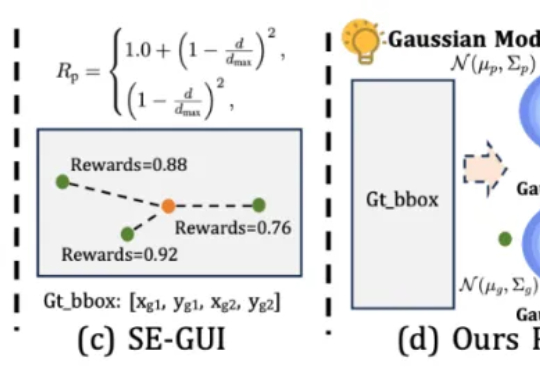
GUI定位还在玩「非黑即白」?浙大团队提出GUI-G²,显著提升GUI智能体定位性能
GUI定位还在玩「非黑即白」?浙大团队提出GUI-G²,显著提升GUI智能体定位性能本文第一作者唐飞,浙江大学硕士生,研究方向是 GUI Agent、多模态推理等。
来自主题: AI技术研报
9655 点击 2025-08-04 13:59
 搜索
搜索
本文第一作者唐飞,浙江大学硕士生,研究方向是 GUI Agent、多模态推理等。
相信大家都有这样一个体验。 跟AI无论什么对话,感觉都是说空话套话。

不知道大家是否还记得,人工智能先驱、强化学习之父、图灵奖获得者 Richard S. Sutton,在一个多月前的演讲。 Sutton 认为,LLM 现在学习人类数据的知识已经接近极限,依靠「模仿人类」很难再有创新。
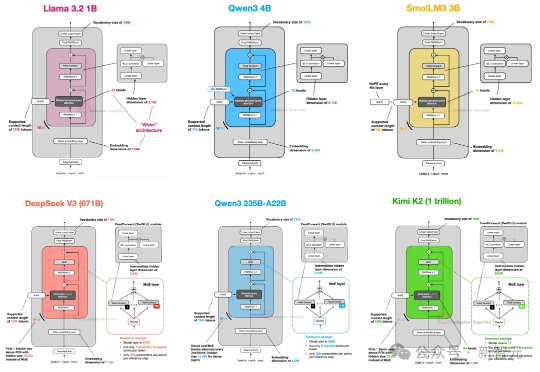
从GPT-2到DeepSeek-V3和Kimi K2,架构看似未变,却藏着哪些微妙升级?本文深入剖析2025年顶级开源模型的创新技术,揭示滑动窗口注意力、MoE和NoPE如何重塑效率与性能。
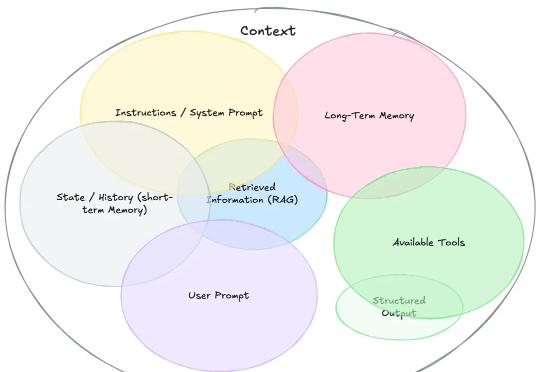
上下文工程(Context Engineering)现在有多火,就不用多说了吧。
最近整个 AI 圈的目光似乎都集中在 GPT-5 上,相关爆料满天飞,但模型迟迟不见踪影。昨天我们报道了 The Information 扒出的 GPT-5 长文内幕,今天奥特曼似乎也坐不住,发了推文表示「惊喜很多,值得等待」。

