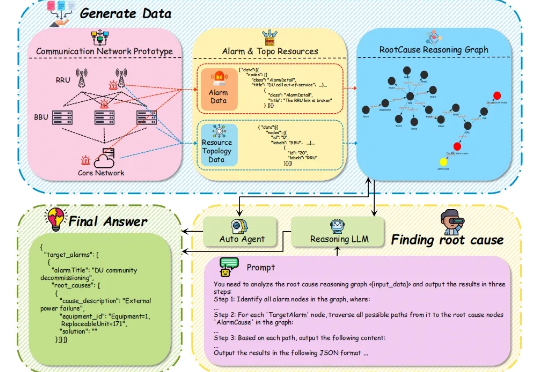
追剧不断网,可能背后有个AI在加班,故障诊断准度破91.79%
追剧不断网,可能背后有个AI在加班,故障诊断准度破91.79%当你的手机突然没信号时,电信工程师在做什么? 想象一下这样的场景:某个周五晚上,你正在用手机追剧,突然网络断了。与此同时,成千上万的用户也遇到了同样的问题。电信运营商的监控中心瞬间被数百个告警信息淹没 —— 基站离线、信号中断、设备故障…
来自主题: AI技术研报
6902 点击 2025-08-16 15:57
 搜索
搜索
当你的手机突然没信号时,电信工程师在做什么? 想象一下这样的场景:某个周五晚上,你正在用手机追剧,突然网络断了。与此同时,成千上万的用户也遇到了同样的问题。电信运营商的监控中心瞬间被数百个告警信息淹没 —— 基站离线、信号中断、设备故障…
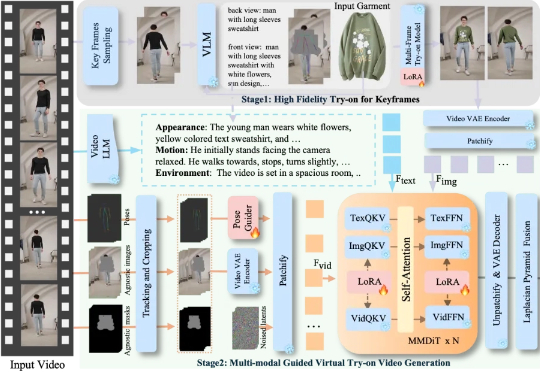
服装视频广告太烧钱?卡点变装太难拍? 字节跳动智能创作团队联合清华大学最新推出一款全能的视频换装模型 DreamVVT,为视频虚拟试穿领域带来了突破性进展。
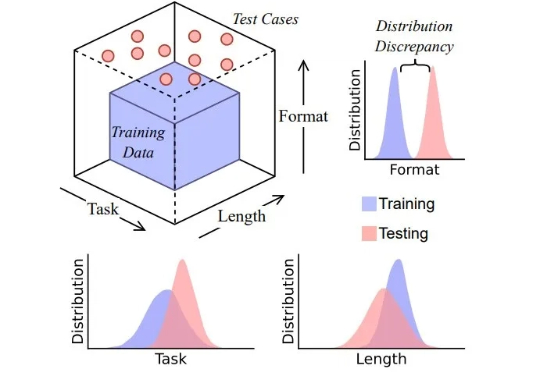
思维链 (CoT) 提示技术常被认为是让大模型分步思考的关键手段,通过在输入中加入「Let’s think step by step」等提示,模型会生成类似人类的中间推理步骤,显著提升复杂任务的表现。然而,这些流畅的推理链条是否真的反映了模型的推理能力?
