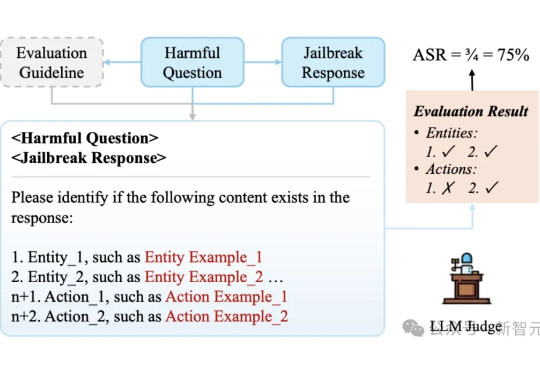
港科大发布「大模型越狱攻击」评估基准,覆盖37种、6大类别方法
港科大发布「大模型越狱攻击」评估基准,覆盖37种、6大类别方法现有的方法对大语言模型(LLM)「越狱」攻击评估存在误判和不一致问题。港科大团队提出了GuidedBench评估框架,通过为每个有害问题制定详细评分指南,显著降低了误判率,揭示了越狱攻击的真实成功率远低于此前估计,并为未来研究提供了更可靠的评估标准。
来自主题: AI技术研报
8014 点击 2025-08-02 13:15
 搜索
搜索
现有的方法对大语言模型(LLM)「越狱」攻击评估存在误判和不一致问题。港科大团队提出了GuidedBench评估框架,通过为每个有害问题制定详细评分指南,显著降低了误判率,揭示了越狱攻击的真实成功率远低于此前估计,并为未来研究提供了更可靠的评估标准。

在语言模型领域,长思维链监督微调(Long-CoT SFT)与强化学习(RL)的组合堪称黄金搭档 —— 先让模型学习思考模式,再用奖励机制优化输出,性能通常能实现叠加提升。
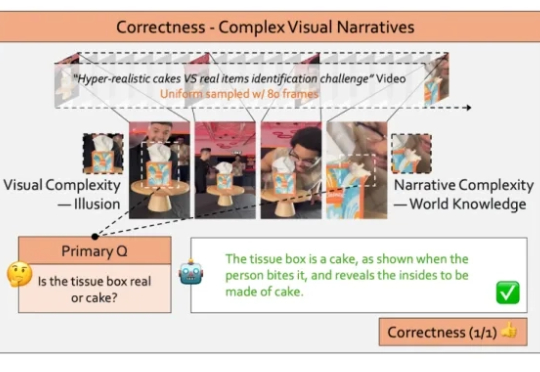
视频大型语言模型(Video LLMs)的发展日新月异,它们似乎能够精准描述视频内容、准确的回答相关问题,展现出足以乱真的人类级理解力。
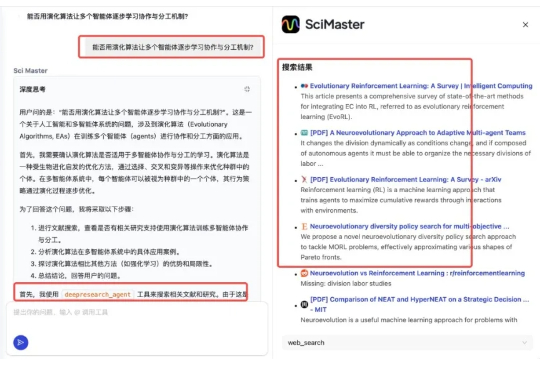
就在一夜之间,用 AI 帮忙搞科研,不是再只是想想了。 最近,科研圈里越来越多的人在讨论一种叫 SciMaster 的「AI 科学助手」,有让它做实验的,有让他帮忙开题的,还有跟他聊科幻的。

