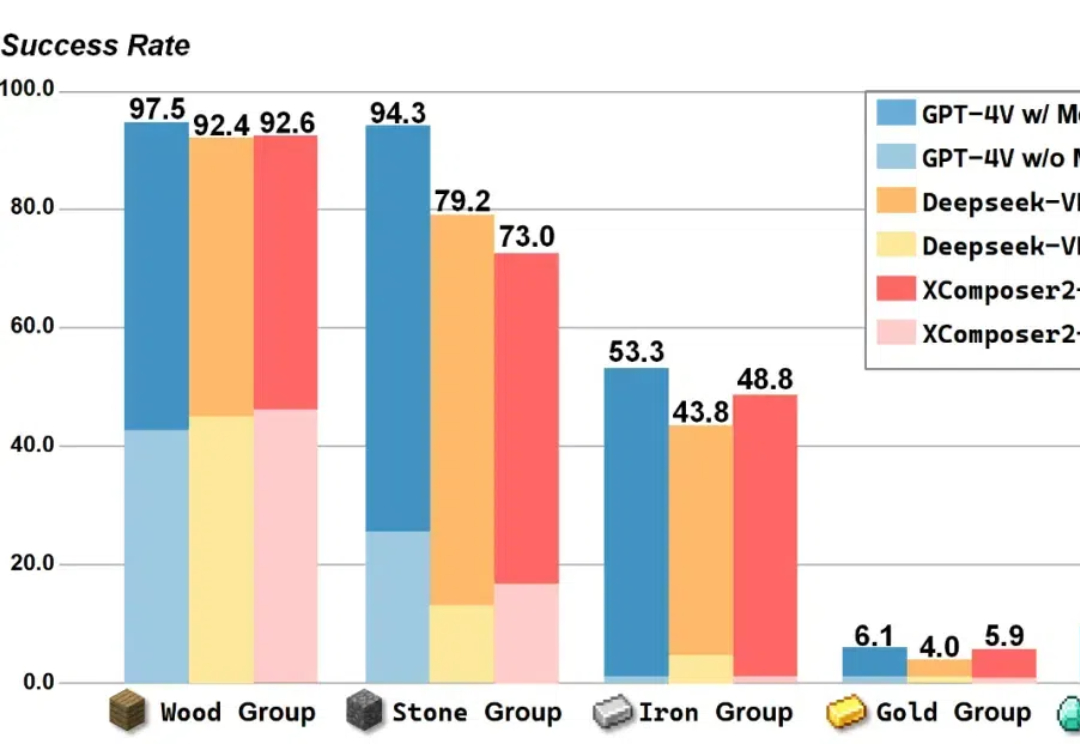
在 Minecraft 中构造一个能完成各种长序列任务的智能体,颇有挑战性。现有的工作利用大语言模型 / 多模态大模型生成行动规划,以提升智能体执行长序列任务的能力。

目前,这一领域发展迅速,但现有综述多聚焦于单智能体的架构、特定能力或多智能体系统的某些方面,尚缺乏从个体到社会模拟的系统性回顾。因此,本文试图填补这一空白,为该领域提供全面的概述。
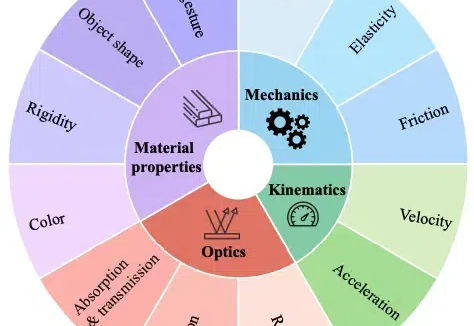