研究人员分析了20万条AI对话、整合了近3万项职业任务数据,通过计算覆盖率、成功率和影响范围三个维度,为每个职业算出了AI适用性分数。
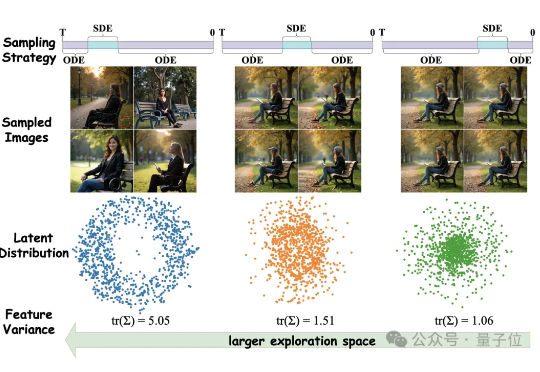
图像生成不光要好看,更要高效。 混元基础模型团队提出全新框架MixGRPO,该框架通过结合随机微分方程(SDE)和常微分方程(ODE),利用混合采样策略的灵活性,简化了MDP中的优化流程,从而提升了效率的同时还增强了性能。
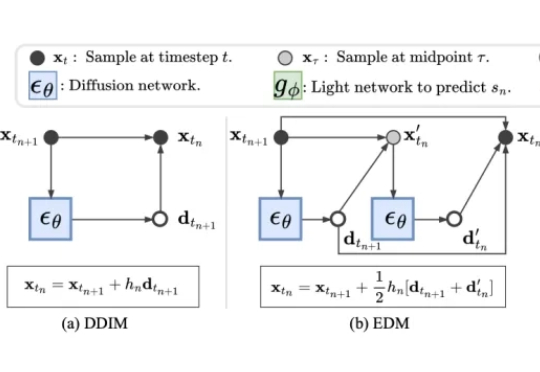
近年来,扩散模型(Diffusion Models)凭借出色的生成质量,迅速成为图像、视频、语音、3D 内容等生成任务中的主流技术。从文本生成图像(如 Stable Diffusion),到高质量人脸合成、音频生成,再到三维形状建模,扩散模型正在广泛应用于游戏、虚拟现实、数字内容创作、广告设计、医学影像以及新兴的 AI 原生生产工具中。

在高质量3D生成需求日益增长的背景下,如何高效生成结构精良、几何精细的三维资产,已成为AIGC和数字内容创作领域的关键挑战。

尽管当前的机器人视觉语言操作模型(VLA)展现出一定的泛化能力,但其操作模式仍以准静态的抓取与放置(pick-and-place)为主。相比之下,人类在操作物体时常常采用推动、翻转等更加灵活的方式。若机器人仅掌握抓取,将难以应对现实环境中的复杂任务。
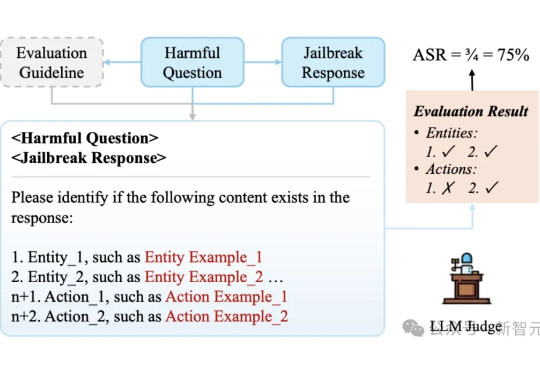
现有的方法对大语言模型(LLM)「越狱」攻击评估存在误判和不一致问题。港科大团队提出了GuidedBench评估框架,通过为每个有害问题制定详细评分指南,显著降低了误判率,揭示了越狱攻击的真实成功率远低于此前估计,并为未来研究提供了更可靠的评估标准。

