
生存还是死亡?当AI成为生死判官,「心理数字孪生」为失语患者做出临终抉择
生存还是死亡?当AI成为生死判官,「心理数字孪生」为失语患者做出临终抉择伦理学家们正在推进一项极具颠覆性且备受争议的事业——让AI帮助病患家属做出临终决定,这个「技术上可行,伦理上可取」的人工智能工具,在未来几个月内可能就会到来。
来自主题: AI技术研报
9436 点击 2024-09-02 16:43
 搜索
搜索
伦理学家们正在推进一项极具颠覆性且备受争议的事业——让AI帮助病患家属做出临终决定,这个「技术上可行,伦理上可取」的人工智能工具,在未来几个月内可能就会到来。

AnyGraph聚焦于解决图数据的核心难题,跨越多种场景、特征和数据集进行预训练。其采用混合专家模型和特征统一方法处理结构和特征异质性,通过轻量化路由机制和高效设计提升快速适应能力,且在泛化能力上符合Scaling Law。
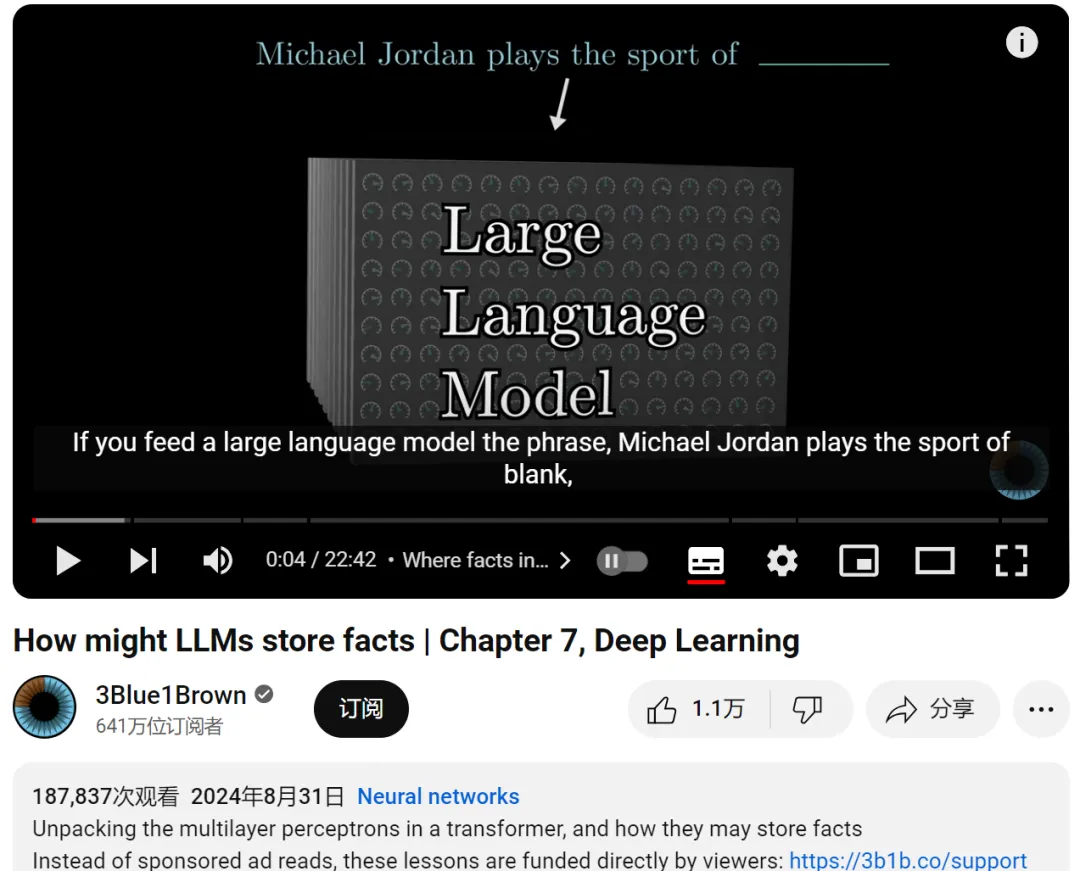
向大模型输入「Michael Jordan plays the sport of _____(迈克尔・乔丹从事的体育运动是……)」,然后让其预测接下来的文本,那么大模型多半能正确预测接下来是「basketball(篮球)」。

