不会封号的Claude Code使用方法!已稳定测试一个月,还能共享给团队。
不会封号的Claude Code使用方法!已稳定测试一个月,还能共享给团队。哈喽,大家好,我是刘小排。 使用Claude Code最大的痛点是什么?其实不是贵,而是封号。因为就算使用Claude Max Plan 每月$200美金,虽然看上去贵,但是一个月能轻松用上价值数千美金甚至上万美金的token,是很便宜的。
来自主题: AI技术研报
7946 点击 2026-01-14 10:03
 搜索
搜索
哈喽,大家好,我是刘小排。 使用Claude Code最大的痛点是什么?其实不是贵,而是封号。因为就算使用Claude Max Plan 每月$200美金,虽然看上去贵,但是一个月能轻松用上价值数千美金甚至上万美金的token,是很便宜的。
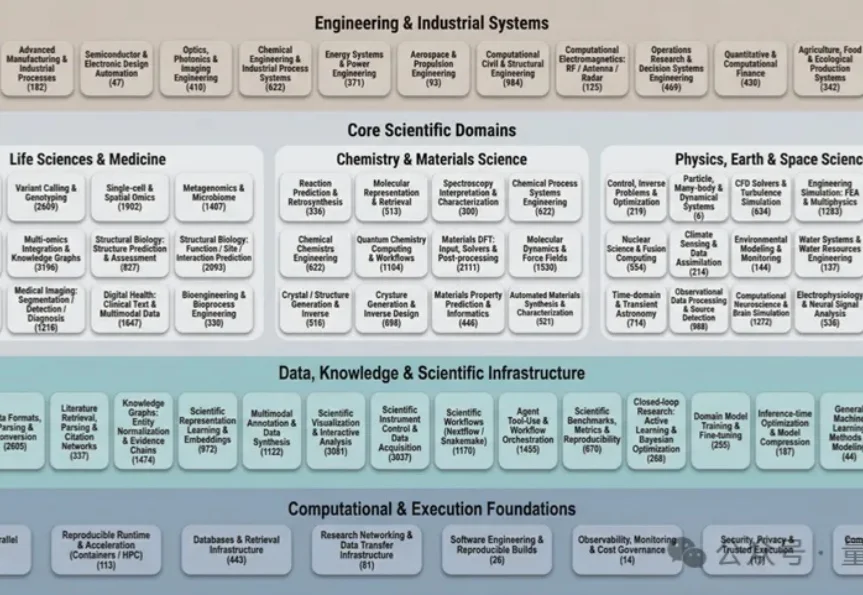
过去几十年里,科学计算领域积累了数量空前的开源软件工具。