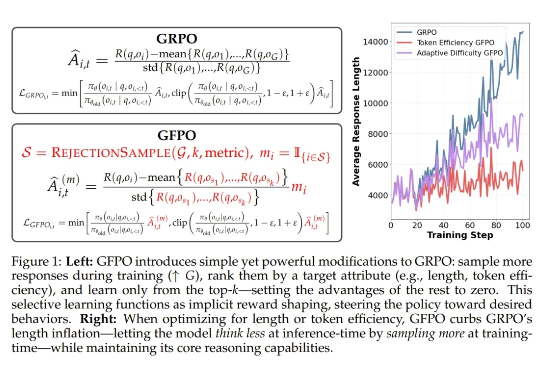
用过 DeepSeek-R1 等推理模型的人,大概都遇到过这种情况:一个稍微棘手的问题,模型像陷入沉思一样长篇大论地推下去,耗时耗算力,结果却未必靠谱。现在,我们或许有了解决方案。
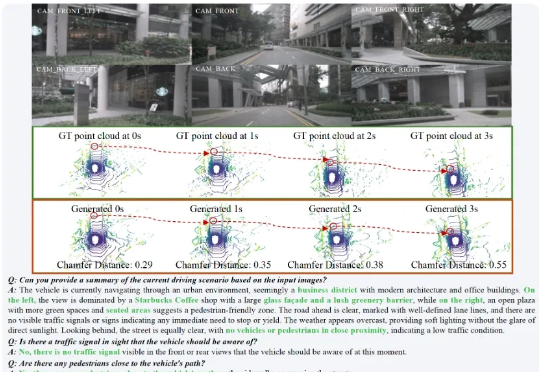
在复杂的城市场景中,HERMES 不仅能准确预测未来三秒的车辆与环境动态(如红圈中标注的货车),还能对当前场景进行深度理解和问答(如准确识别出 “星巴克” 并描述路况)。
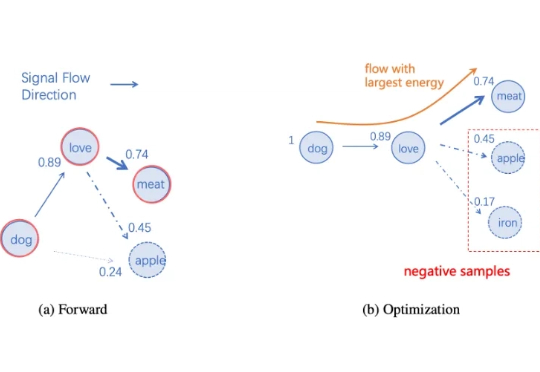
当前 GPT 类大语言模型的表征和处理机制,仅在输入和输出接口层面对语言元素保持可解释的语义映射。相比之下,人类大脑直接在分布式的皮层区域中编码语义,如果将其视为一个语言处理系统,它本身就是一个在全局上可解释的「超大模型」。
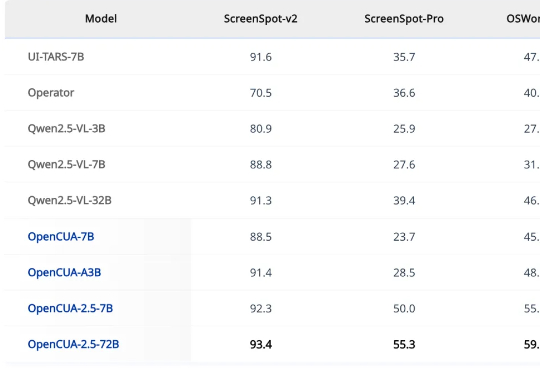
刚刚,一篇来自香港大学 XLANG Lab 和月之暗面等多家机构的论文上线了 arXiv,其中提出了一个用于构建和扩展 CUA(使用计算机的智能体)的完全开源的框架。 使用该框架,他们还构建了一个旗舰模型 OpenCUA-32B,其在 OSWorld-Verified 上达到了 34.8% 的成功率,创下了新的开源 SOTA,甚至在这个基准测试中超越了 GPT-4o。
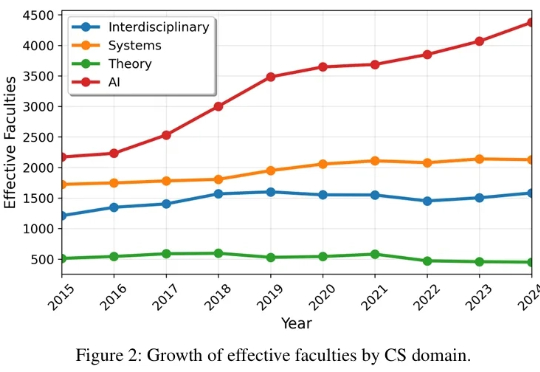
相信我们的读者都对 AI 顶会有非常大的关注和热情,有的读者最近可能刚从 NeurIPS rebuttal 脱身,又开始为下一篇做准备了。 作为推动技术革新与思想碰撞的核心引擎,顶级学术会议不仅是整个学界的生命线,更是我们洞察未来的前沿阵地。