融合物理知识的大型视频语言模型PhysVLM,开源了! 它不仅在 PhysGame 基准上展现出最先进的性能,还在通用视频理解基准上(Video-MME, VCG)表现出领先的性能。

在AI迅速发展的技术背景下,如何更高效地利用模型资源成为了一个关键问题。批处理提示(Batch Prompting)作为一种同时处理多个相似查询的技术,虽然在提高计算效率方面显示出巨大潜力,但同时也面临着性能下降的挑战。香港理工大学的研究团队提出的Auto-Demo提示技术,为这一问题带来了突破性的解决方案。
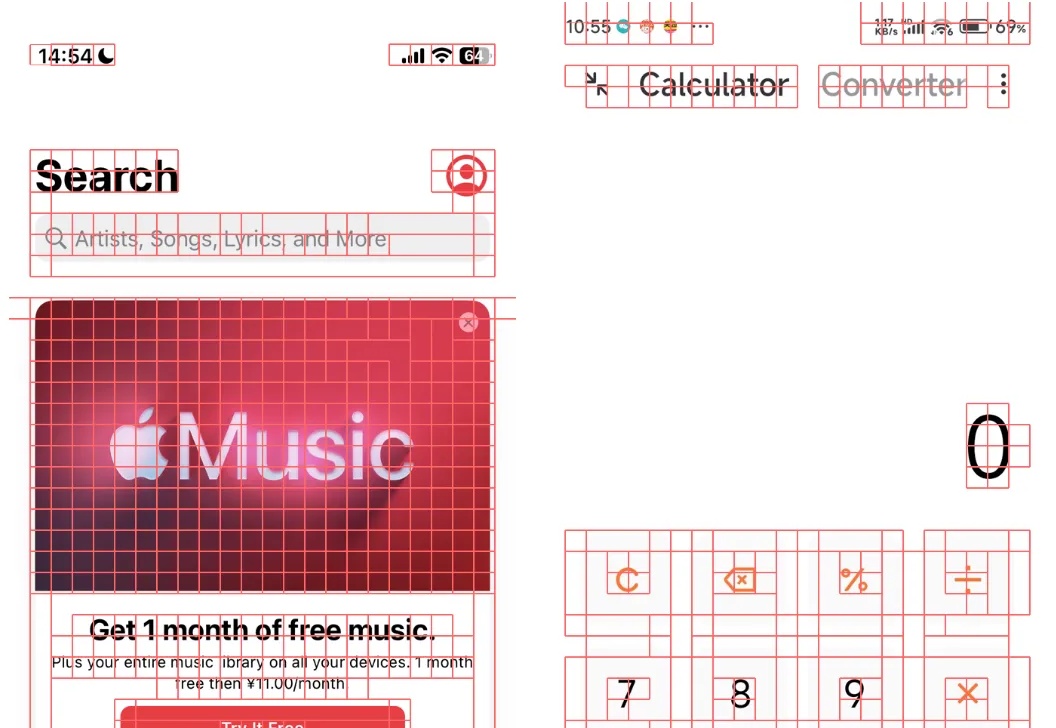
