
穹彻智能-上交大最新Nature子刊速递:解析深度学习驱动的视触觉动态重建方案
穹彻智能-上交大最新Nature子刊速递:解析深度学习驱动的视触觉动态重建方案随着人形机器人技术的迅猛发展,如何有效获取高质量的操作数据成为核心挑战。鉴于人类操作行为的复杂性和多样性,如何从真实世界中精准捕捉手与物体交互的完整状态,成为推动人形机器人操作技能学习的关键所在。
来自主题: AI技术研报
7804 点击 2024-11-14 14:30
 搜索
搜索
随着人形机器人技术的迅猛发展,如何有效获取高质量的操作数据成为核心挑战。鉴于人类操作行为的复杂性和多样性,如何从真实世界中精准捕捉手与物体交互的完整状态,成为推动人形机器人操作技能学习的关键所在。
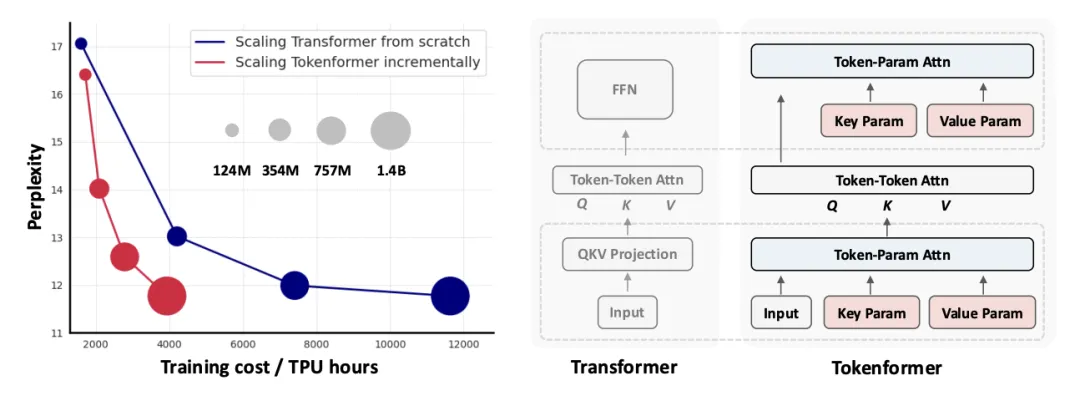
新一代通用灵活的网络结构 TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters 来啦!

随着大语言模型(LLMs)在处理复杂任务中的广泛应用,高质量数据的获取变得尤为关键。为了确保模型能够准确理解并执行用户指令,模型必须依赖大量真实且多样化的数据进行后训练。然而,获取此类数据往往伴随着高昂的成本和数据稀缺性。因此,如何有效生成能够反映现实需求的高质量合成数据,成为了当前亟需解决的核心挑战。

30多年的数学猜想首次获得了进展!Meta等学者提出的PatternBoost,使用Transformer构造了一个反例,反驳了一个已悬而未决30年的猜想。是否所有数学问题都适合机器学习技术?这样的未来太令人期待了。

GenXD模型结合CamVid-30K数据集突破了3D和4D场景生成的挑战,能从单张图片生成逼真的动态3D和4D场景。这一进展为虚拟世界构建带来新的可能性,让动态场景的生成更加快速和真实。

从文字生成三维世界的场景有多难?

世界模型又出新进展了,来自国内机构。

连续学习(CL)旨在增强机器学习模型的能力,使其能够不断从新数据中学习,而无需进行所有旧数据的重新训练。连续学习的主要挑战是灾难性遗忘:当任务按顺序训练时,新的任务训练会严重干扰之前学习的任务的性能,因为不受约束的微调会使参数远离旧任务的最优状态。

如何更好地设计提示词(Prompt)一直是大家关注的焦点。最近,一个独特的研究视角引起了广泛关注:将LLMs视为“演员”,将提示词视为“剧本”,将模型输出视为“表演”。

最近几天,AI 社区都在讨论同一篇论文。 UCSD 助理教授 Dan Fu 说它指明了大模型量化的方向。

“过去24个月,AI行业发生的最大变化是什么?是大模型基本消除了幻觉。”11月12日,百度创始人李彦宏在百度世界2024大会上,发表了主题为《应用来了》的演讲,发布两大赋能应用的AI技术:检索增强的文生图技术(iRAG)和无代码工具“秒哒”。文心iRAG用于解决大模型在图片生成上的幻觉问题,极大提升实用性;无代码工具“秒哒”让每个人都拥有程序员的能力,将打造数百万“超级有用”的应用。

人工智能的发展如火如荼,但大多数人只看到应用的火爆。真正的支撑力量鲜为人知,人工智能的发展越来越离不开庞大算力的支撑。现在,每5座为人工智能而生的数据中心所消耗的电力,就相当于一个纽约市的消耗。本文将介绍关于AI数据中心的一些基础知识。