强化学习(RL)是锻造当今顶尖大模型(如 OpenAI o 系列、DeepSeek-R1、Gemini 2.5、Grok 4、GPT-5)推理能力与对齐的核心 “武器”,但它也像一把双刃剑,常常导致模型行为脆弱、风格突变,甚至出现 “欺骗性对齐”、“失控” 等危险倾向。
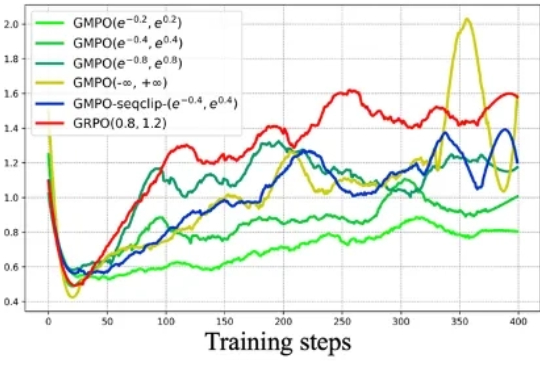
近年来,强化学习(RL)在大型语言模型(LLM)的微调过程中,尤其是在推理能力提升方面,取得了显著的成效。传统的强化学习方法,如近端策略优化(Proximal Policy Optimization,PPO)及其变种,包括组相对策略优化(Group Relative Policy Optimization,GRPO),在处理复杂推理任务时表现出了强大的潜力。

Artificial Analysis 最近发布了《State of AI: China Q2 2025 Highlights Report》(2025年Q2 中国人工智能现状分析报告),聚焦中国 AI 发展现状。
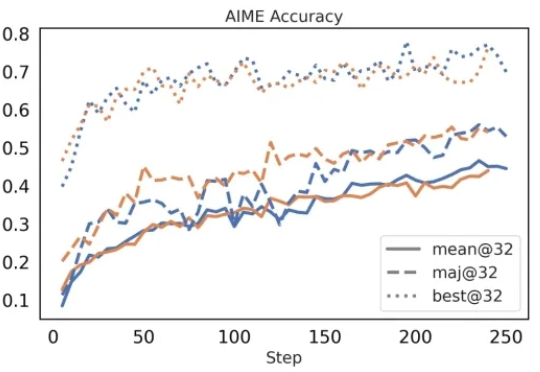
近年来,大语言模型(LLM)已展现出卓越的通用能力,但其核心仍是静态的。面对日新月异的任务、知识领域和交互环境,模型无法实时调整其内部参数,这一根本性瓶颈日益凸显。
在今年三月份,清华 AIR 和字节联合 SIA Lab 发布了 DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。