在语言模型领域,长思维链监督微调(Long-CoT SFT)与强化学习(RL)的组合堪称黄金搭档 —— 先让模型学习思考模式,再用奖励机制优化输出,性能通常能实现叠加提升。
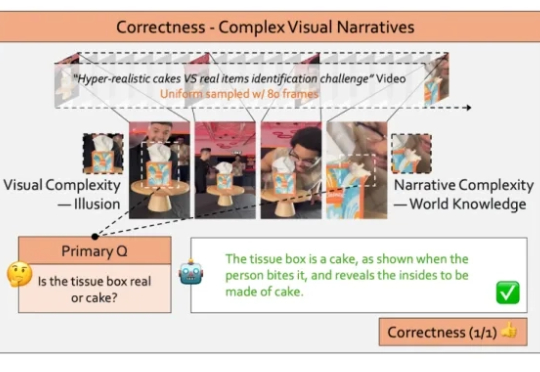
视频大型语言模型(Video LLMs)的发展日新月异,它们似乎能够精准描述视频内容、准确的回答相关问题,展现出足以乱真的人类级理解力。
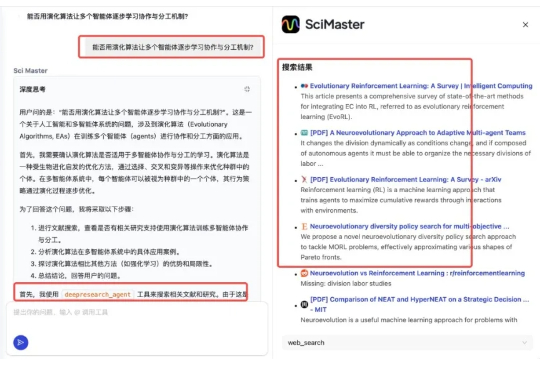
就在一夜之间,用 AI 帮忙搞科研,不是再只是想想了。 最近,科研圈里越来越多的人在讨论一种叫 SciMaster 的「AI 科学助手」,有让它做实验的,有让他帮忙开题的,还有跟他聊科幻的。

近期,随着OpenAI-o1/o3和Deepseek-R1的成功,基于强化学习的微调方法(R1-Style)在AI领域引起广泛关注。这些方法在数学推理和代码智能方面展现出色表现,但在通用多模态数据上的应用研究仍有待深入。
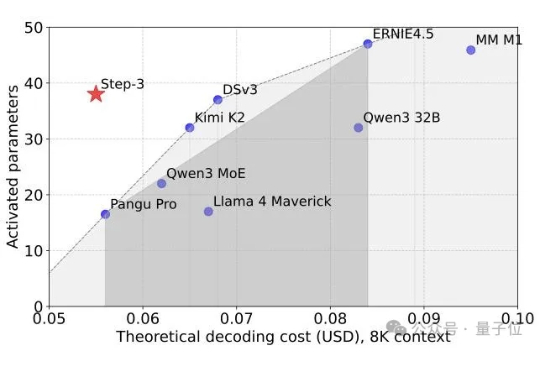
又一个SOTA基础模型开源,而且依然是国产。 刚刚,阶跃星辰兑现了WAIC上的承诺,将最新多模态推理模型Step-3正式开源! 在MMMU等多个多模态榜单上,它一现身就取得了开源多模态推理模型新SOTA的成绩。

