
几分钟生成四维内容,还能控制运动效果:北大、密歇根提出DG4D
几分钟生成四维内容,还能控制运动效果:北大、密歇根提出DG4D近期,商汤科技 - 南洋理工大学联合 AI 研究中心 S-Lab ,上海人工智能实验室,北京大学与密歇根大学联合提出 DreamGaussian4D(DG4D),通过结合空间变换的显式建模与静态 3D Gaussian Splatting(GS)技术实现高效四维内容生成。
来自主题: AI技术研报
9340 点击 2024-07-09 17:27
 搜索
搜索
近期,商汤科技 - 南洋理工大学联合 AI 研究中心 S-Lab ,上海人工智能实验室,北京大学与密歇根大学联合提出 DreamGaussian4D(DG4D),通过结合空间变换的显式建模与静态 3D Gaussian Splatting(GS)技术实现高效四维内容生成。
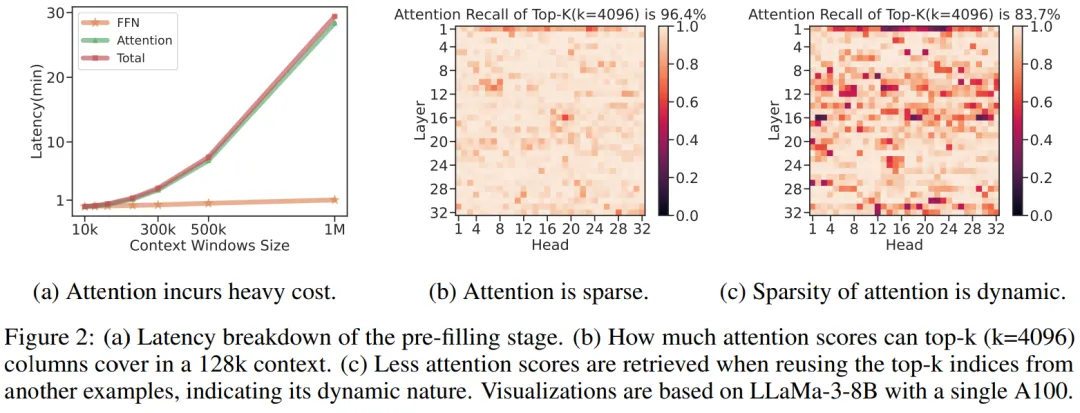
微软的这项研究让开发者可以在单卡机器上以 10 倍的速度处理超过 1M 的输入文本。

生物神经网络有一个重要的特点是高度可塑性,这使得自然生物体具有卓越的适应性,并且这种能力会影响神经系统的突触强度和拓扑结构。

SelfGNN框架结合了图神经网络和个性化自增强学习,能够捕捉用户行为的多时间尺度模式,降低噪声影响,提升推荐系统鲁棒性。
下一代视觉模型会摒弃patch吗?Meta AI最近发表的一篇论文就质疑了视觉模型中局部关系的必要性。他们提出了PiT架构,让Transformer直接学习单个像素而不是16×16的patch,结果在多个下游任务中取得了全面超越ViT模型的性能。

来自佐治亚理工学院和英伟达的两名华人学者带队提出了名为RankRAG的微调框架,简化了原本需要多个模型的复杂的RAG流水线,用微调的方法交给同一个LLM完成,结果同时实现了模型在RAG任务上的性能提升。

超越Transformer和Mamba的新架构,刚刚诞生了。斯坦福UCSD等机构研究者提出的TTT方法,直接替代了注意力机制,语言模型方法从此或将彻底改变。

新架构,再次向Transformer发起挑战!

6月,IEEE刊登了一篇对ChatGPT代码生成任务进行系统评估的论文,数据集就是程序员们最爱的LeetCode题库。研究揭示了LLM在代码任务中出现的潜在问题和能力局限,让我们能够对模型做出进一步改进,并逐渐了解使用ChatGPT写代码的最佳姿势。

冲锋在AI辅助数学研究第一线的陶哲轩,近日又有「神总结」:ChatGPT提升的,是我们在编码、图表等次要任务上的能力;而真要搞好数学研究,基础不扎实的话,AI也是没用的。

给大模型加上第三种记忆格式,把宝贵的参数从死记硬背知识中解放出来!

