
MVDrag3D:灵活强大的拖拽式多视图3D编辑技术
MVDrag3D:灵活强大的拖拽式多视图3D编辑技术MVDrag3D 是一种创新的3D编辑框架,它通过结合多视图生成和重建先验来实现灵活且富有创造性的拖拽编辑。
来自主题: AI技术研报
4743 点击 2024-11-05 09:38
 搜索
搜索
MVDrag3D 是一种创新的3D编辑框架,它通过结合多视图生成和重建先验来实现灵活且富有创造性的拖拽编辑。

OpenAI o1彻底带火慢思考和思维链(CoT)方法,但CoT在某些任务上反而会降低模型表现。

大家对in-context learning(ICL)的能力可能已经很熟悉了,您通常会通过上下文示例就能快速让prompt适应新任务。然而,作为AI应用开发者,您是否思考过:为什么有时候精心设计的few-shot prompt会失效?为什么相同的prompt模式在不同场景下效果差异巨大?

来自中科大等单位的研究团队共同提出了用来有效评估多模态大模型预训练质量的评估指标 Modality Integration Rate(MIR),能够快速准确地评估多模态预训练的模态对齐程度。

利用语言模型调用工具,是实现通用目标智能体(general-purpose agents)的重要途径,对语言模型的工具调用能力提出了挑战。

来自英伟达、CMU、UC伯克利等的全华人团队提出一个全新的人形机器人通用的全身控制器HOVER,仅用一个1.5M参数模型就可以控制人形机器人的身体。人形机器人的运动和操作之前只是外表看起来类人,现在有了HOVER,连底层运动逻辑都可以类人了!
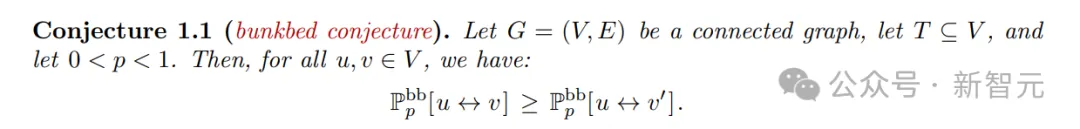
39年来一个看似理所当然的数学理论,刚刚被数学家证伪!UCLA和MIT的研究者证实:概率论中众所周知的假设「上下铺猜想」是错的。有趣的是,他们用AI已经证明到了99.99%的程度,但最终,靠的还是理论论证。

人类只需要演示五次,就能让机器人学会一项复杂技能。英伟达实验室,提出了机器人训练数据缺乏问题的新解决方案——DexMimicGen。
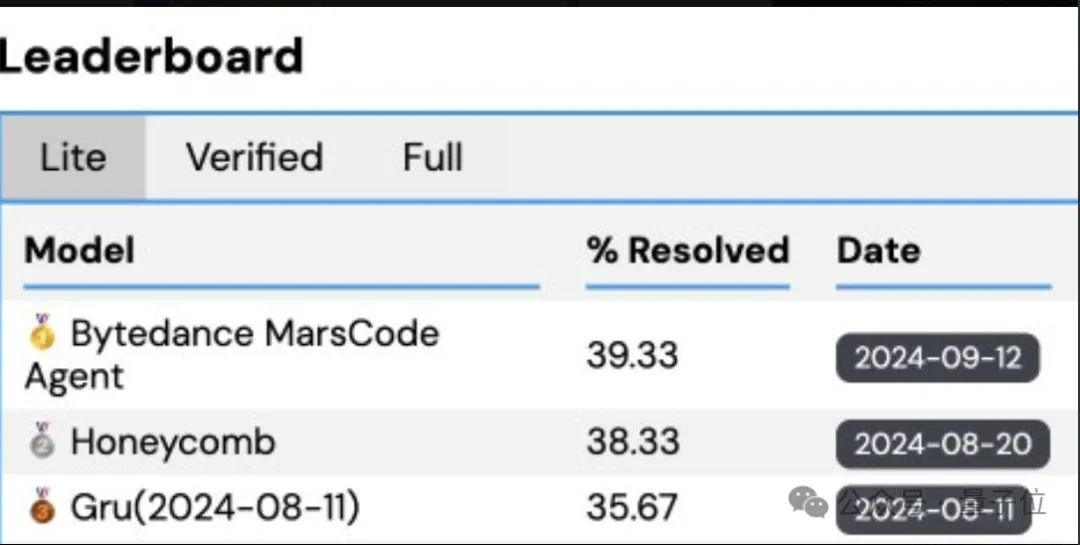
解决真实GitHub Issue的基准测试,字节家的豆包MarsCode Agent悄悄登顶了。SWE-Bench,一个由普林斯顿大学提出的极具挑战性的Benchmark,近期受到工业界、学术界和创业团队的广泛关注。