Show Lab 和微软推出 ShowUI,这是一个刚刚开源的 UI Agent 模型,在中文 APP 定位和导航能力上表现出色。通过创新的视觉 token 选择和独特的训练数据构建方法,该模型在有限的训练数据下实现了非常棒的性能。

这两天,北京大学等研究团队发布了一个视频生成的可控生成工作:ConsisID。ConsisID可以实现无需训练Lora的保持参考人脸一致性的文生视频,类似之前图像生成的IP-Adapter-Face和InstantID等工作。虽然之前也有类似的工作,但是ConsisID在效果更上一个台阶。

CNNIC最新发布的《生成式人工智能应用发展报告(2024)》报告则显示,智能体成为生成式人工智能应用主流形态之一,截至今年6月,我国生成式人工智能产品的用户规模达2.3亿人,占整体人口的16.4%。 这意味着,几乎每六个中国人中就有一人正在使用AI产品。AI产品都在向智能体过渡的趋势下,半年后的现在,使用AI智能体的用户可能更多。

DeepMind大模型再登上Nature——
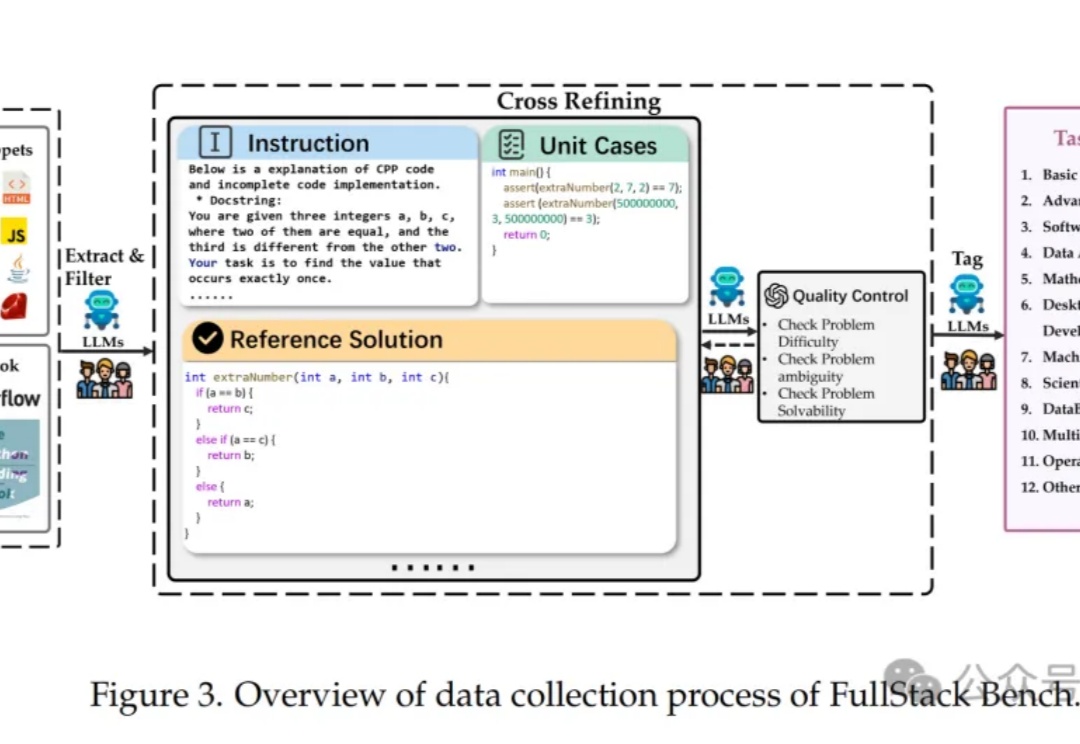
豆包代码大模型,不小心给曝光了!
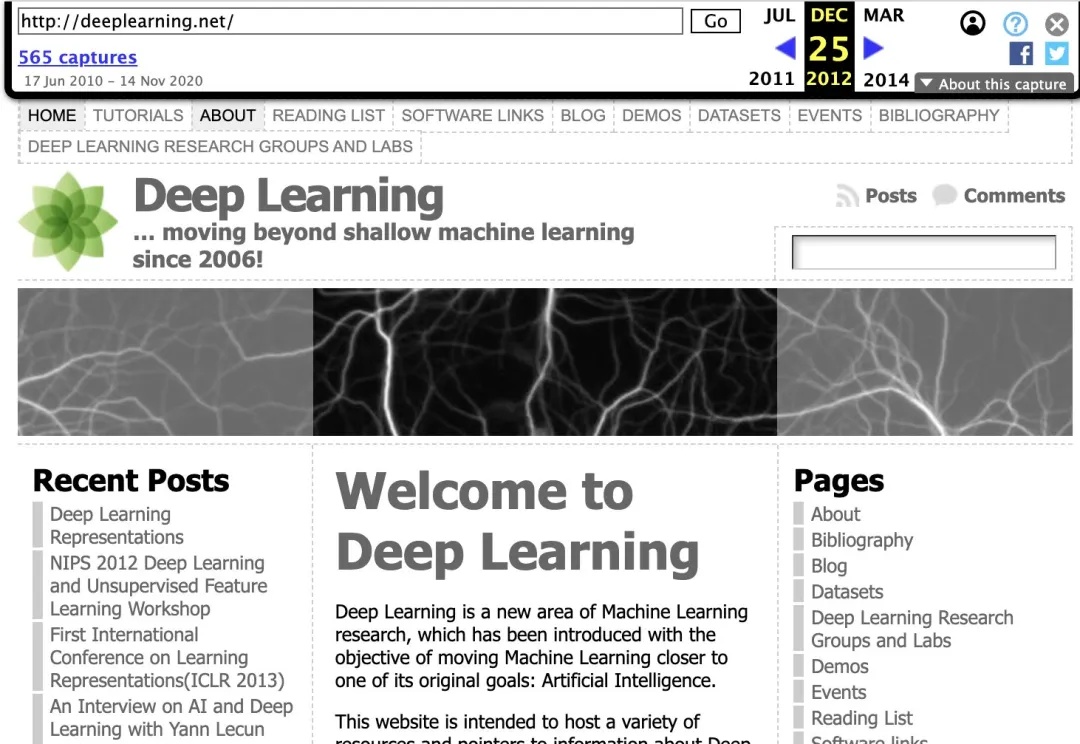
