基础模型已颠覆科研,进入第五范式!港科大综述113篇论文 | NeurIPS'25
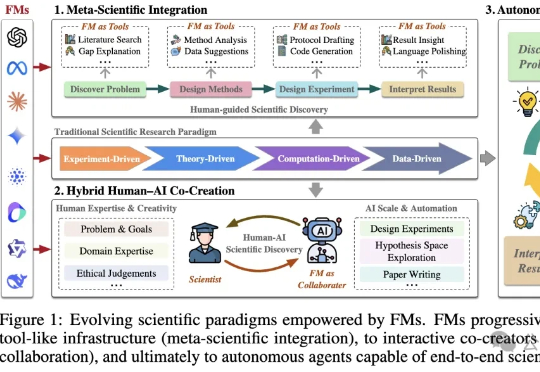
基础模型已颠覆科研,进入第五范式!港科大综述113篇论文 | NeurIPS'25基础模型(FM)是一种在海量数据上训练的人工智能系统,具备强大的通用性和跨模态能力。港科大最新发表的论文显示:FM可能引领科学进入第五范式,但大模型的偏见、幻觉等问题仍需正视。
来自主题: AI技术研报
8175 点击 2025-10-16 15:01
 搜索
搜索
基础模型(FM)是一种在海量数据上训练的人工智能系统,具备强大的通用性和跨模态能力。港科大最新发表的论文显示:FM可能引领科学进入第五范式,但大模型的偏见、幻觉等问题仍需正视。
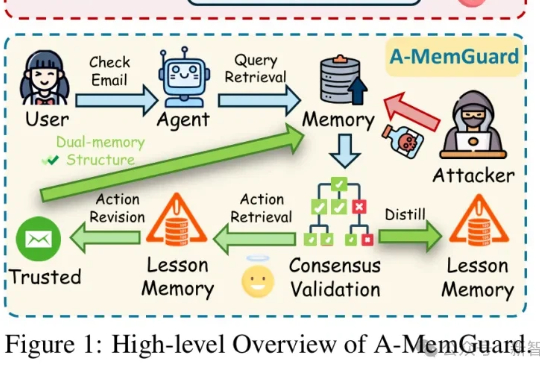
在AI智能体日益依赖记忆系统的时代,一种新型攻击悄然兴起:记忆投毒。A-MemGuard作为首个专为LLM Agent记忆模块设计的防御框架,通过共识验证和双重记忆结构,巧妙化解上下文依赖与自我强化错误循环的难题,让AI从被动受害者转为主动守护者,成功率高达95%以上。
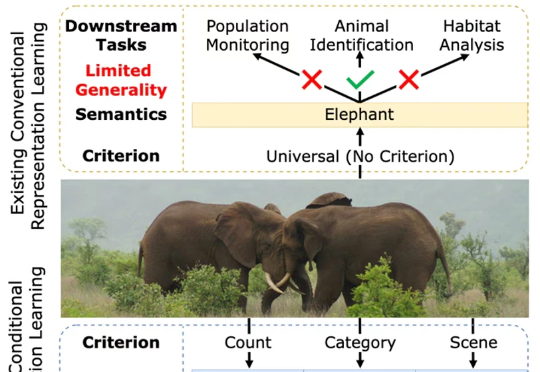
一张图片包含的信息是多维的。例如下面的图 1,我们至少可以得到三个层面的信息:主体是大象,数量有两头,环境是热带稀树草原(savanna)。然而,如果由传统的表征学习方法来处理这张图片,比方说就将其送入一个在 ImageNet 上训练好的 ResNet 或者 Vision Transformer,往往得到的表征只会体现其主体信息,也就是会简单地将该图片归为大象这一类别。这显然是不合理的。