与最先进的开源方法甚至闭源模型 GPT-4o 相比,MMedAgent 在各种医疗任务中实现了卓越的性能。此外,MMedAgent 在更新和集成新医疗工具方面表现出效率。
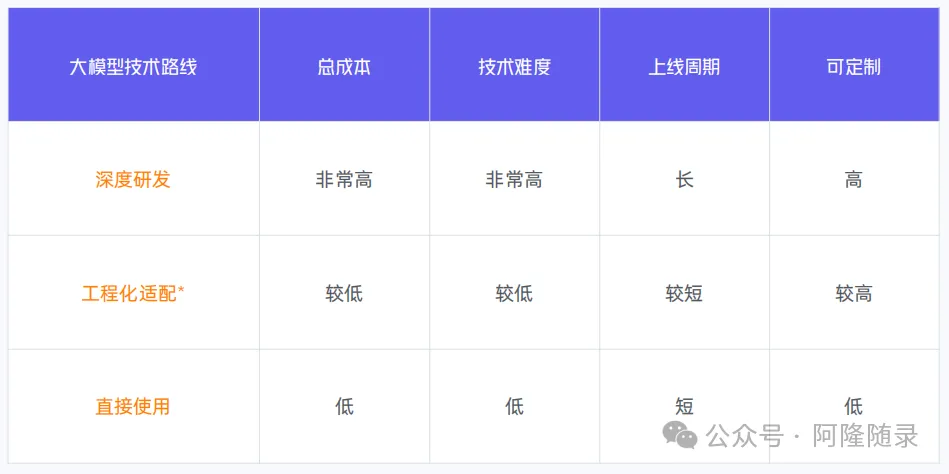
中国企业对于生成式AI应用场景的了解都来自于ChatGPT的传说,但中国企业能使用的GenAI资源与ChatGPT却没有关系。直截了当地说,中国企业目前能够使用的GenAI资源都比GPT-4要差很多,注意不是“有差距”,而是“差很多”,这是中国企业考虑生成式AI问题的基本前提。