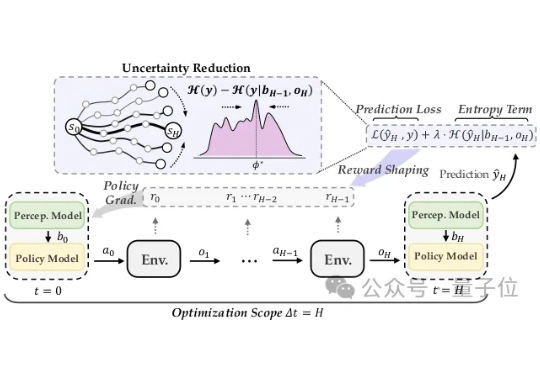
面对对抗攻击,具身智能体除了被动防范,也能主动出击! 在人类视觉系统启发下,清华朱军团队在TPMAI 2025中提出了强化学习驱动的主动防御框架REIN-EAD。
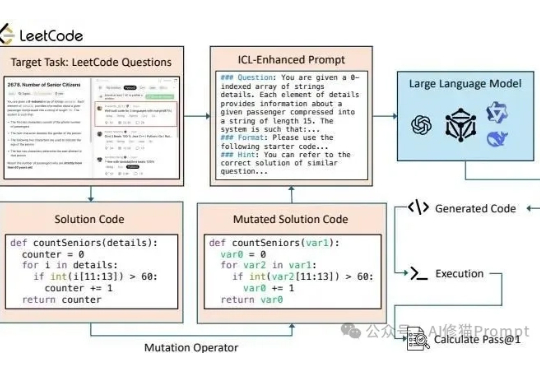
长久以来我们都知道在Prompt里塞几个好例子能让LLM表现得更好,这就像教小孩学东西前先给他做个示范。在Vibe coding爆火后,和各种代码生成模型打交道的人变得更多了,大家也一定用过上下文学习(In-Context Learning, ICL)或者检索增强生成(RAG)这类技术来提升它的表现。
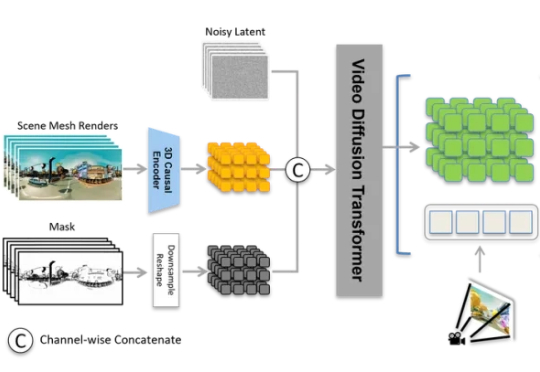
3D生成的行业新标杆,这一次由国产玩家树立。 万万没想到,这样一个堪比游戏全景视角的场景,竟然只由一张图片生成?!
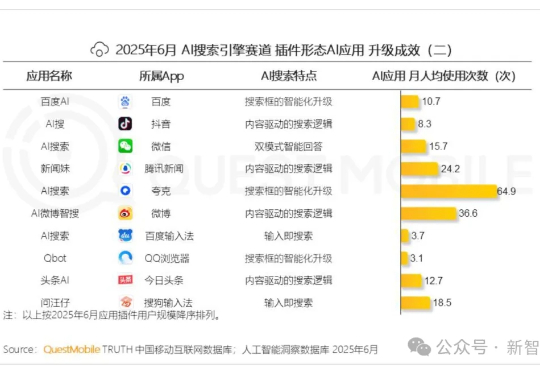
AI搜索大战,已经白热化!最新QuestMobile报告揭晓:夸克月人均使用次数稳居第一,微博智搜凭DeepSeek杀进前二,腾讯「新闻妹」拿到第三。实测发现,天气预警、社会新闻、数码测评、娱乐八卦,微博智搜统统一键梳理,让网友搜索体验爽到飞起。
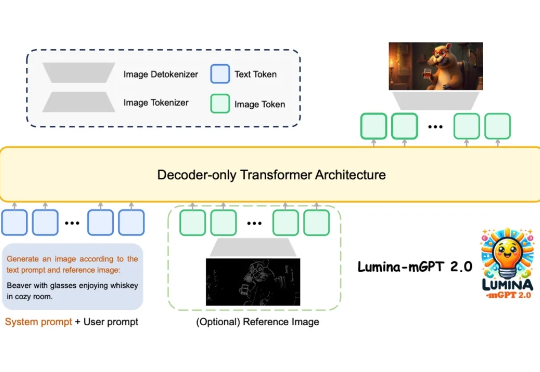
上海人工智能实验室等团队提出Lumina-mGPT 2.0 —— 一款独立的、仅使用解码器的自回归模型,统一了包括文生图、图像对生成、主体驱动生成、多轮图像编辑、可控生成和密集预测在内的广泛任务。
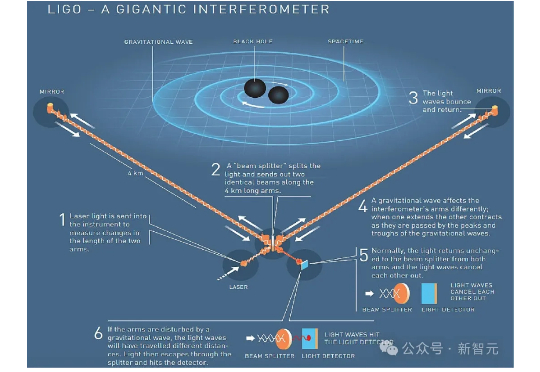