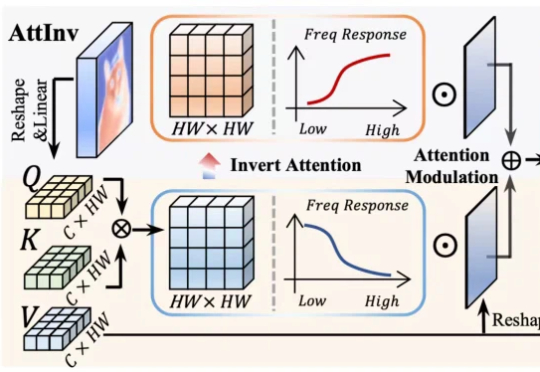
针对视觉 Transformer(ViT)因其固有 “低通滤波” 特性导致深度网络中细节信息丢失的问题,我们提出了一种即插即用、受电路理论启发的 频率动态注意力调制(FDAM)模块。它通过巧妙地 “反转” 注意力以生成高频补偿,并对特征频谱进行动态缩放,最终在几乎不增加计算成本的情况下,大幅提升了模型在分割、检测等密集预测任务上的性能,并取得了 SOTA 效果。

近日,RoboChallenge 重磅推出!这是全球首个大规模、多任务的在真实物理环境中由真实机器人执行操作任务的基准测试。

近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在图文理解、视觉问答等任务上取得了令人瞩目的进展。然而,当面对需要精细空间感知的任务 —— 比如目标检测、实例分割或指代表达理解时,现有模型却常常「力不从心」。

加州大学伯克利分校等机构的研究人员,近日推出了一种全新的基因组语言模型GPN-Star,可以将全基因组比对和物种树信息装进大模型,在人类基因变异预测方面达到了当前最先进的水平。
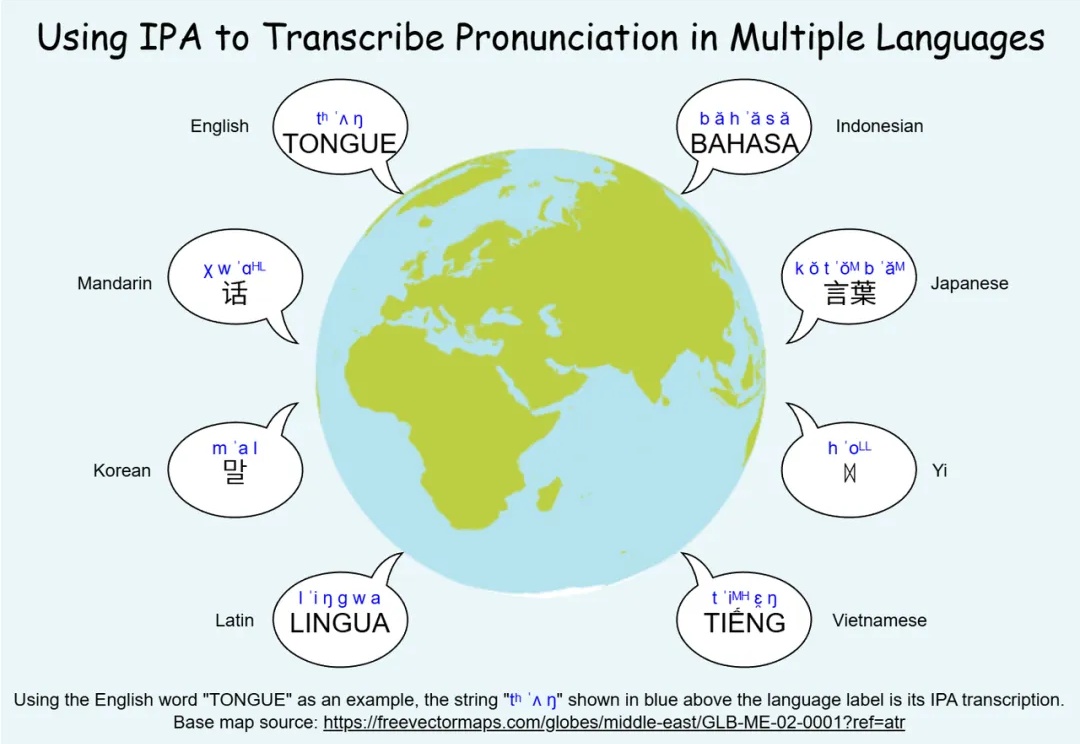
无论是中文的粤语、闽南话、吴语,还是欧洲的荷兰比尔茨语方言、法国奥克语,亦或是非洲和南美的地方语言,方言都承载着独特的音系与文化记忆,是人类语言多样性的重要组成部分。然而,许多方言正在快速消失,语音技术如果不能覆盖这些语言,势必加剧数字鸿沟与文化失声。
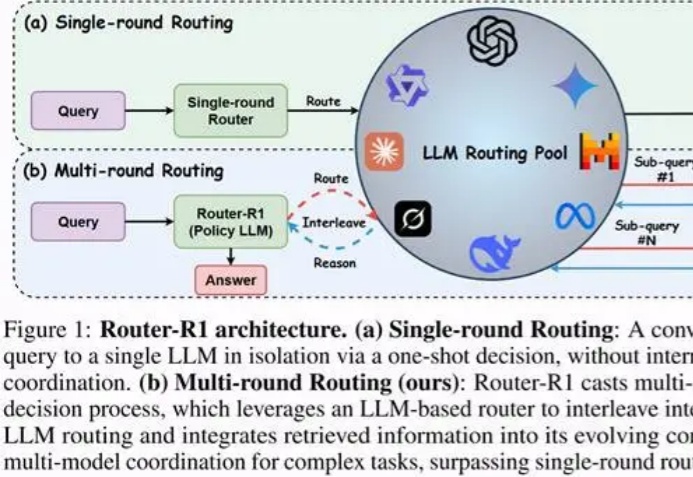
“如果一个问题只需小模型就能回答,为什么还要让更贵的大模型去思考?”