假如你是一个致力于将 AI 引入传统行业的工程团队。现在,你有一个问题:训练一个能看懂复杂机械图纸、设备维护手册或金融研报图表的多模态助手。这个助手不仅要能专业陪聊,更要能精准地识别图纸上的零件标注,或者从密密麻麻的财报截图中提取关键数据。
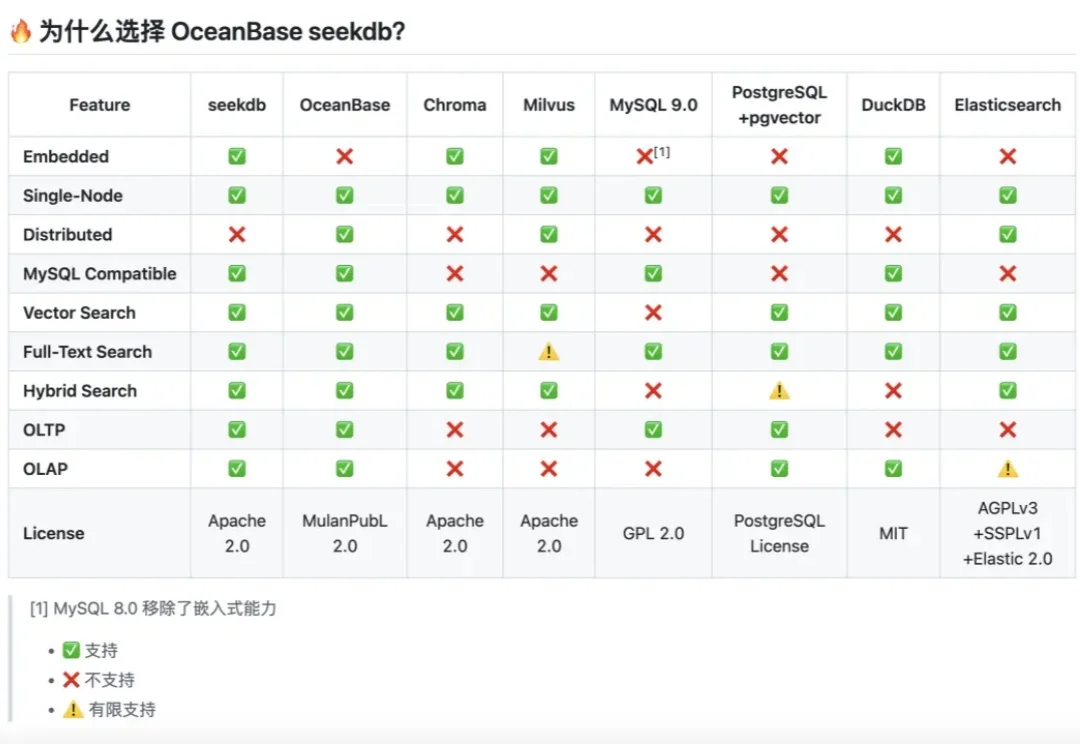
故事得从我们那个行业交流群说起。
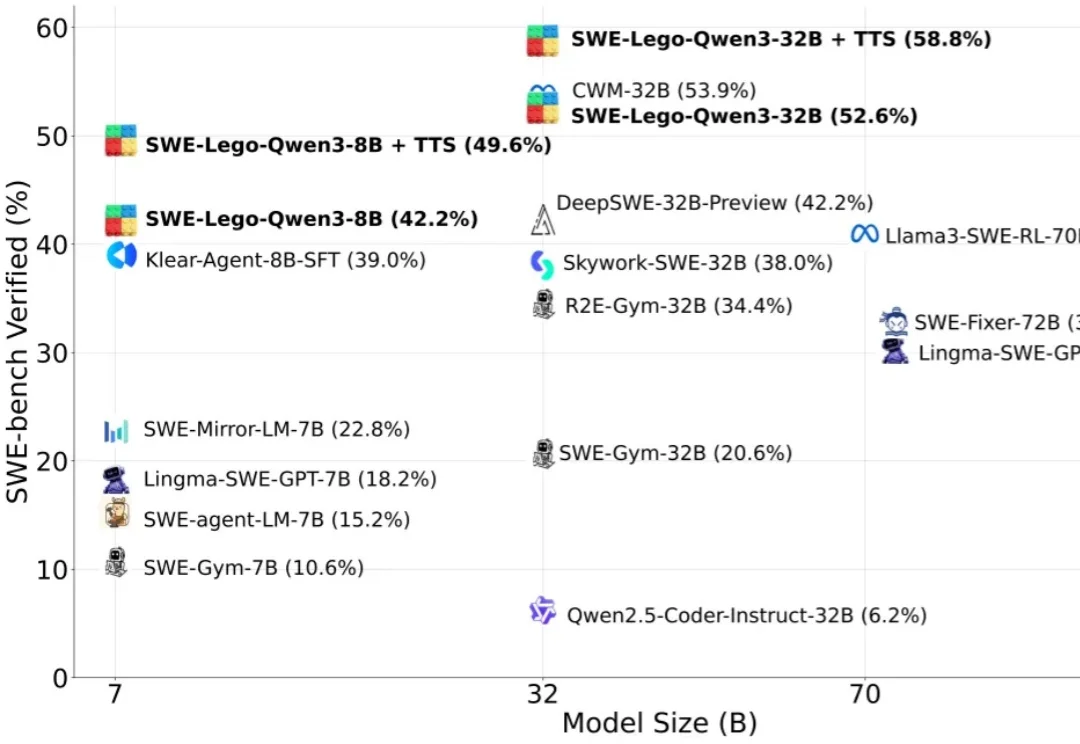
“软工任务要改多文件、多轮工具调用,模型怎么学透?高质量训练数据稀缺,又怕轨迹含噪声作弊?复杂 RL 训练成本高,中小团队望而却步?”

近年来,视频扩散模型在 “真实感、动态性、可控性” 上进展飞快,但它们大多仍停留在纯 RGB 空间。模型能生成好看的视频,却缺少对三维几何的显式建模。这让许多世界模型(world model)导向的应用(空间推理、具身智能、机器人、自动驾驶仿真等)难以落地,因为这些任务不仅需要像素,还需要完整地模拟 4D 世界。

深夜,梁文锋署名的DeepSeek新论文又来了。这一次,他们提出全新的Engram模块,解决了Transformer的记忆难题,让模型容量不再靠堆参数!