批评不仅能让人进步,也能让大模型的能力提升。
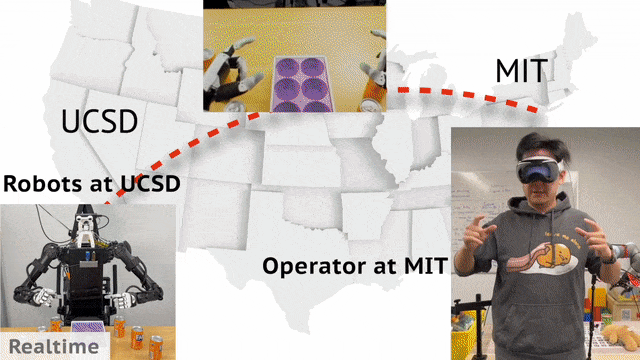
现实中,机器人收据收集可以通过远程操控实现。来自UCSD、MIT的华人团队开发了一个通用框架Open-TeleVision,可以让你身临其境操作机器人,即便相隔3000英里之外。

ChatGPT能耗惊人,该怎么解?谷歌DeepMind新算法JEST问世,让LLM训练的迭代次数降低13倍,计算量减少10倍,或将重塑AI未来。

基于 ChatGPT、LLAMA、Vicuna [1, 2, 3] 等大语言模型(Large Language Models,LLMs)的强大理解、生成和推理能力

想象一下你在刷短视频,系统想要推荐你可能会喜欢的内容。
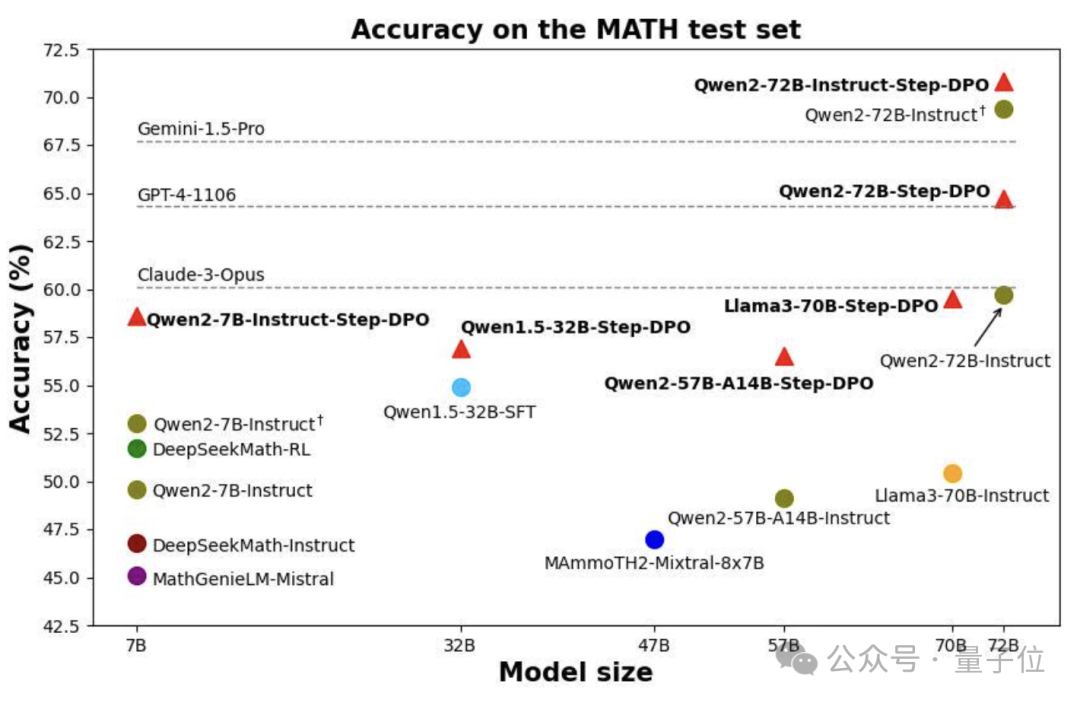
只要10k数据,就能让大模型的数学成绩增长5.6%。
搜索技术是计算机科学中最难的技术挑战之一,迄今只有很少一部分商业化产品可以把这个问题解决得很好。大多数商品并不需要很强的搜索,因为这和用户体验并没有直接关系。
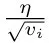
在训练大型语言模型(LLM)时,Adam(W) 基本上已经成为了人们默认使用的优化器。