又有AI初创公司创始人卖身大厂——

GPU功耗高,不适边缘计算;多种AI硬件适应边缘应用。
基于公司私有组件生成代码,这个问题的本质是:由于大模型的训练数据集不包含你公司的私有组件数据,因此不能够生成符合公司私有组件库的代码。

该论文作者来自复旦大学、中电金信及上海智能视觉计算协同创新中心团队,论文已被多媒体领域顶级国际会议 ACM MultiMedia 2024 接收,并将在该大会上进行口头报告(Oral 接收率仅 3.97%)。

斯坦福和NYU的研究者发现,GPT-4这样的「AI人」,可以被用来复制社会科学实验了。调查了1万个AI,结果比真人还真?

老牌芯片巨头英特尔,再失一位半导体行业老将。最近,陈立武宣布辞去董事会一职,因对公司官僚主义、规避风险文化感到沮丧,并在中层裁员意见上出现分歧。消息一出公司股价暴跌6%,现如今市值不过千亿美金。

微软和OpenAI投资的人形机器人公司,又上新了!

长时间交通状况预测,可以用大模型实现了。

大模型竞技场规则更新,GPT-4o mini排名立刻雪崩,跌出前10。

本文第一作者为香港大学博士研究生谢知晖,主要研究兴趣为大模型对齐与强化学习。

Transformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transformer 也因此难以处理非常长的文本。

终于有了点赛博朋克的样子。

美国警察开始使用人工智能工具Draft One辅助文书工作,犯罪报告秒生成,比人脑回忆更准确。

尽管不断招兵买马,依旧挡不住OpenAI的安全团队「集体出走」。半数员工已离职、公司处在风口浪尖,奥特曼却在此时选择对内部员工展开安全监控。
太突然!也没有任何理由的!

罗盟,本工作的第一作者。新加坡国立大学(NUS)人工智能专业准博士生,本科毕业于武汉大学。主要研究方向为多模态大语言模型和 Social AI、Human-eccentric AI。

当前的大型语言模型似乎能够通过一些公开的图灵测试。我们该如何衡量它们是否像人一样聪明呢?