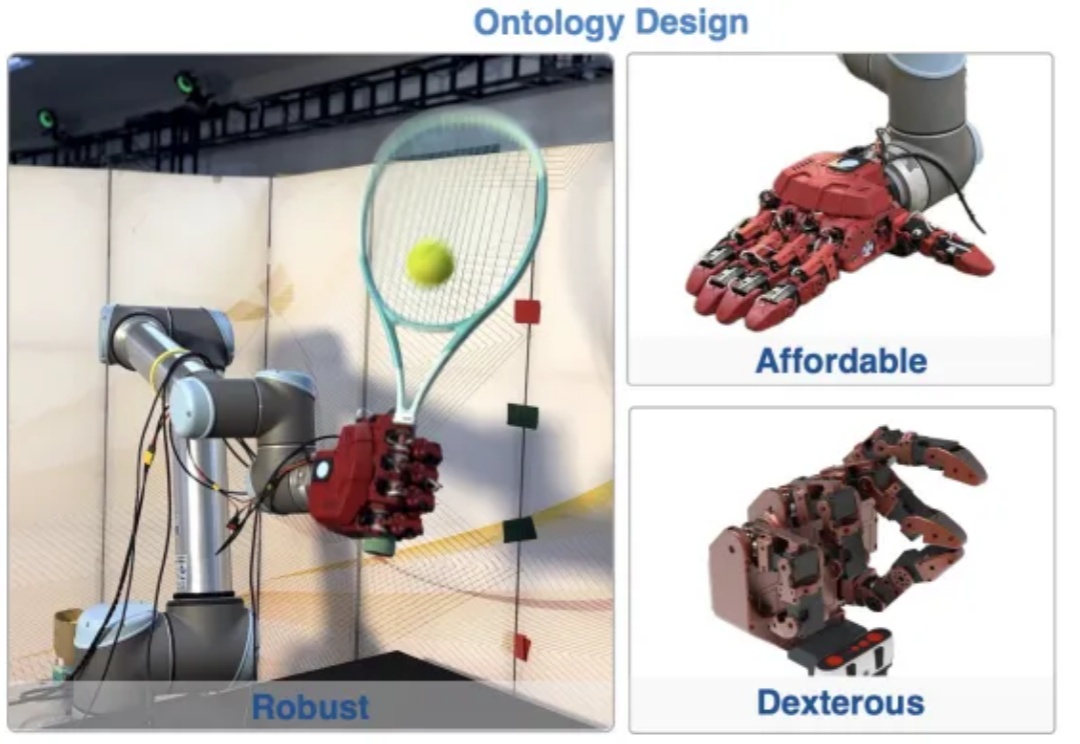
在最近的一篇 NeurIPS 25 中稿论文中,来自中山大学、加州大学 Merced 分校、中科院自动化研究所、诚橙动力的研究者联合提出了一个全新开源的高自由度灵巧手平台 — RAPID Hand (Robust, Affordable, Perception-Integrated, Dexterous Hand)。
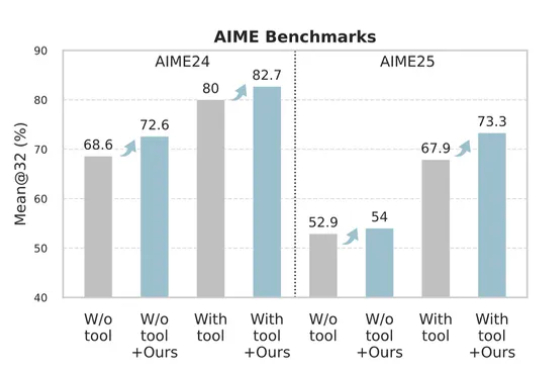
只花120元,效果吊打70000元微调!腾讯提出一种升级大模型智能体的新方法——无训练组相对策略优化Training-Free GRPO。无需调整任何参数,只要在提示词中学习简短经验,即可实现高性价比提升模型性能。

找AI帮忙不要再客气了,效果根本适得其反。 宾夕法尼亚州立大学的一项研究《Mind Your Tone》显示,你说话越粗鲁,LLM回答越准。
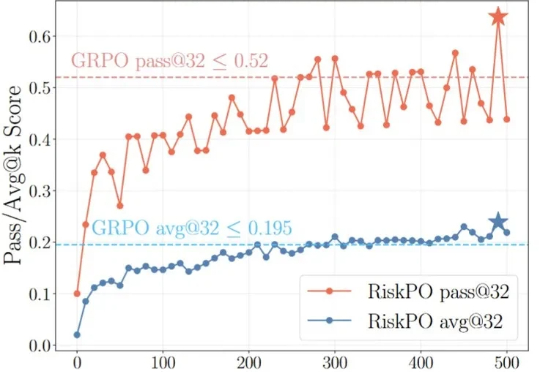
当强化学习(RL)成为大模型后训练的核心工具,「带可验证奖励的强化学习(RLVR)」凭借客观的二元反馈(如解题对错),迅速成为提升推理能力的主流范式。从数学解题到代码生成,RLVR 本应推动模型突破「已知答案采样」的局限,真正掌握深度推理逻辑 —— 但现实是,以 GRPO 为代表的主流方法正陷入「均值优化陷阱」。

扩散语言模型(Diffusion Language Models,DLM)一直以来都令研究者颇感兴趣,因为与必须按从左到右顺序生成的自回归模型(Autoregressive, AR)不同,DLM 能实现并行生成,这在理论上可以实现更快的生成速度,也能让模型基于前后文更好地理解生成语境。