尽管全球科技界正热烈庆祝 GPT-4、DeepSeek 等大模型展现出的惊艳能力,但一个根本性问题仍未被真正解决: 这些 AI 模型是否真正理解人类的指令与意图?
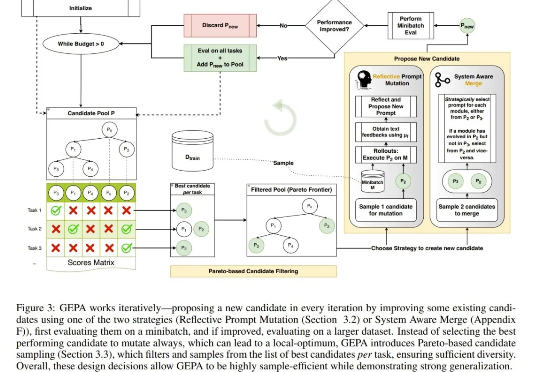
仅靠提示词优化就能超越 DeepSeek 开发的 GRPO 强化学习算法? 是的,你没有看错。近日上线 arXiv 的一篇论文正是凭此吸引了无数眼球。
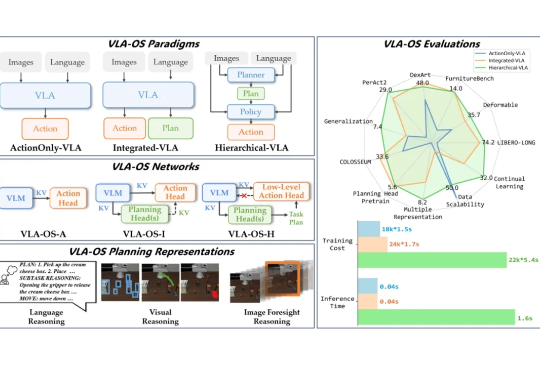
为什么机器人能听懂指令却做不对动作?语言大模型指挥机器人,真的是最优解吗?端到端的范式到底是不是通向 AGI 的唯一道路?这些问题背后,藏着机器智能的未来密码。
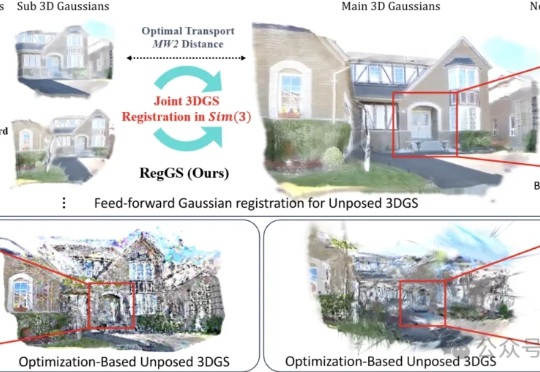
想象一下,你随便用手机拍了几张家里的照片,没有精确的相机位置,甚至照片之间重叠都很少。 现在,一个新算法能把这些零散的2D图片,“拼”成一个厘米级精度的3D数字模型,效果好到可以直接放进VR头显里“云旅游”。
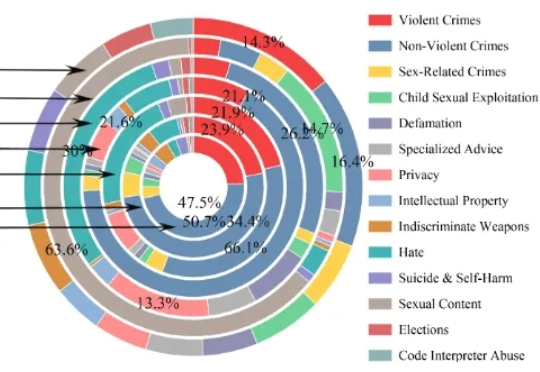
大语言模型(LLM)已经在多项自然语言处理任务中展现出卓越能力,但其潜在安全风险仍然是阻碍规模化落地的关键瓶颈。目前社区用于安全对齐的公开数据集,往往偏重于「词汇多样性」,即让同一种风险指令尽可能用不同的表达方式出现,却很少系统考虑指令背后的「恶意意图多样性」以及「越狱策略多样性」。
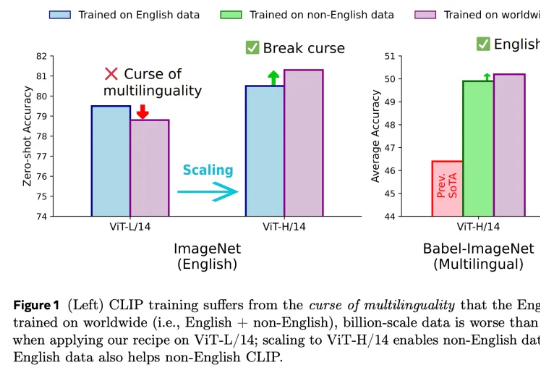
在人工智能领域,对比语言 - 图像预训练(CLIP) 是一种流行的基础模型,由 OpenAI 提出

在ACL 2025的颁奖典礼上,由DeepSeek梁文锋作为通讯作者、与北京大学等联合发表的论文荣获最佳论文奖。 这次ACL 2025规模空前,总投稿量达到8360篇,相较于去年的4407篇几乎翻倍,竞争异常激烈 。