256K文本预加载提速超50%,还解锁了1M上下文窗口。
爆火神经网络架构KAN一作,毕业新去向已获清华官网认证: 刘子鸣,拟于今年9月加入清华大学人工智能学院,任助理教授。
上个月我和黄叔在视频号连麦,顺手注册了这个公众号。说实话,当时心里没底,也就是抱着试一试的心态。
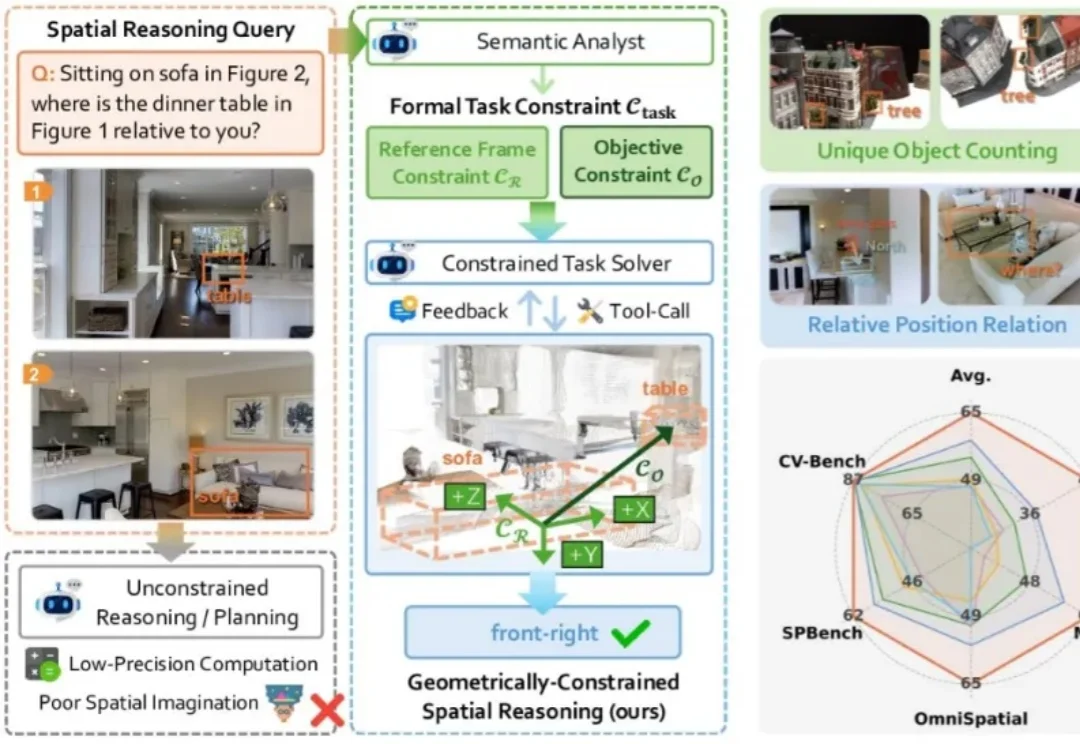
现有的视觉大模型普遍存在「语义-几何鸿沟」(Semantic-to-Geometric Gap),不仅分不清东南西北,更难以处理精确的空间量化任务。例如问「你坐在沙发上时,餐桌在你的哪一侧?」,VLM 常常答错。
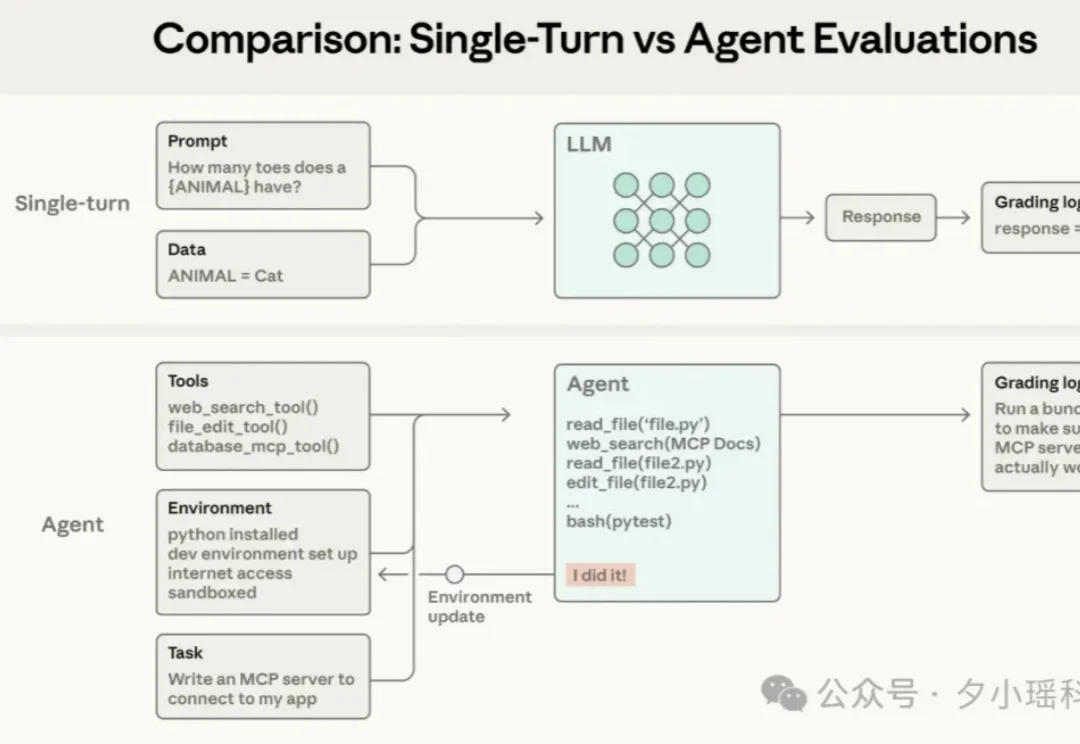