近日,来自谷歌DeepMind的研究人员,推出了专门用于评估大语言模型时间推理能力的基准测试——Test of Time(ToT),从两个独立的维度分别考察了LLM的时间理解和算术能力。

大语言模型有道德推理能力吗?不仅有,甚至可能在道德推理方面超越普通人和专家学者!最新研究发现:GPT-4o针对道德难题给出的建议比人类专家更让人信服。

荷兰拉德布德大学的研究团队通过定位大脑注意力机制,在AI「读心术」领域精确生成图像,能够依据大脑活动记录极为准确地重建猕猴所看到的内容。网友:这是人机融合的最终目标。

视频生成赛道又起新秀,而且还是二次元定制版!稳定产出电影级画面,一键文/图生成视频,即使是「手残党」也能复刻自己喜欢的动漫作品了。

大模型当上福尔摩斯,学会对视频异常进行检测了。 来自华中科技大学、百度、密歇根大学的研究团队,提出了一种可解释性的视频异常检测框架,名为Holmes-VAD。
月之暗面和清华KVCache.ai团队的最新论文,首次揭秘了Kimi背后的推理架构! 要知道Kimi是国产大模型的当红炸子鸡,火到可以说从来没缺过流量,甚至还经常出现过载。

该文章的作者团队来自于斯坦福大学,共同第一作者团队Mert Yuksekgonul,Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang

只有10亿参数的xLAM-1B在特定任务中击败了LLM霸主:OpenAI的GPT-3.5 Turbo和Anthropic的Claude-3 Haiku。上个月刚发布的苹果智能模型只有30亿参数,就连奥特曼都表示,我们正处于大模型时代的末期。那么,小语言模型(SLM)会是AI的未来吗?

开源大语言模型(LLM)百花齐放,为了让它们适应各种下游任务,微调(fine-tuning)是最广泛采用的基本方法。基于自动微分技术(auto-differentiation)的一阶优化器(SGD、Adam 等)虽然在模型微调中占据主流,然而在模型越来越大的今天,却带来越来越大的显存压力。

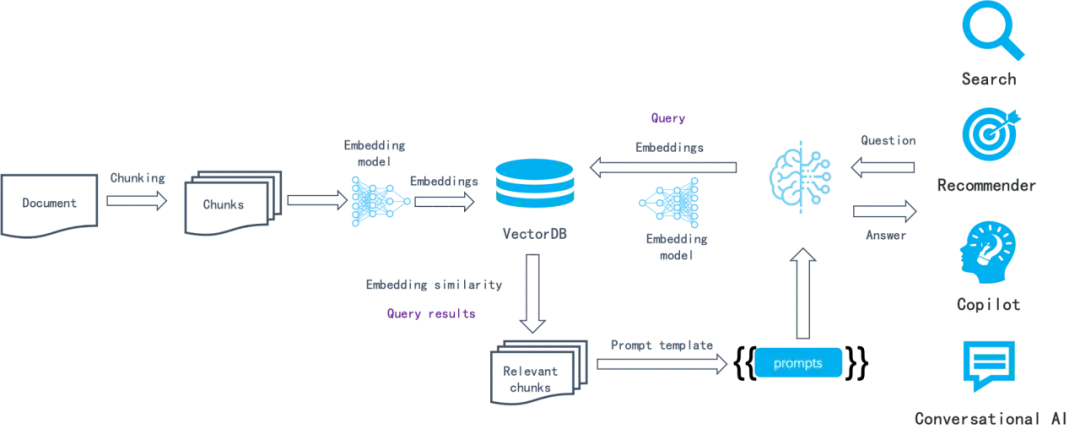
检索增强式生成(RAG)是一种使用检索提升语言模型的技术。

3D 生成,一直在等待它的「ChatGPT时刻」。