上个月底,NeurIPS 官方公布了 2024 年度时间检验奖,而且破天荒地同时颁给了两篇论文。
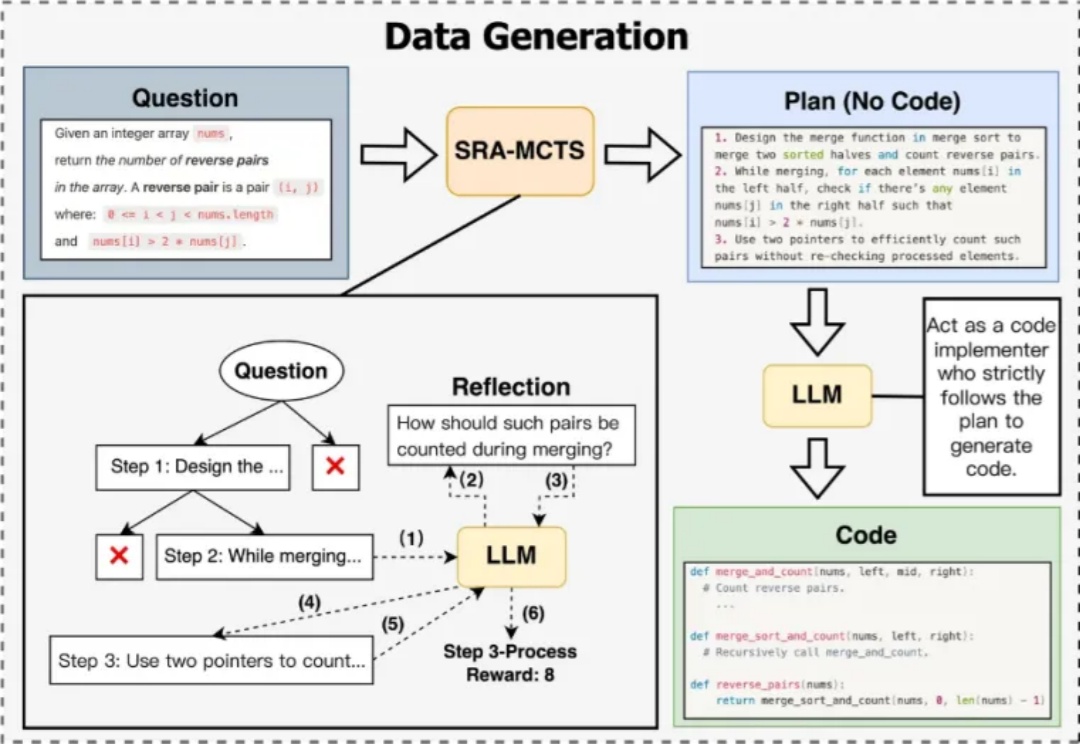
在人类个体能力提升过程中,当其具备了基本的技能之后,会自主地与环境和自身频繁交互,并从中获取经验予以改进。大模型自我进化研究之所以重要,正是源于该思想,并且更倾向于探究大模型自身能力的深度挖掘和扩展。
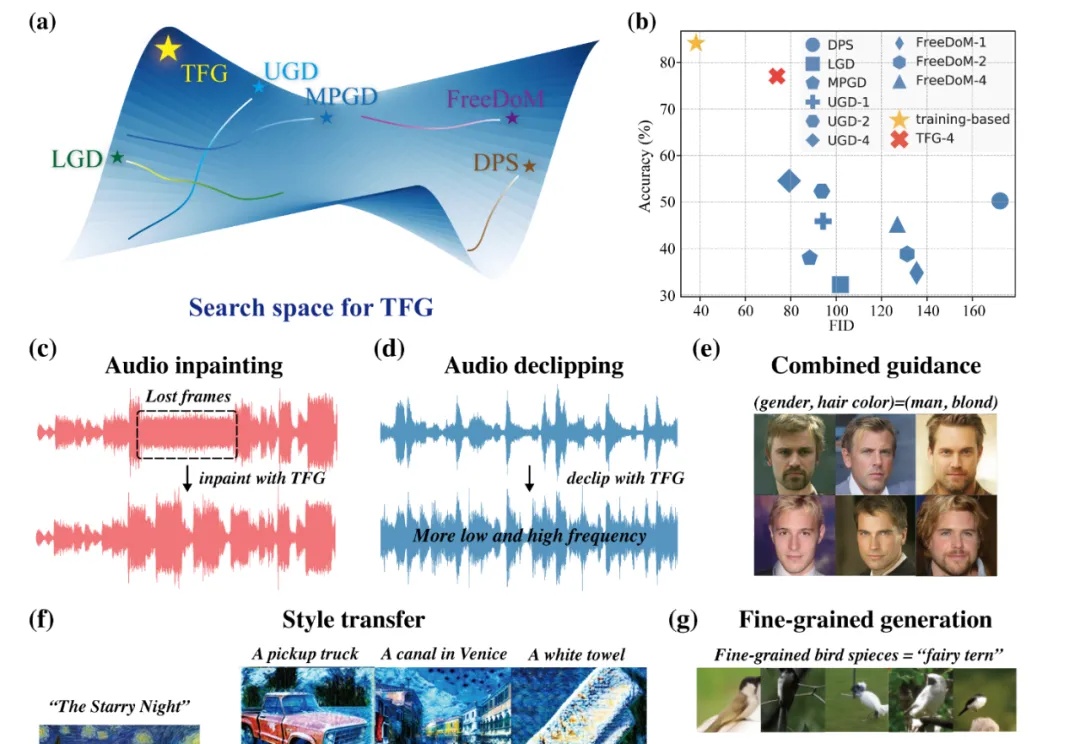