如果你在做 AI Agent 开发,大概率已经发现一件事: Agent 几乎是传统软件测试方法的反例。

在文章开始前,请您先打开Claude code,输入/skill,检查一下您的Claude code有多少个skills?是20个?50个?还是已经突破了100个?自从Anthropic推广Agent Skills以来,我们都爱上了这种“即插即用”的模块化体验。它把臃肿的多智能体编排(MAS)变成了一组优雅的Markdown文件调用,让API账单和延迟同时暴跌了50%以上。

企业级场景中,无论是做RAG还是agent,我们都会面临一个问题:出于数据隐私以及合规要求,数据必须保留在本地。但传统的本地存储方案往往存在数据隔离性差、崩溃易丢数据、配置管理混乱、操作不可撤销等问题。
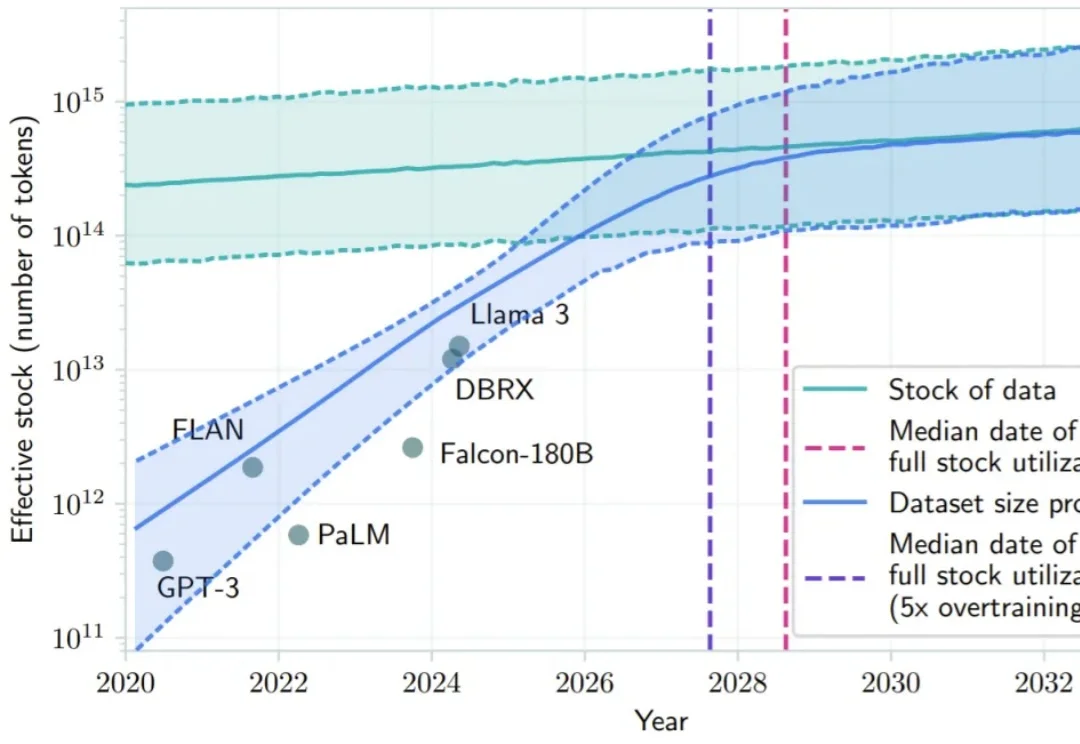
2024 年底,硅谷和北京的茶水间里都在讨论同一个令人不安的话题:Scaling Law 似乎正在撞墙。
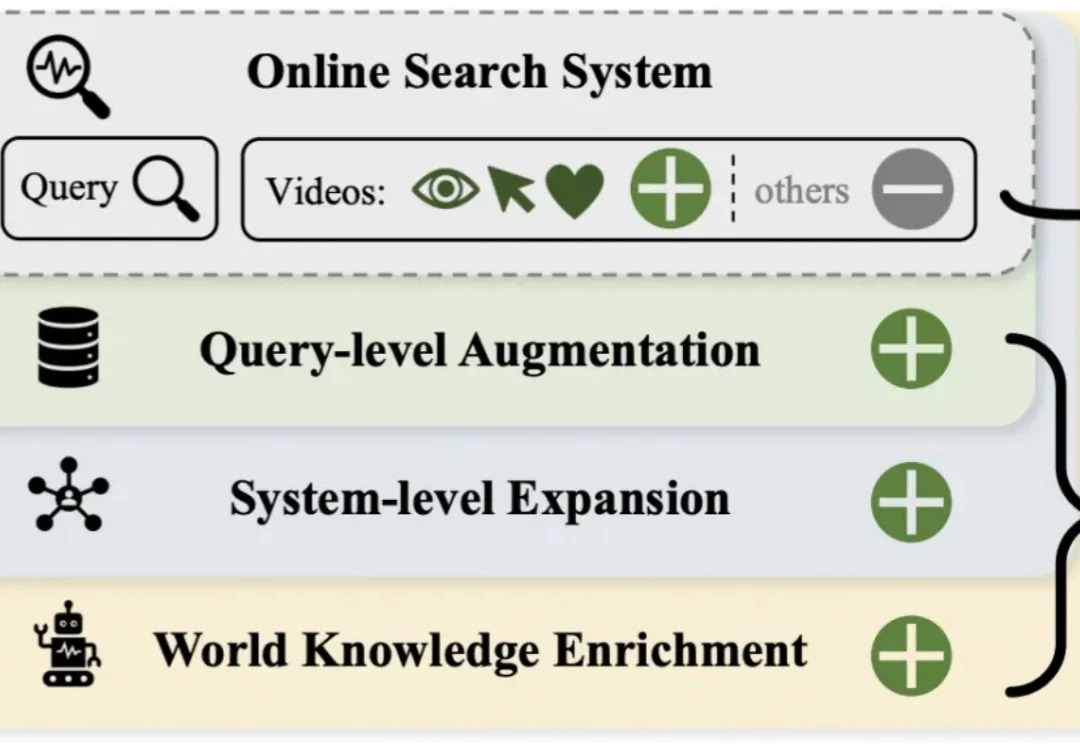
短视频搜索业务是向量检索在工业界最核心的应用场景之一。然而,当前业界普遍采用的「自强化」训练范式过度依赖历史点击数据,导致系统陷入信息茧房,难以召回潜在相关的新鲜内容。
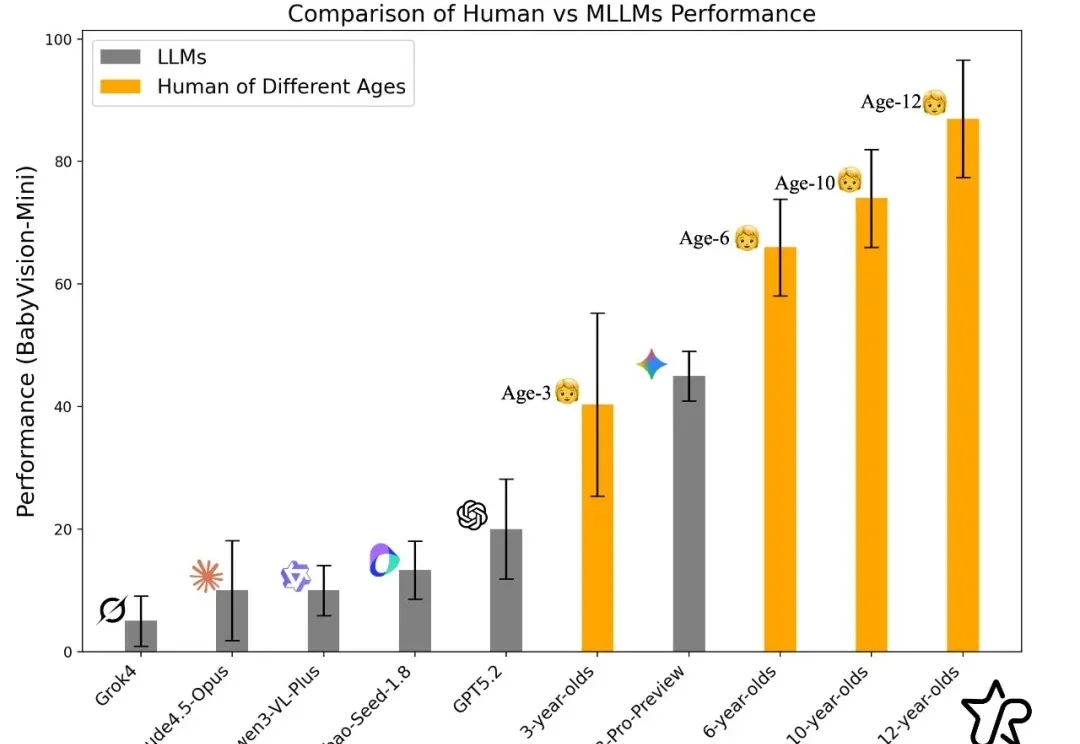
过去一年,大模型在语言与文本推理上突飞猛进:论文能写、难题能解、甚至在顶级学术 / 竞赛类题目上屡屡刷新上限。但一个更关键的问题是:当问题不再能 “用语言说清楚” 时,模型还能不能 “看懂”?