在人工智能重塑各个行业的今天,法律界也迎来了前所未有的变革。传统的法律实践面临着效率低下、成本高昂等挑战,而AI技术的出现为解决这些问题提供了新的可能。

GPT-4o能挂在脖子上了?还能当手环、别在口袋上,实时AI转录。

免费的AI视频通话功能,就这么水灵灵地来了。

AI 硬件领域最近掀起一波小高潮。
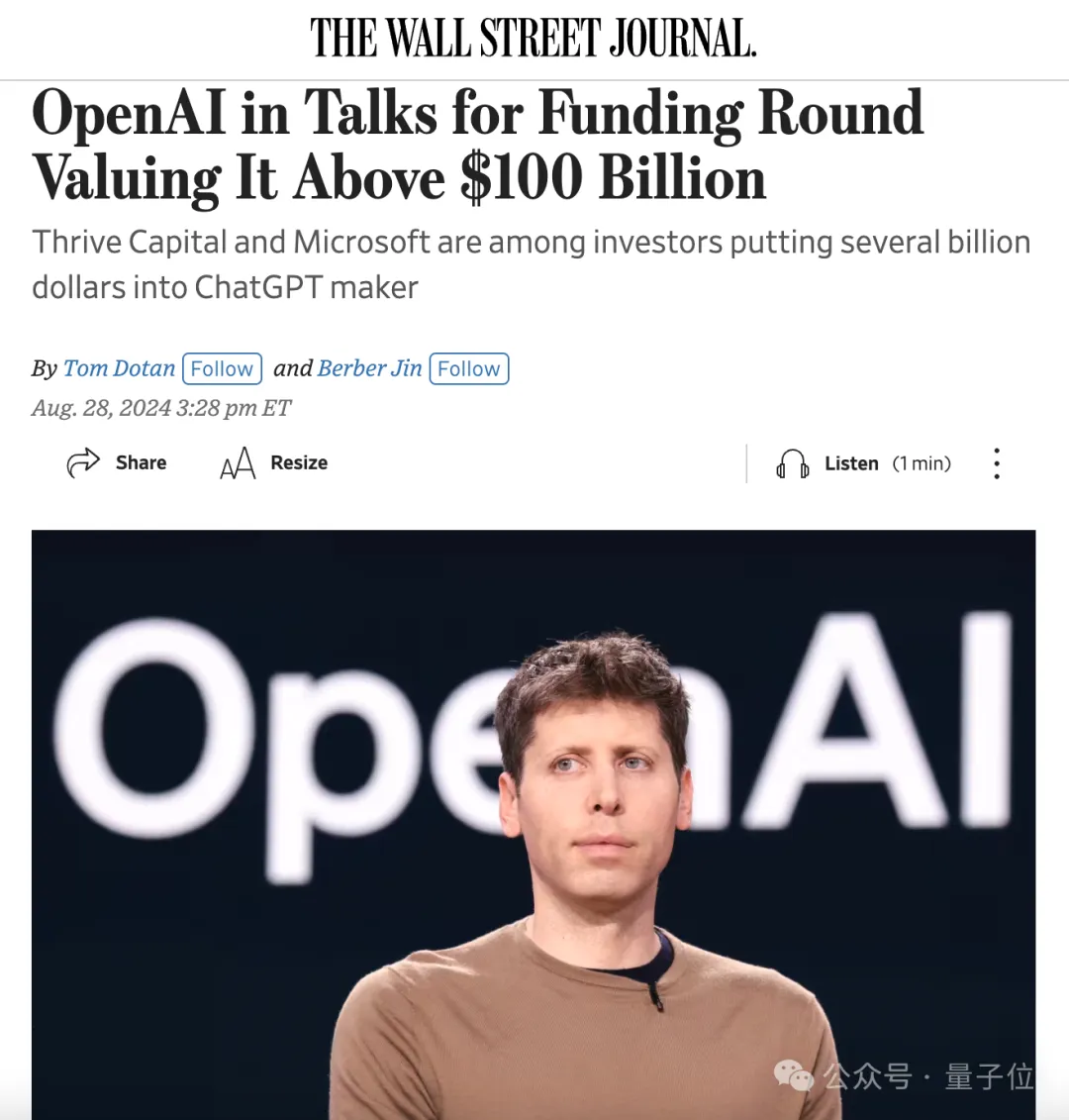
OpenAI估值,超1000亿美元!
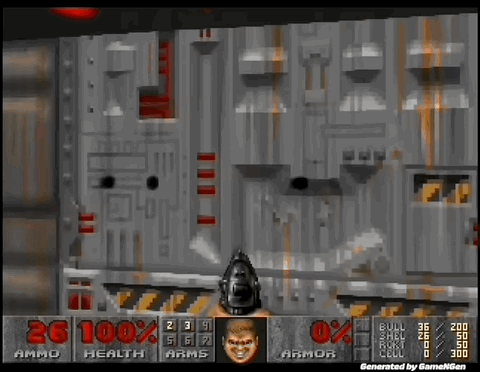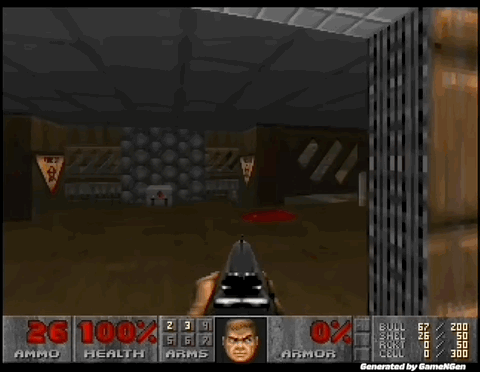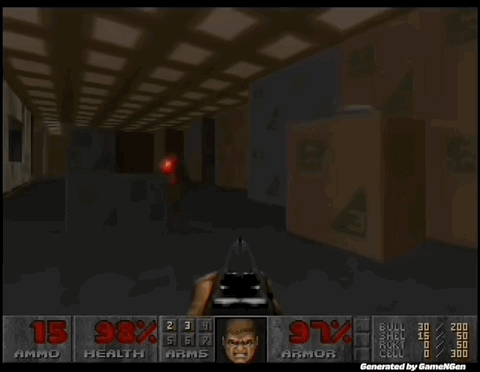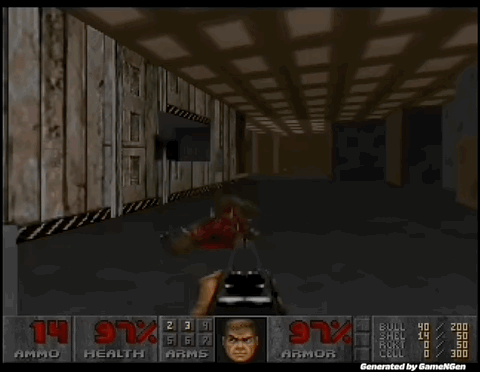
“比Sora还震撼”,AI可以实时生成游戏了!
我一直认为人工智能将改变世界,但我们总是不得不面对技术的局限性和不确定性。因此我们需要弄清楚今天行之有效的方法,同时不忘展望明天。