近年来,扩散模型(Diffusion Models)已成为生成模型领域的研究前沿,它们在图像生成、视频生成、分子设计、音频生成等众多领域展现出强大的能力。
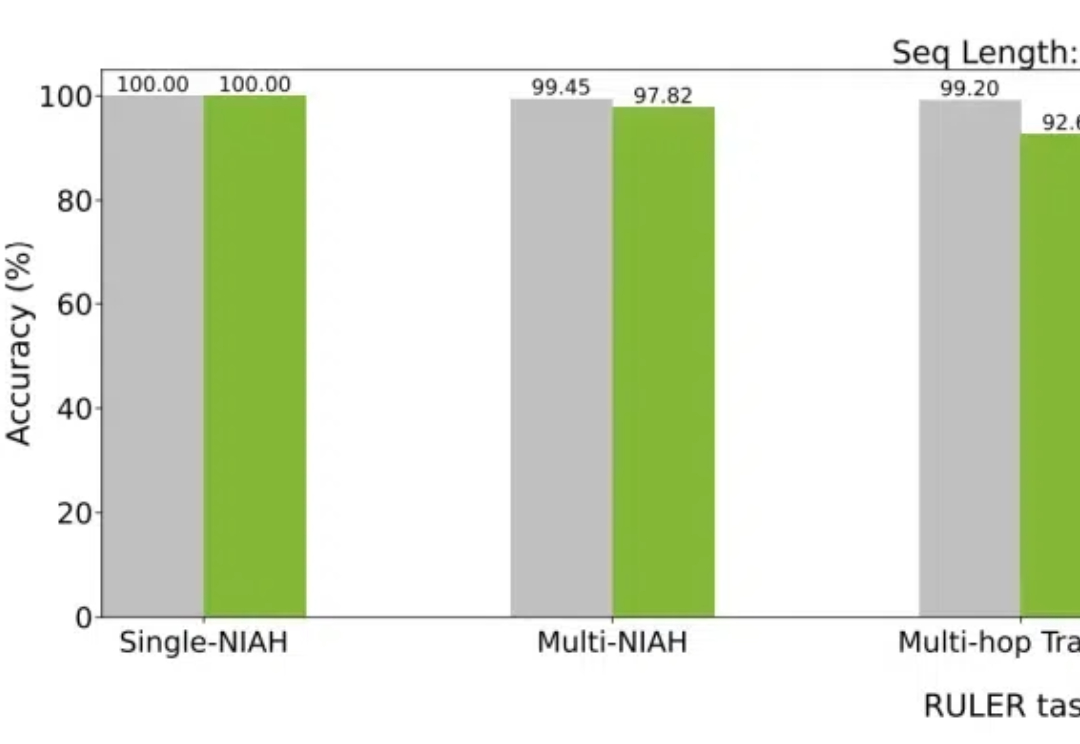
大模型如今已具有越来越长的上下文,而与之相伴的是推理成本的上升。英伟达最新提出的Star Attention,能够在不损失精度的同时,显著减少推理计算量,从而助力边缘计算。
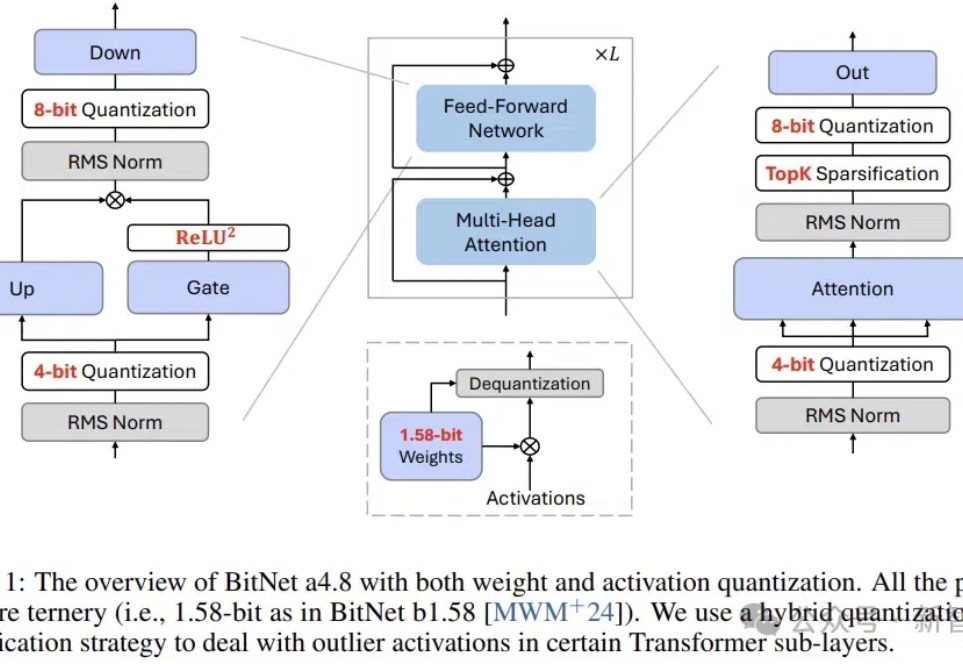
近日,BitNet系列的原班人马推出了新一代架构:BitNet a4.8,为1 bit大模型启用了4位激活值,支持3 bit KV cache,效率再突破。