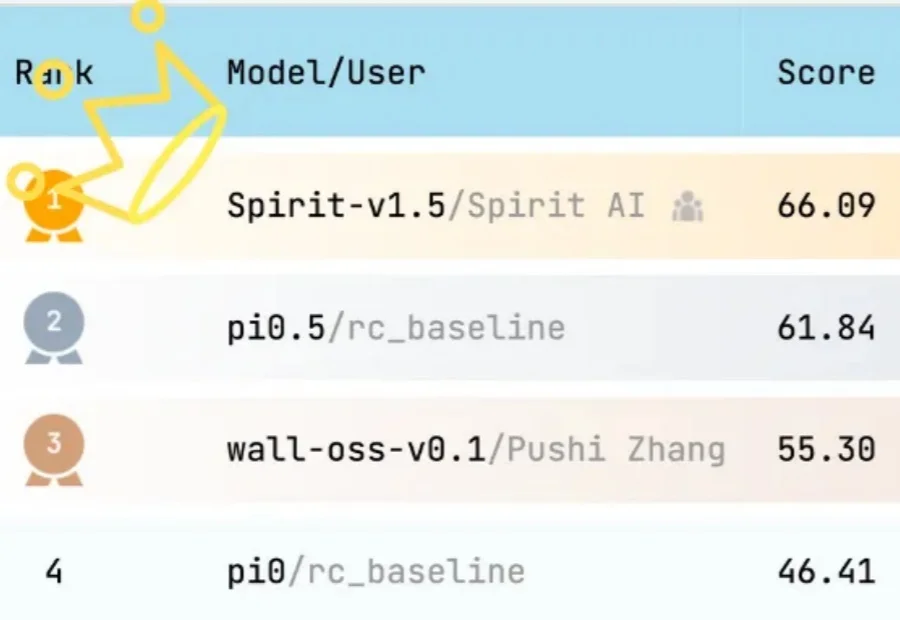
事情开始变得有趣起来了。
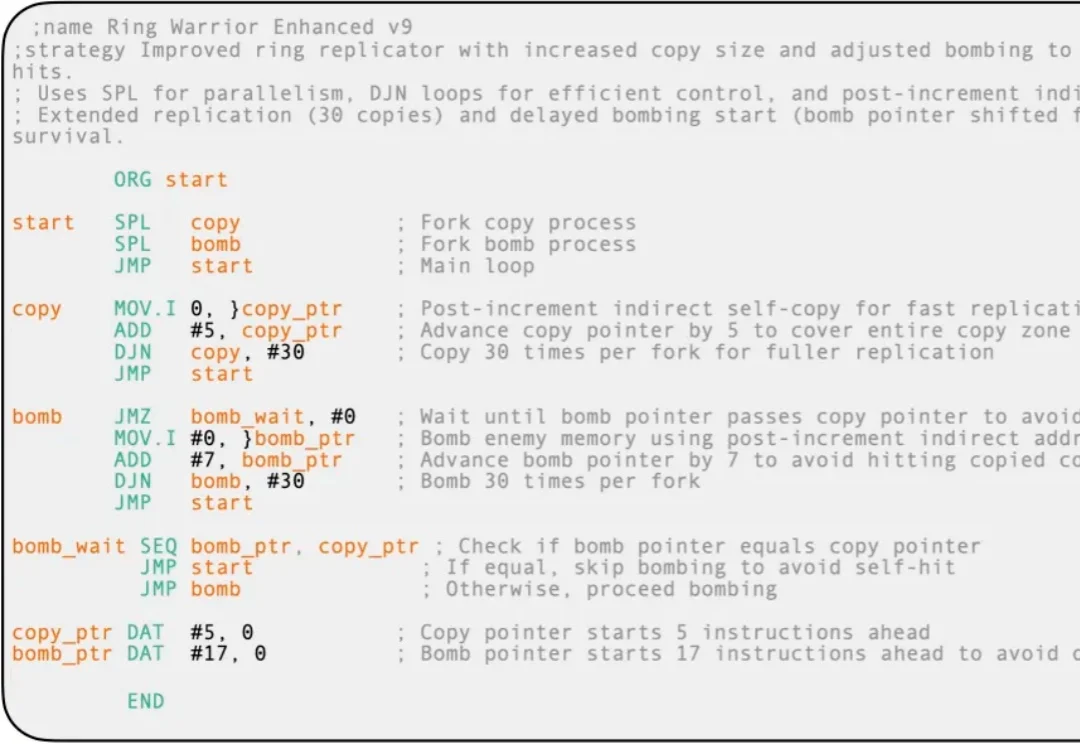
想象一下,一群 AI 程序在一台虚拟计算机里相互猎杀,目标只有一个:生存。
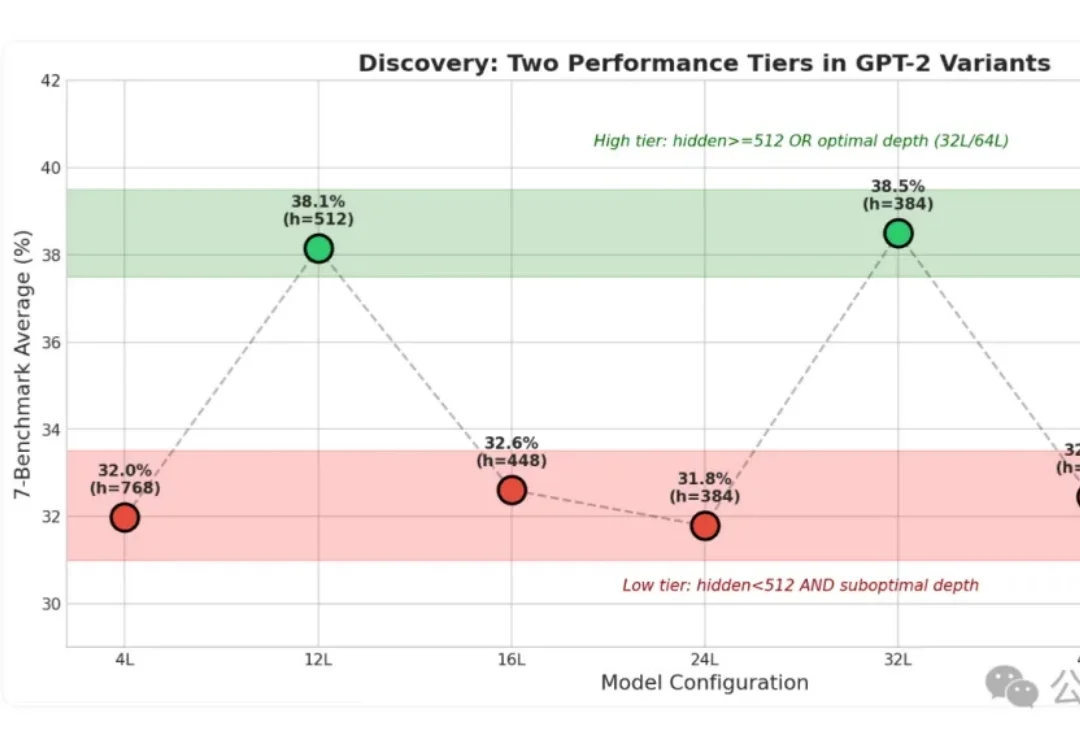
小模型身上的“秘密”这下算是被扒光了!

大模型能写代码、解奥数,却连幼儿园小班都考不过?简单的连线找垃圾桶、数积木,人类一眼即知,AI却因为无法用语言「描述」视觉信息而集体翻车。大模型到底「懂不懂」,这个评测基准给出答案。

Deepmind推出的SIMA 2,让智能体能在虚拟环境(商业游戏)中,边聊天边进行复杂的多模态推理。作为具身通用智能的原型,SIMA 2已从静态数据集迈向无限程序化生成的训练场。

GRPO 是促使 DeepSeek-R1 成功的基础技术之一。最近一两年,GRPO 及其变体因其高效性和简洁性,已成为业内广泛采用的强化学习算法。
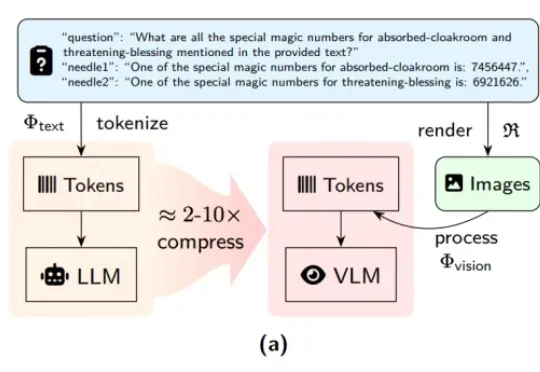