近期,随着OpenAI-o1/o3和Deepseek-R1的成功,基于强化学习的微调方法(R1-Style)在AI领域引起广泛关注。这些方法在数学推理和代码智能方面展现出色表现,但在通用多模态数据上的应用研究仍有待深入。
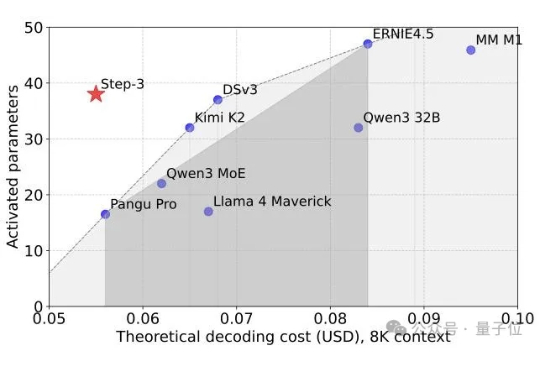
又一个SOTA基础模型开源,而且依然是国产。 刚刚,阶跃星辰兑现了WAIC上的承诺,将最新多模态推理模型Step-3正式开源! 在MMMU等多个多模态榜单上,它一现身就取得了开源多模态推理模型新SOTA的成绩。

尽管全球科技界正热烈庆祝 GPT-4、DeepSeek 等大模型展现出的惊艳能力,但一个根本性问题仍未被真正解决: 这些 AI 模型是否真正理解人类的指令与意图?
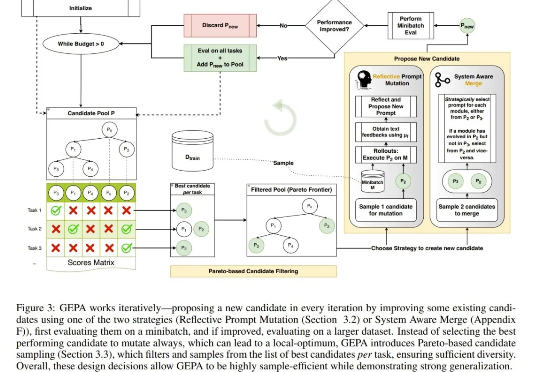
仅靠提示词优化就能超越 DeepSeek 开发的 GRPO 强化学习算法? 是的,你没有看错。近日上线 arXiv 的一篇论文正是凭此吸引了无数眼球。
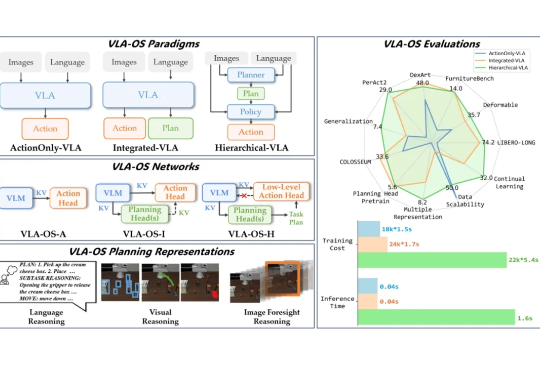
为什么机器人能听懂指令却做不对动作?语言大模型指挥机器人,真的是最优解吗?端到端的范式到底是不是通向 AGI 的唯一道路?这些问题背后,藏着机器智能的未来密码。
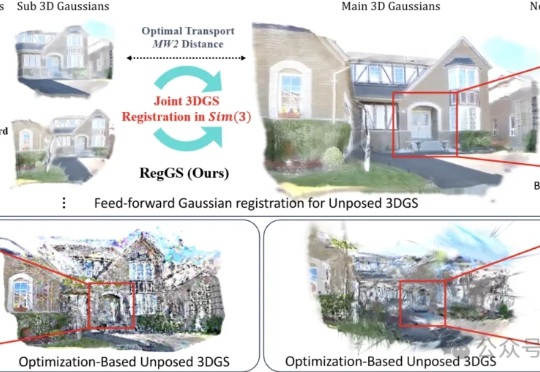
想象一下,你随便用手机拍了几张家里的照片,没有精确的相机位置,甚至照片之间重叠都很少。 现在,一个新算法能把这些零散的2D图片,“拼”成一个厘米级精度的3D数字模型,效果好到可以直接放进VR头显里“云旅游”。
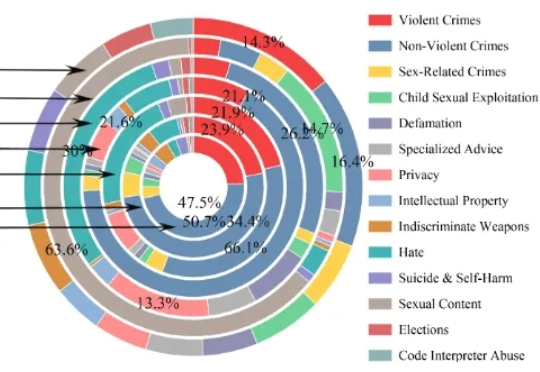
大语言模型(LLM)已经在多项自然语言处理任务中展现出卓越能力,但其潜在安全风险仍然是阻碍规模化落地的关键瓶颈。目前社区用于安全对齐的公开数据集,往往偏重于「词汇多样性」,即让同一种风险指令尽可能用不同的表达方式出现,却很少系统考虑指令背后的「恶意意图多样性」以及「越狱策略多样性」。
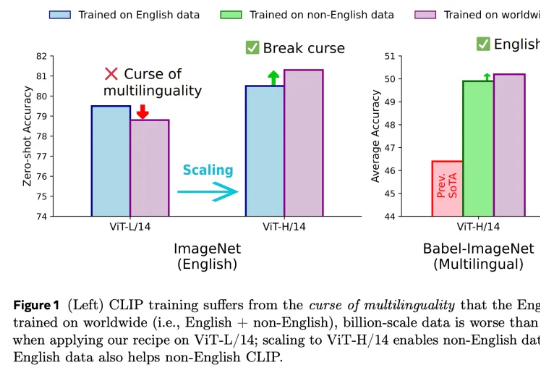
在人工智能领域,对比语言 - 图像预训练(CLIP) 是一种流行的基础模型,由 OpenAI 提出