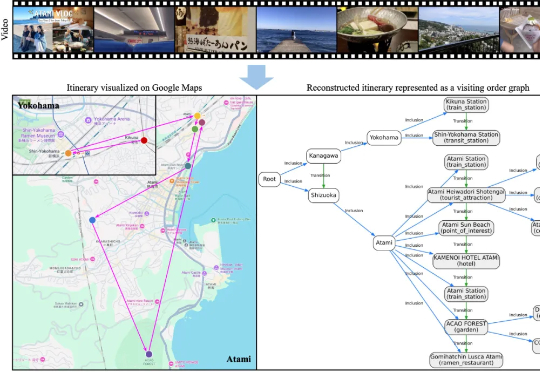
大家或许都有过这样的体验: 看完一部喜欢的动漫,总会心血来潮地想去 “圣地巡礼”;刷到别人剪辑精美的旅行 vlog,也会忍不住收藏起来,想着哪天亲自走一遍同样的路线。旅行与影像的结合,总是能勾起人们的
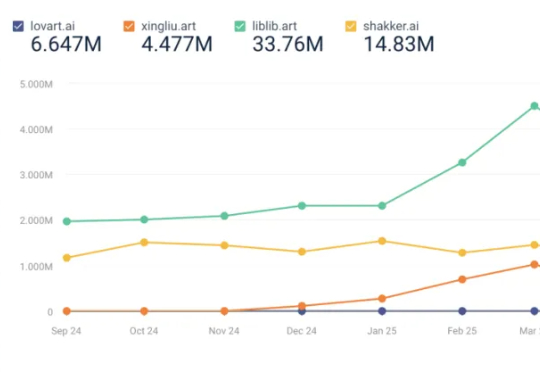
8 月榜单,最值得关注的变化是 Lovart 的访问量上升,8 月访问量上涨了 68.08% 至 323w,进入榜单。Lovart,读者想必已经熟悉,是奇点星宇的另一款 AI 视觉类产品,其产品核心设计为画布+对话框+编辑工具箱,也就是用户指导 AI 干活,

2023年Meta推出SAM,随后SAM 2扩展到视频分割,性能再度突破。近日,SAM 3悄悄现身ICLR 2026盲审论文,带来全新范式——「基于概念的分割」(Segment Anything with Concepts),这预示着视觉AI正从「看见」迈向真正的「理解」。
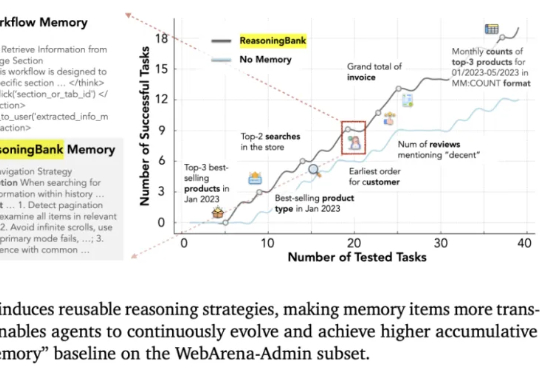
这几天,关于「微调已死」的言论吸引了学术圈的广泛关注。一篇来自斯坦福大学、SambaNova、UC 伯克利的论文提出了一种名为 Agentic Context Engineering(智能体 / 主动式上下文工程)的技术,让语言模型无需微调也能实现自我提升!