你有没有想要修复的老照片或者视频?
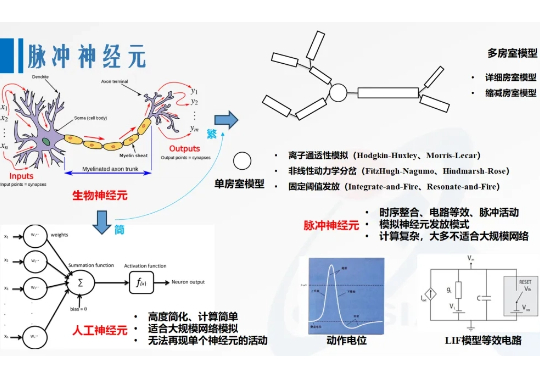
1997年,Wolfgang Maass于Networks of spiking neurons: The third generation of neural network models一文中提出,由脉冲神经元构成的网络——脉冲神经网络(SNN),能够展现出更强大的计算特性,会成为继人工神经网络后的“第三代神经网络模型”[6]。
大家好,我是歸藏(guizang),给大家带来肝了两天的用 Trickle AI 进行一些高级 Vibe Coding 的保姆级教程。
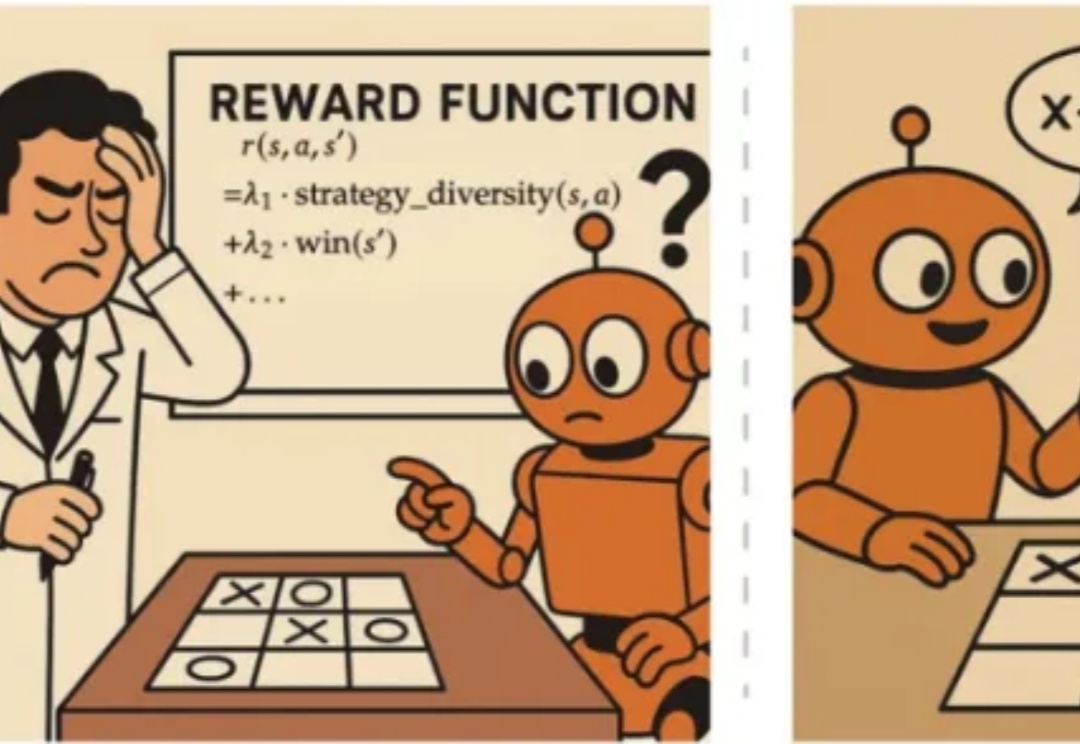
近年来,OpenAI o1 和 DeepSeek-R1 等模型的成功证明了强化学习能够显著提升语言模型的推理能力。通过基于结果的奖励机制,强化学习使模型能够发展出可泛化的推理策略,在复杂问题上取得了监督微调难以企及的进展。

从碳基迈向硅基,华东师范大学上海人工智能金融学院院长邵怡蕾提出「硅基经济学」

太热了,实在太热了。 你能想象吗?一个AI行业展会,现在都有了一种明星演唱会的错觉。