小米大模型第二代来了! 相比第一代,训练数据规模更大、品质更高,训练策略与微调机制上也进行了深入打磨。

研究人员通过案例研究,利用大型语言模型(LLMs)如GPT-4、Claude 3和Llama 3.1,探索了思维链(CoT)提示在解码移位密码任务中的表现;CoT提示虽然提升了模型的推理能力,但这种能力并非纯粹的符号推理,而是结合了记忆和概率推理的复杂过程。

第8届CoRL于2024年11月6日至9日在德国慕尼黑举行,展示了机器人学习领域的前沿研究和发展,尤其是在自主系统、机器人控制和多模态人工智能领域。
昨天,The Information 的一篇文章让 AI 社区炸了锅。

2024 年的诺贝尔化学奖颁发给了在结构生物学领域取得重大成就的 David Baker 团队和 AlphaFold 团队,激发了 AI for science 领域新的研究热潮。

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
【新智元导读】刚刚,一款专为消费级显卡设计的全新非自回归掩码图像建模的文本到图像生成模型——Meissonic发布,标志着图像生成即将进入「端侧时代」。
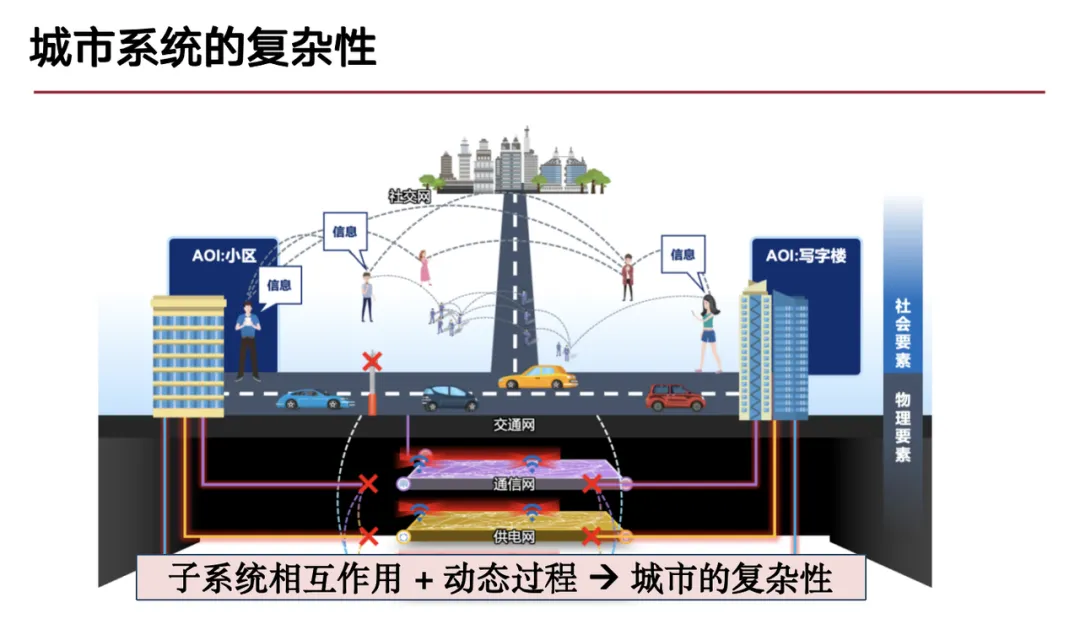
在 HyperAI超神经联合出品的 COSCon’24 AI for Science 论坛中,来自清华大学电子工程系城市科学与计算研究中心的博士后研究员丁璟韬带来了深度分享,以下为演讲精华实录。