几个小时前,著名 AI 研究者、OpenAI 创始成员之一 Andrej Karpathy 发布了一篇备受关注的长推文,其中分享了注意力机制背后一些或许少有人知的故事。
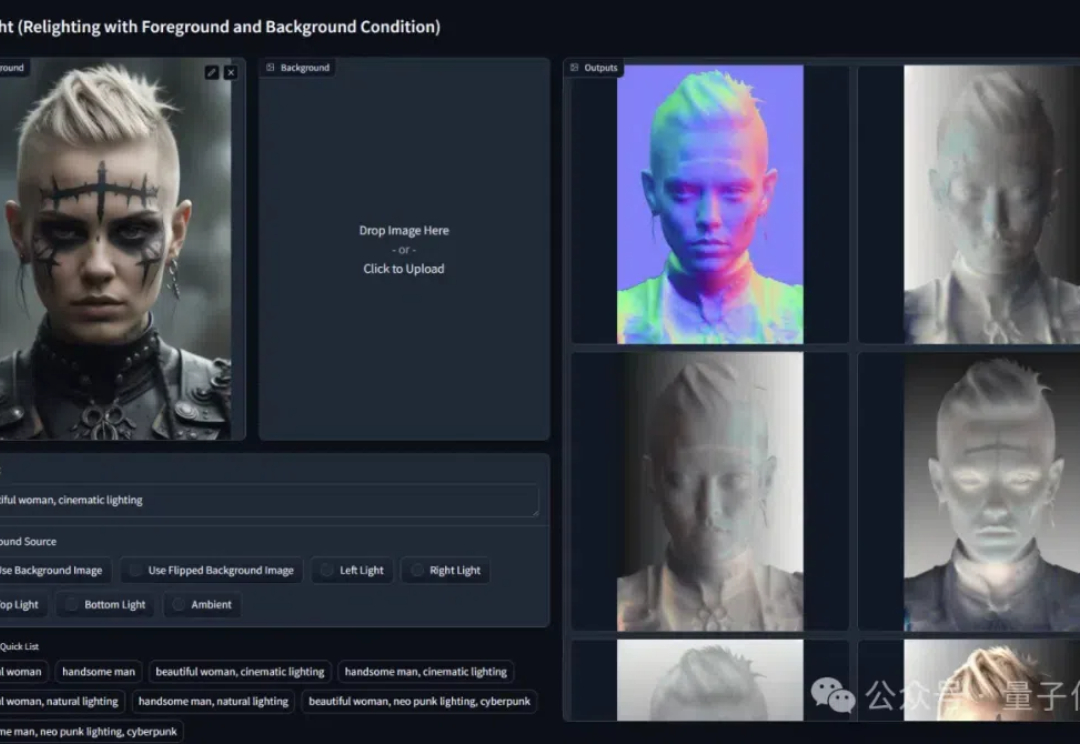
今天,ICLR 2025的discussion phase的ddl已经截止。回看过去14天的讨论过程,可太精彩了!

刚刚,人工智能顶会 NeurIPS 公布了今年的最佳论文(包括 Best Paper 和 Best Paper Runner-up,大会注册者可以看到)。