LLaVA 于 2023 年提出,通过低成本对齐高效连接开源视觉编码器与大语言模型,使「看图 — 理解 — 对话」的多模态能力在开放生态中得以普及,明显缩小了与顶级闭源模型的差距,标志着开源多模态范式的重要里程碑。
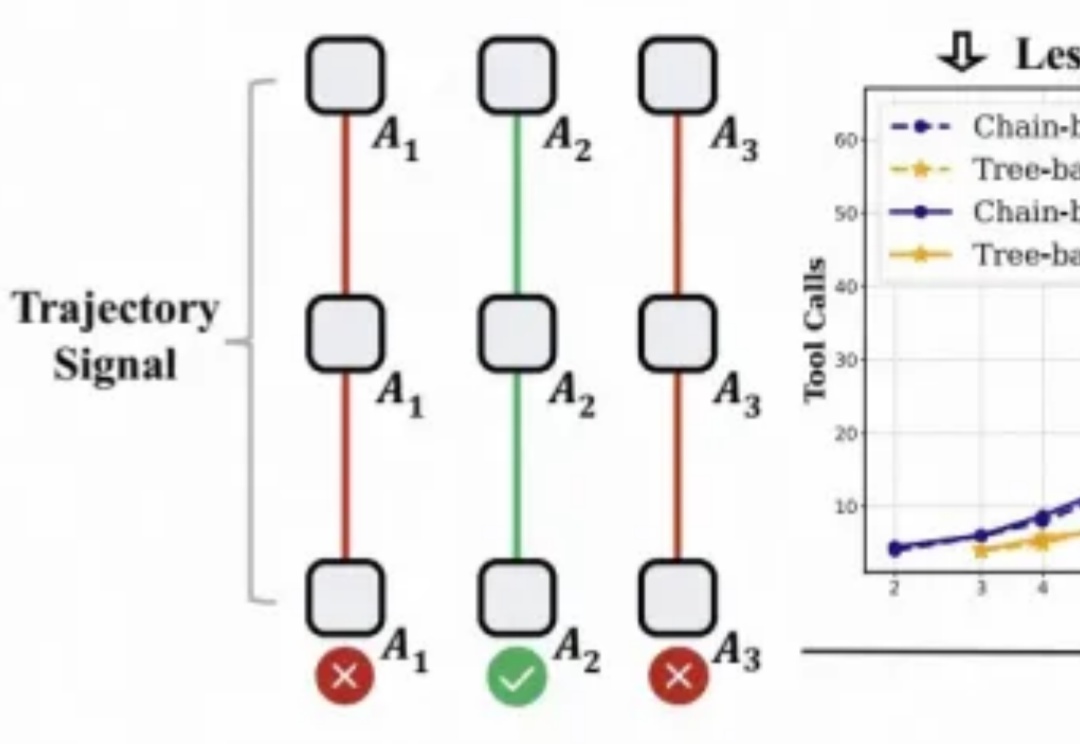
对于大模型的强化学习已在数学推理、代码生成等静态任务中展现出不俗实力,而在需要与开放世界交互的智能体任务中,仍面临「两朵乌云」:高昂的 Rollout 预算(成千上万的 Token 与高成本的工具调用)和极其稀疏的「只看结果」的奖励信号。

写给正在落地 AI 产品的工程师。一些代码直接可改造复用;另一些,是我踩坑后的经验之谈。
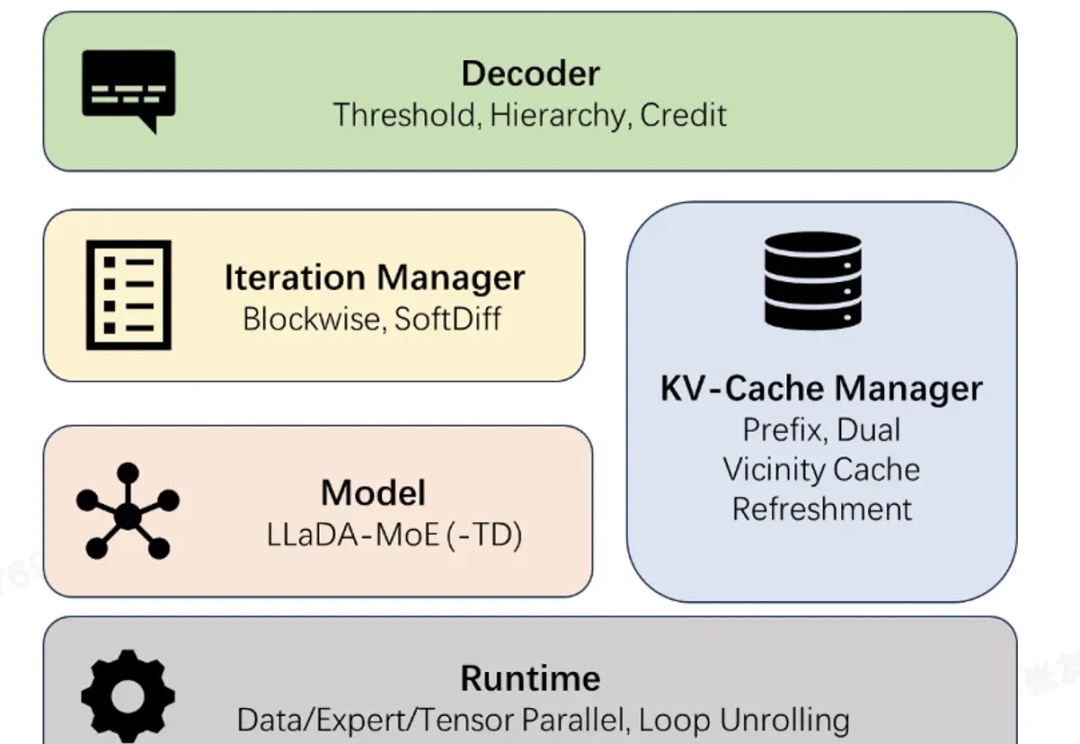
近日,蚂蚁集团正式开源业界首个高性能扩散语言模型(Diffusion Large Language Model,dLLM)推理框架 dInfer。