AI设计出人类看不懂的实验,却成功破解物理学数十年难题,大幅提升LIGO灵敏度。寻找暗物质,解读宇宙公式都不在话下,AI辅助物理学发现的新时代已经到来。

近年来,扩散模型在图像与视频合成领域展现出前所未有的生成能力,为人脸生成与编辑技术按下了加速键。特别是一张静态人脸驱动任意表情、姿态乃至光照的梦想,正在走向大众工具箱,并在三大场景展现巨大潜力

「一只手有几根手指?」 这个看似简单的问题,强如 GPT-5 却并不能总是答对。 今天,CMU 博士生、英伟达 GEAR(通用具身智能体研究)团队成员 Tairan He(何泰然)向 GPT-5 询问了这个问题,结果模型回答错了。
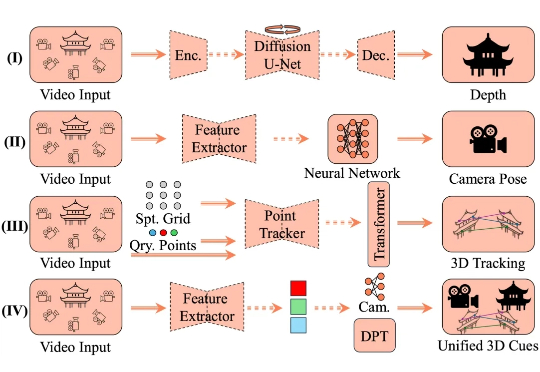
4D 空间智能重建是计算机视觉领域的核心挑战,其目标在于从视觉数据中还原三维空间的动态演化过程。这一技术通过整合静态场景结构与时空动态变化,构建出具有时间维度的空间表征系统,在虚拟现实、数字孪生和智能交互等领域展现出关键价值。
近年来,文生图模型(Text-to-Image Models)飞速发展,从早期的 GAN 架构到如今的扩散和自回归模型,生成图像的质量和细节表现力实现了跨越式提升。这些模型大大降低了高质量图像创作的门槛,为设计、教育、艺术创作等领域带来了前所未有的便利。

稀疏激活的混合专家模型(MoE)通过动态路由和稀疏激活机制,极大提升了大语言模型(LLM)的学习能力,展现出显著的潜力。基于这一架构,涌现出了如 DeepSeek、Qwen 等先进的 MoE LLM。

在「用进废退」原则的驱动下,拇指逐渐变长且肌肉发达,能够与其他手指精准对握,实现精细操作。手部由多个关节组成,具有高度灵活性,可完成捏、握、夹等多种动作。此外,手部皮肤富含触觉感受器,能够感知压力、温度和纹理等信息,为操作提供精准反馈。