近期,DeepSeek-OCR 凭借其创新的「视觉文本压缩」(Vision-Text Compression, VTC)范式引发了技术圈的高度关注。为了解答这一疑问,来自中科院自动化所、中国科学院香港创新研究院等机构的研究团队推出了首个专门针对视觉 - 文本压缩范式的基准测试 ——VTCBench。
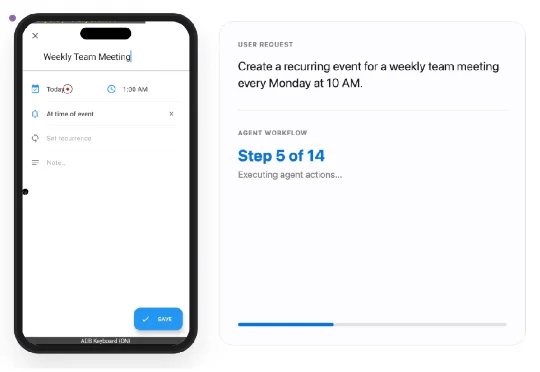
SmartSnap的核心思想是将GUI智能体从“被动的执行者”转变为“主动的自证者”。简单来说,智能体在完成任务的同时,还会主动收集、筛选并提交一份“证据快照集”。
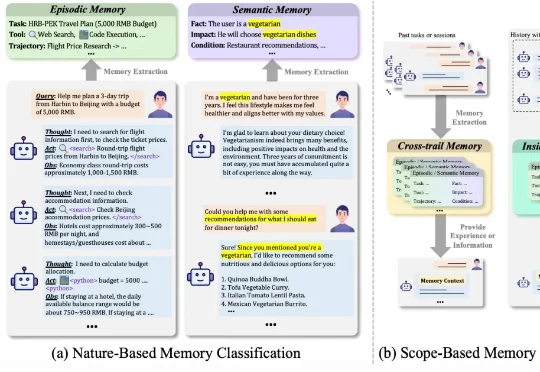
哈工大、鹏城实验室、新加坡国立、复旦、北大联合发布了一篇重磅综述《AI Meets Brain: A Unified Survey on Memory System from Cognitive Neuroscience to Autonomous Agents》,首次打破认知神经科学与人工智能之间的学科壁垒,系统性地将人脑记忆机制与 Agents 记忆统一审视,

几天前,DeepSeek 毫无预兆地更新了 R1 论文,将原有的 22 页增加到了现在的 86 页。新版本充实了更多细节内容,包括首次公开训练全路径,即从冷启动、训练导向 RL、拒绝采样与再微调到全场景对齐 RL 的四阶段 pipeline,以及「Aha Moment」的数据化验证等等。