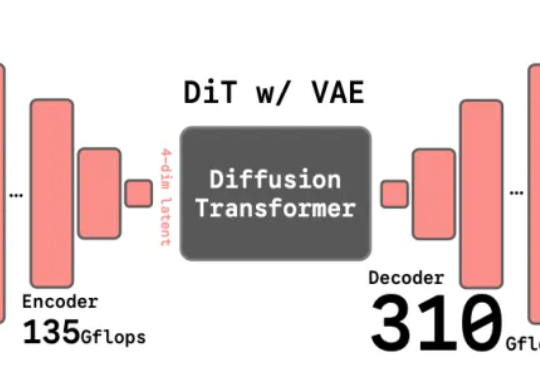
谢赛宁团队最新研究给出了答案——VAE的时代结束,RAE将接力前行。其中表征自编码器RAE(Representation Autoencoders)是一种用于扩散Transformer(DiT)训练的新型自动编码器,其核心设计是用预训练的表征编码器(如DINO、SigLIP、MAE 等)与训练后的轻量级解码器配对,从而替代传统扩散模型中依赖的VAE(变分自动编码器)。
根据 Sensor Tower 数据显示,2025 H1 AI 应用的下载量达到 17 亿次,增长 67%,IAP 收入总计达到 19 亿美元,增幅达到 100.6%。在走过了概念验证阶段后,AI 应用正成为一股很强的增长动力,给已经相对平静的应用市场注入了活力。

为什么大模型,在执行长时任务时容易翻车?这让一些专家,开始质疑大模型的推理能力,认为它们是否只是提供了「思考的幻觉」。近日,剑桥大学等机构的一项研究证明:问题不是出现在推理上,而是出在大模型的执行能力上。