在图像生成领域,自回归(Autoregressive, AR)模型与扩散(Diffusion)模型之间的技术路线之争始终未曾停歇。大语言模型(LLM)凭借其基于「预测下一个词元」的优雅范式,已在文本生成领域奠定了不可撼动的地位。
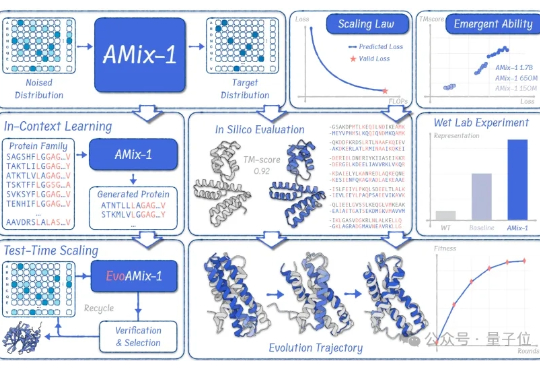
蛋白质模型的GPT时刻来了! 清华大学智能产业研究院(AIR)周浩副教授课题组联合上海人工智能实验室发布了AMix-1: 首次以Scaling Law、Emergent Ability、In-Context Learning和Test-time Scaling的系统化方法论来构建蛋白质基座模型。
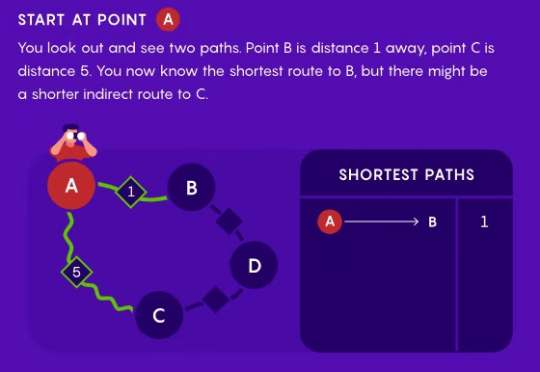
每次打开导航的,导航软件在一秒内给出一个最速路线的时候,你有没有好奇过它是怎么找到这条路的? 假如不考虑堵车、红绿灯等交通影响因素,仅找到一条最短最快的路线,那不论如何也逃不掉 Dijkstra 算法。
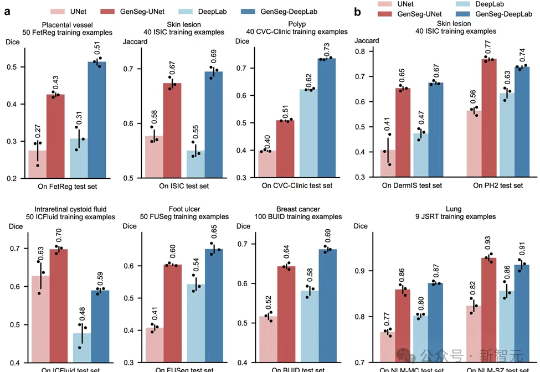
GenSeg用AI生成高质量医学图像及对应分割标注,在仅有几十张样本时也能训练出媲美传统深度模型的分割系统,显著降低医生手工标注负担。
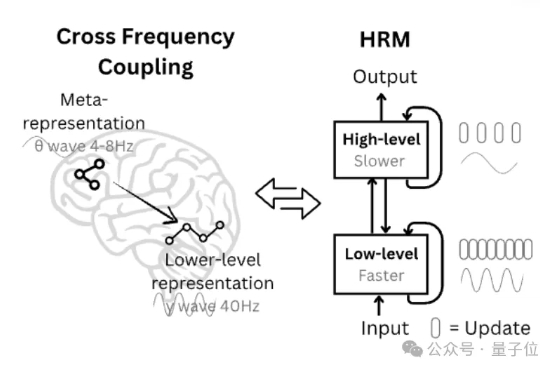
27M小模型超越o3-mini-high和DeepSeek-R1!推理还不靠思维链。 开发者是那位拒绝了马斯克、还要挑战Transformer的00后清华校友,Sapient Intelligence的创始人王冠。