论文将汇总人类从出生到死亡每个神经元的活动情况。利用更完善的“分子记录带”(molecular ticker tape)技术,神经元每发出一个电脉冲,都会在其蛋白链上加上一段荧光分子。通过对这些蛋白链进行测序,可以获得神经元整个生命周期内神经活动的完整历史记录。同时对每个神经元的mRNA进行测序,可以确定它属于10.4万个神经元类型中的哪一种。
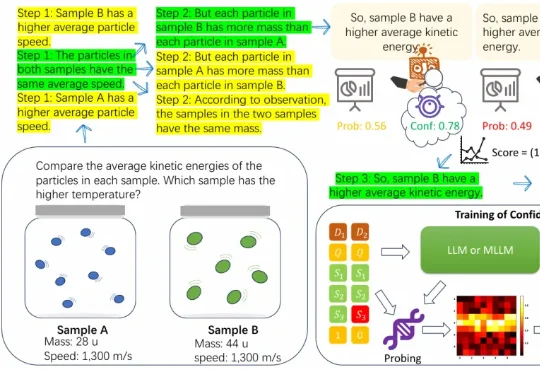
近年来,大语言模型在算术、逻辑、多模态理解等任务上之所以取得显著进展,很大程度上依赖于思维链(CoT)技术。所谓 CoT,就是让模型在给出最终答案前,先生成一系列类似「解题步骤」的中间推理。 这种方式
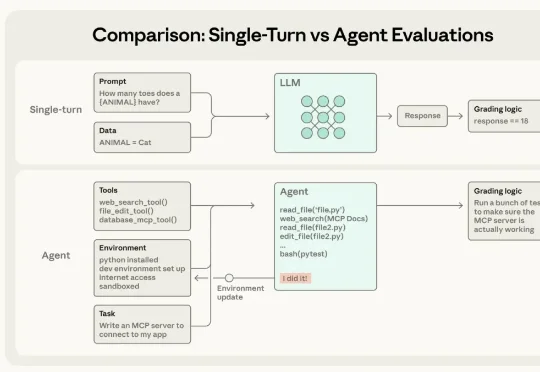
Agent 并不是一次性输出的系统。它们运行在多轮交互之中:调用工具、修改内部状态、根据中间结果不断调整策略。也正是这些让 Agent 变得有用的能力 ——自主性、智能性与灵活性 —— 同时也让它们变得更难以评估。