RAG,AI,模型训练,人工智能

在人工智能领域,大型预训练模型(如 GPT 和 LLaVA)的 “幻觉” 现象常被视为一个难以克服的挑战,尤其是在执行精确任务如图像分割时。

AI,LLM,模型训练,人工智能

AI技术日新月异,像Netflix这样的大公司已经开始用AI制作特效,而新的AI模型也在游戏和科学研究中超越了人类。未来一年,我们可能会看到没有编程技能的人也能创造热门应用,甚至AI创作的歌曲也可能登上音乐排行榜前十。
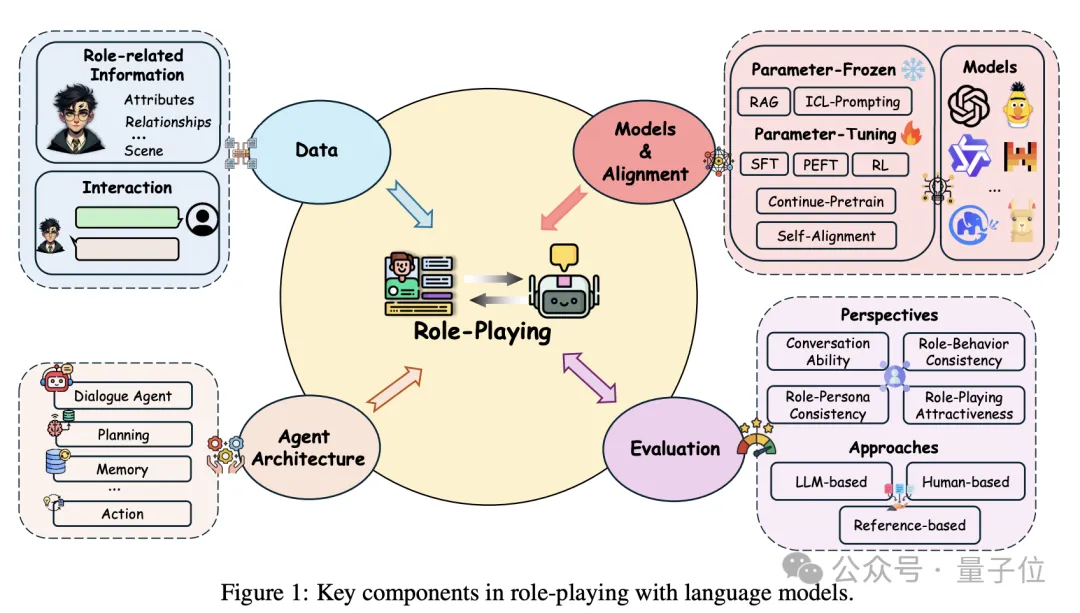
AI界也有了自己的“奥斯卡”,哪家大模型角色扮演更入戏? 来自香港科技大学、腾讯、新加坡管理大学的团队提出新综述—— 不仅系统性地回顾了角色扮演语言模型的发展历程,还对每个阶段的关键进展进行了深入剖析,展示了这些进展如何推动模型逐步实现更复杂、更逼真的角色扮演。

Transformer自问世后就大放异彩,但有个小毛病一直没解决: 总爱把注意力放在不相关的内容上,也就是信噪比低。 现在微软亚研院、清华团队出手,提出全新改进版Differential Transformer,专治这个老毛病,引起热议。

中国科学院上海营养与健康研究所李虹研究组多年来在抗癌药物疗效建模方向持续深耕,发表了基于分子组学预测药物响应和肝癌药物基因组相关的系列论文。但前期研究表明肿瘤用药的计算分析仍存在诸多挑战,例如:肿瘤临床前模型和病人存在差异,计算模型缺乏泛化能力;药物组合的作用机制复杂搜索空间大,对药物联用协同效果的准确和稳健估计仍很困难。
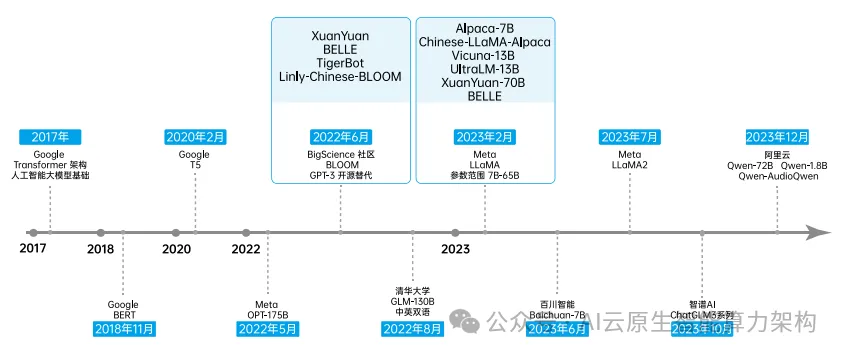
随着开源技术占据各大新兴领域的技术路线,其不断丰富人工智能领域的应用场景。 2023年,Meta 相继发布 Llama 和 Llama2,很快成为广受欢迎的开源大模型,也成为许多模型的基座模型。

改进KV缓存压缩,大模型推理显存瓶颈迎来新突破—— 中科大研究团队提出Ada-KV,通过自适应预算分配算法来优化KV缓存的驱逐过程,以提高推理效率。

只要一个3B参数的大模型,就能控制机器人,帮你搞定各种家务。 叠衣服冲咖啡都能轻松拿捏,而且全都是由模型自主控制,不需要遥控。 关键是,这还是个通用型的机器人控制模型,不同种类的机器人都能“通吃”。