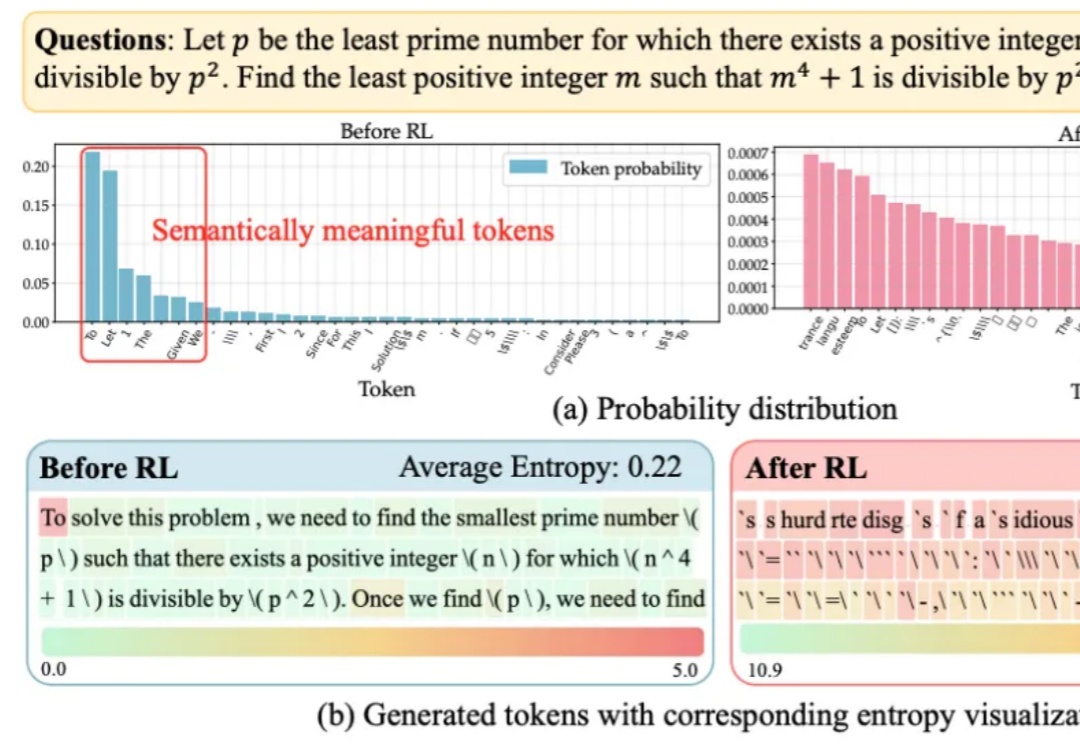
大语言模型在RLVR训练中面临的“熵困境”,有解了!

灵巧手技能+1,能帮女友拧瓶盖了!

当全球的目光还在聚焦基座模型的参数竞赛时,一场更为深刻的变革正在悄然发生——后训练(Post-Training)。
这是一份为正在开发 AI Agent 的产品经理准备的完整指南,介绍了 Agent 架构、编排模式等话题。
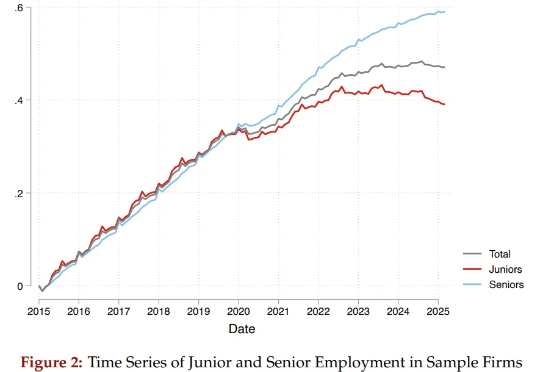
两位哈佛学者通过研究6200万份简历和近2亿条招聘职位数据,揭示了AI对就业带来的真实、残酷的冲击:它不是无差别地针对所有人,而是在大量“吞噬”初级岗位,让那些刚刚踏入社会的年轻人,面临着空前陡峭、狭窄的职业起跑线。与此同时,为数众多的普通院校毕业生群体受到的冲击更为显著。