让AI像人类一样借助多模态线索定位感兴趣的物体,有新招了!
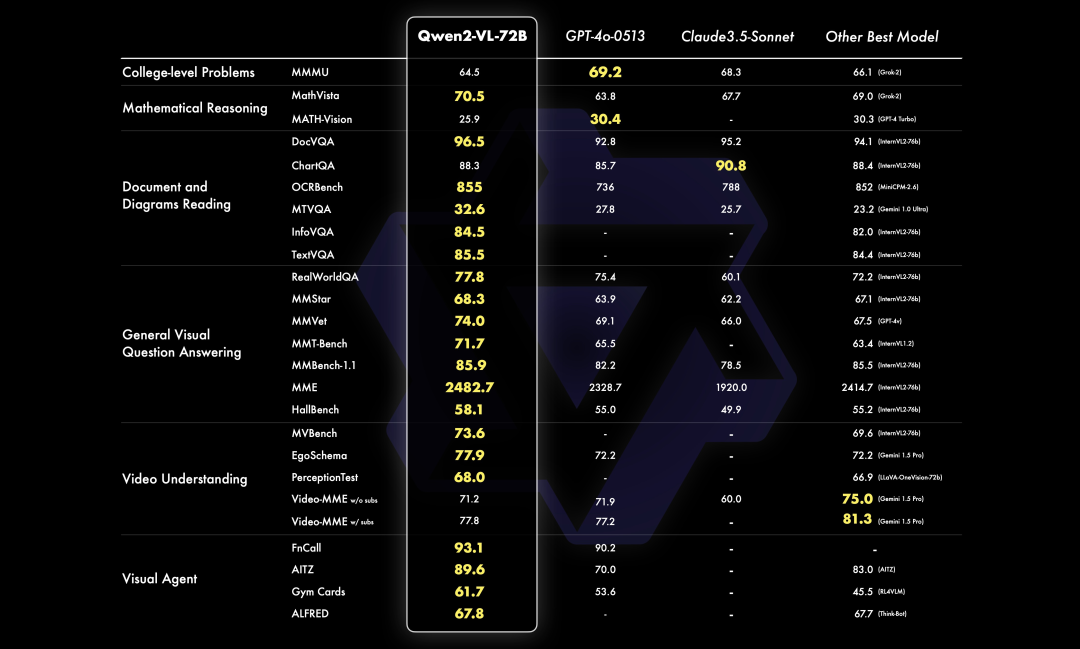
新的最强开源多模态大模型来了!

现有的大模型已经能够创作令人惊叹画作,那鉴赏艺术画作岂不是信手拈来?