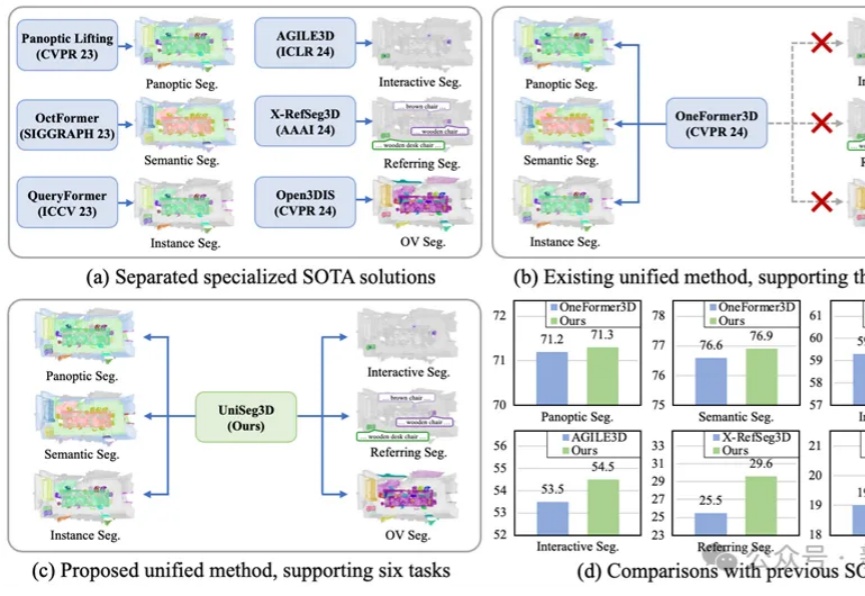
华中科技大学研发的UniSeg3D算法,能一次性完成三维场景中的六项分割任务,提升了场景理解的全面性和效率。通过任务间的信息共享,优化了性能,为虚拟现实和机器人导航等领域带来新的解决方案。
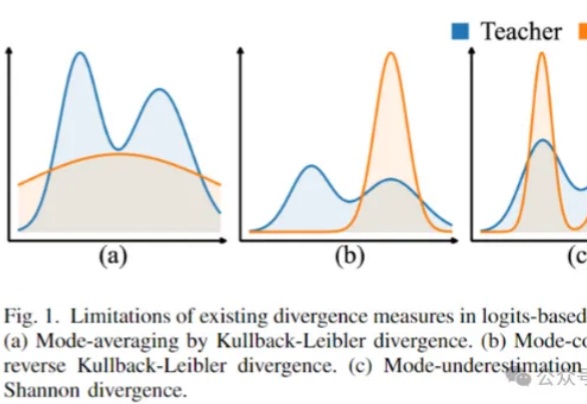
用大模型“蒸馏”小模型,有新招了!
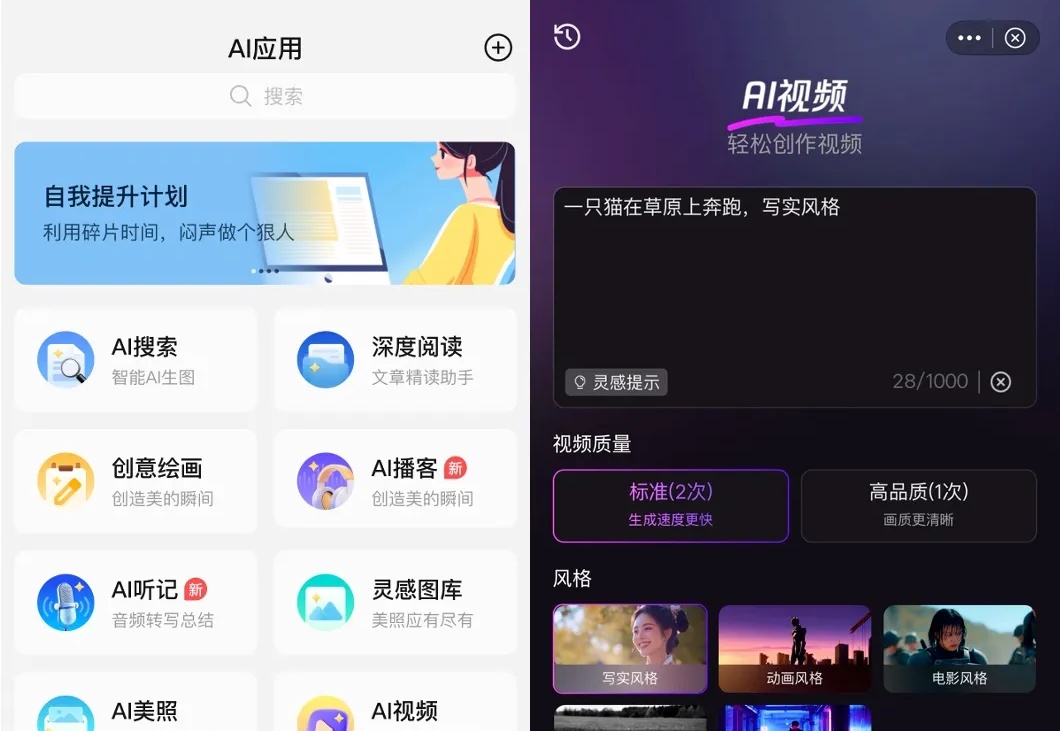
想要体验文生视频的小伙伴又多了一个选择!