OpenAI推出SearchGPT没几天,开源版本也来了。 港中文MMLab、上海AI Lab、腾讯团队简易实现了Vision Search Assistant,模型设计简单,只要两张RTX3090就可复现。
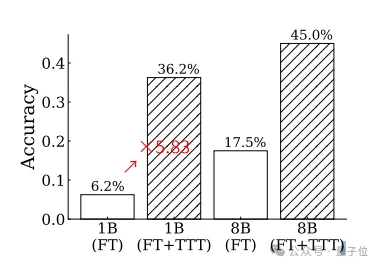
o1不是通向大模型推理的唯一路径! MIT的新研究发现,在测试时对大模型进行训练,可以让推理水平大幅提升。
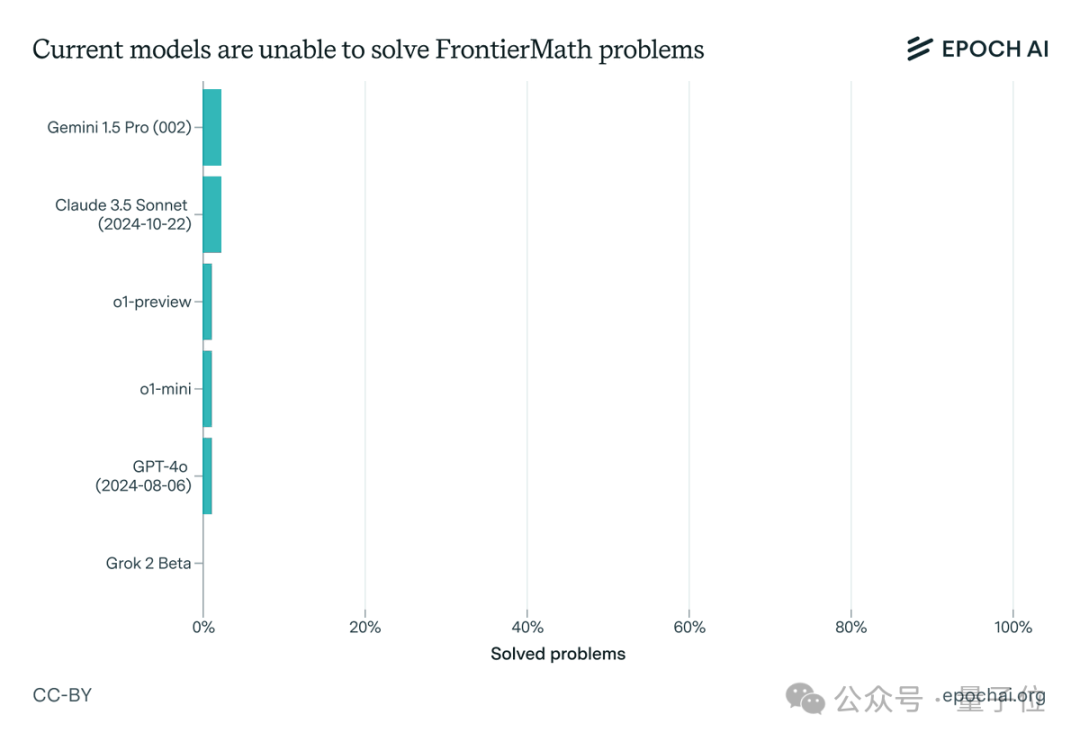
让大模型集体吃瘪,数学题正确率通通不到2%!
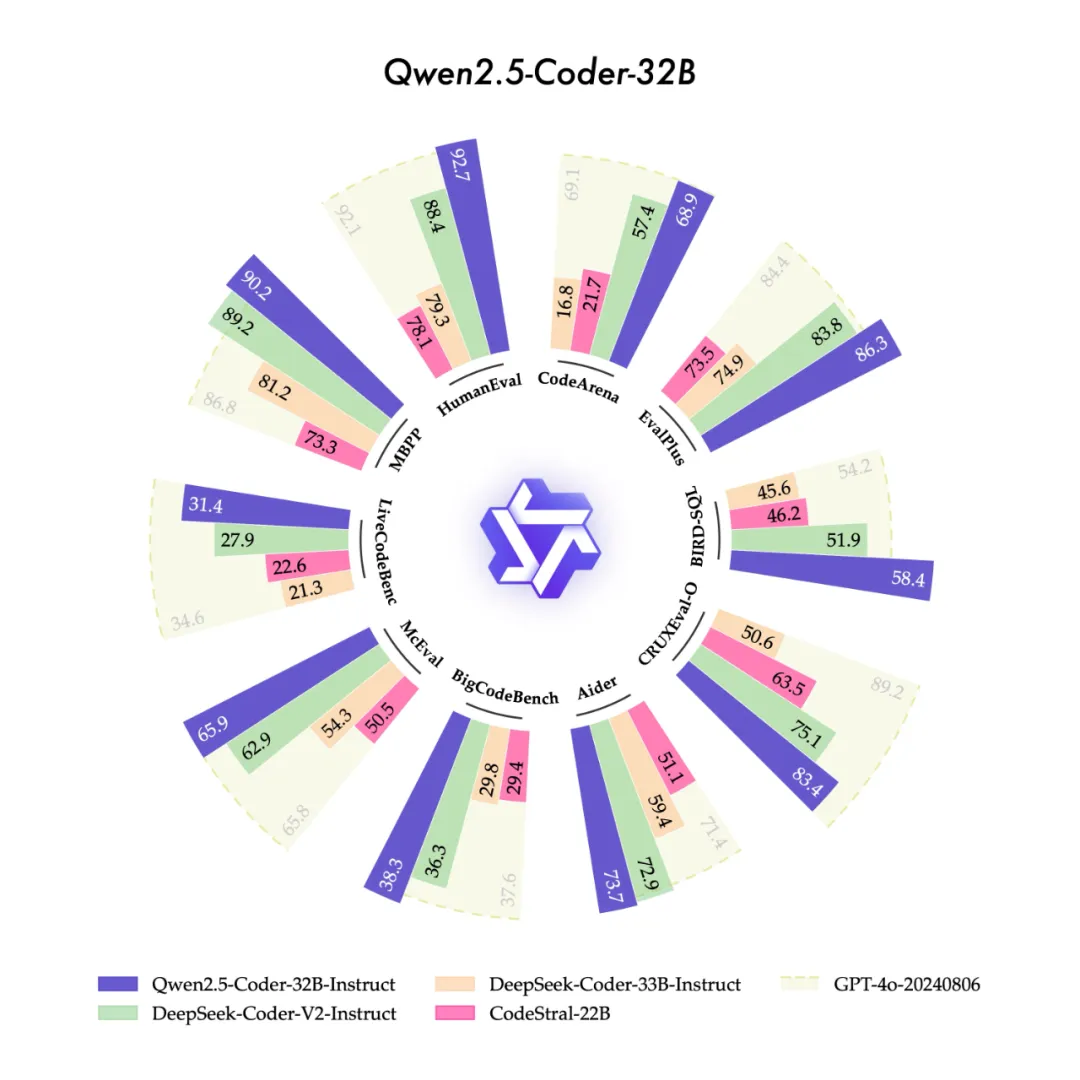
今天,我们很高兴开源“强大”、“多样”、“实用”的Qwen2.5-Coder全系列模型,致力于持续推动Open CodeLLMs的发展。
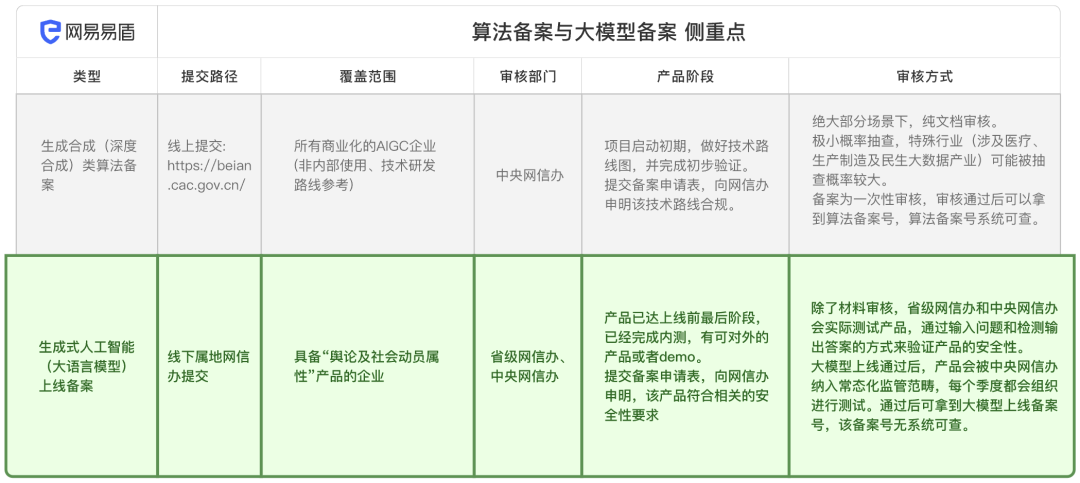
算法备案是所有AI从业者不得不迈过的门槛。这篇内容深入解读了中国《生成式人工智能服务安全基本要求》以及“生成式人工智能(大语言模型)上线备案”流程。