MPDS(Movie Posters Dataset)是一个创新的电影海报数据集,旨在解决现有图像生成模型在制作电影海报时面临的挑战。

Allegro 是一款先进的商业级视频生成模型,由Rhymes AI团队开发。它通过将描述性文本转换为动态视觉内容,为用户提供了一种灵活且可控的视频创作方法。

随着扩散生成模型的发展,人工智能步入了属于 AIGC 的新纪元。扩散生成模型可以对初始高斯噪声进行逐步去噪而得到高质量的采样。当前,许多应用都涉及扩散模型的反演,即找到一个生成样本对应的初始噪声。当前的采样器不能兼顾反演的准确性和采样的质量。

多图像场景也能用DPO方法来对齐了! 由上海交大、上海AI实验室、港中文等带来最新成果MIA-DPO。 这是一个面向大型视觉语言模型的多图像增强的偏好对齐方法。
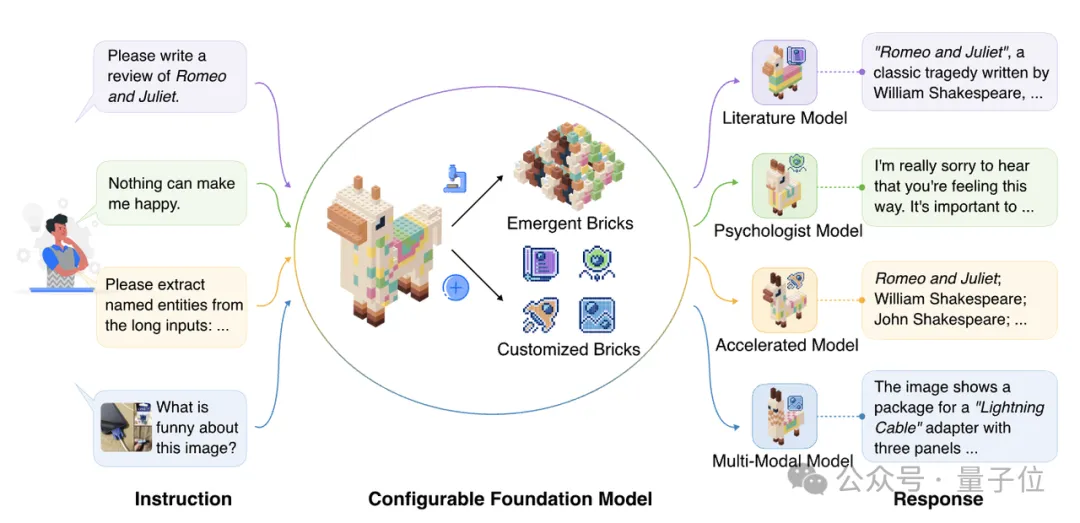
探索更高效的模型架构, MoE是最具代表性的方向之一。 MoE架构的主要优势是利用稀疏激活的性质,将大模型拆解成若干功能模块,每次计算仅激活其中一小部分,而保持其余模块不被使用,从而大大降低了模型的计算与学习成本,能够在同等计算量的情况下产生性能优势。

本文介绍了一种自动化故事可视化系统,可以生成多样化、高质量、一致性强的故事图像,且需要最少的人工干预。

CGPO框架通过混合评审机制和约束优化器,有效解决了RLHF在多任务学习中的奖励欺骗和多目标优化问题,显著提升了语言模型在多任务环境中的表现。CGPO的设计为未来多任务学习提供了新的优化路径,有望进一步提升大型语言模型的效能和稳定性。

强化学习(RL)对大模型复杂推理能力提升有关键作用,然而,RL 复杂的计算流程以及现有系统局限性,也给训练和部署带来了挑战。

对于人类而言,一旦掌握了 “打开瓶盖” 的动作,面对 “拧紧螺丝” 这样的任务通常也能游刃有余,因为这两者依赖于相似的手部动作。然而,对于机器人来说,即使是这样看似简单的任务转换依然充满挑战。例如,换成另一种类型的瓶盖,机器人可能无法成功打开。这表明,目前的机器人方法尚未充分让模型学习到任务的内在执行逻辑,而只是单纯的依赖于数据拟合。