在当前AI写作工具迅速发展的背景下,华盛顿大学的这项研究选择了一个独特的切入点。研究团队没有去探讨AI是否应该用于创意写作这个争议性话题,而是直接走进了那些已经在使用AI的作家的创作现场。这18位作家来自不同背景:

现在,用LLM一键就能生成百万级领域知识图谱了?! 来自中科大MIRA实验室研究人员提出一种通用的自动化知识图谱构建新框架SAC-KG

大模型理解复杂表格,能力再次飞升了! 不仅能在不规则表格中精准找到相关信息,还能直接进行计算。
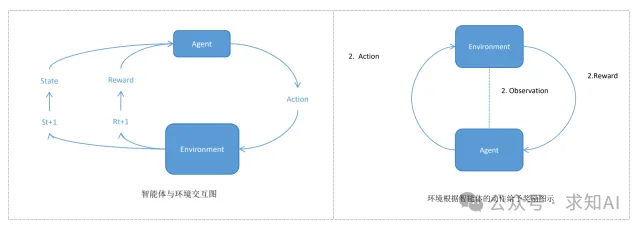
强化学习中的核心概念是智能体(Agent)和环境(Environment)之间的交互。智能体通过观察环境的状态,选择动作来改变环境,环境根据动作反馈出奖励和新的状态。