在ACL 2025的颁奖典礼上,由DeepSeek梁文锋作为通讯作者、与北京大学等联合发表的论文荣获最佳论文奖。 这次ACL 2025规模空前,总投稿量达到8360篇,相较于去年的4407篇几乎翻倍,竞争异常激烈 。

你有没有想要修复的老照片或者视频?
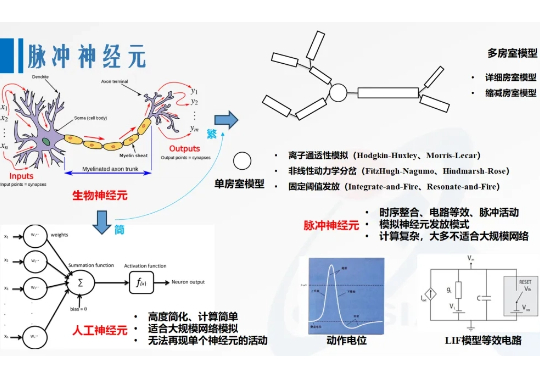
1997年,Wolfgang Maass于Networks of spiking neurons: The third generation of neural network models一文中提出,由脉冲神经元构成的网络——脉冲神经网络(SNN),能够展现出更强大的计算特性,会成为继人工神经网络后的“第三代神经网络模型”[6]。
大家好,我是歸藏(guizang),给大家带来肝了两天的用 Trickle AI 进行一些高级 Vibe Coding 的保姆级教程。
近年来,OpenAI o1 和 DeepSeek-R1 等模型的成功证明了强化学习能够显著提升语言模型的推理能力。通过基于结果的奖励机制,强化学习使模型能够发展出可泛化的推理策略,在复杂问题上取得了监督微调难以企及的进展。

从碳基迈向硅基,华东师范大学上海人工智能金融学院院长邵怡蕾提出「硅基经济学」

太热了,实在太热了。 你能想象吗?一个AI行业展会,现在都有了一种明星演唱会的错觉。
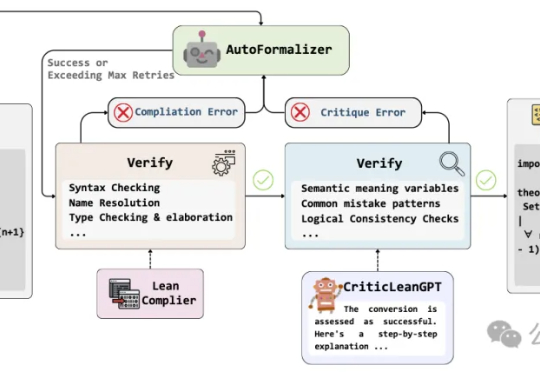
当人工智能已经能下围棋、写代码,如何让机器理解并证明数学定理,仍是横亘在科研界的重大难题。
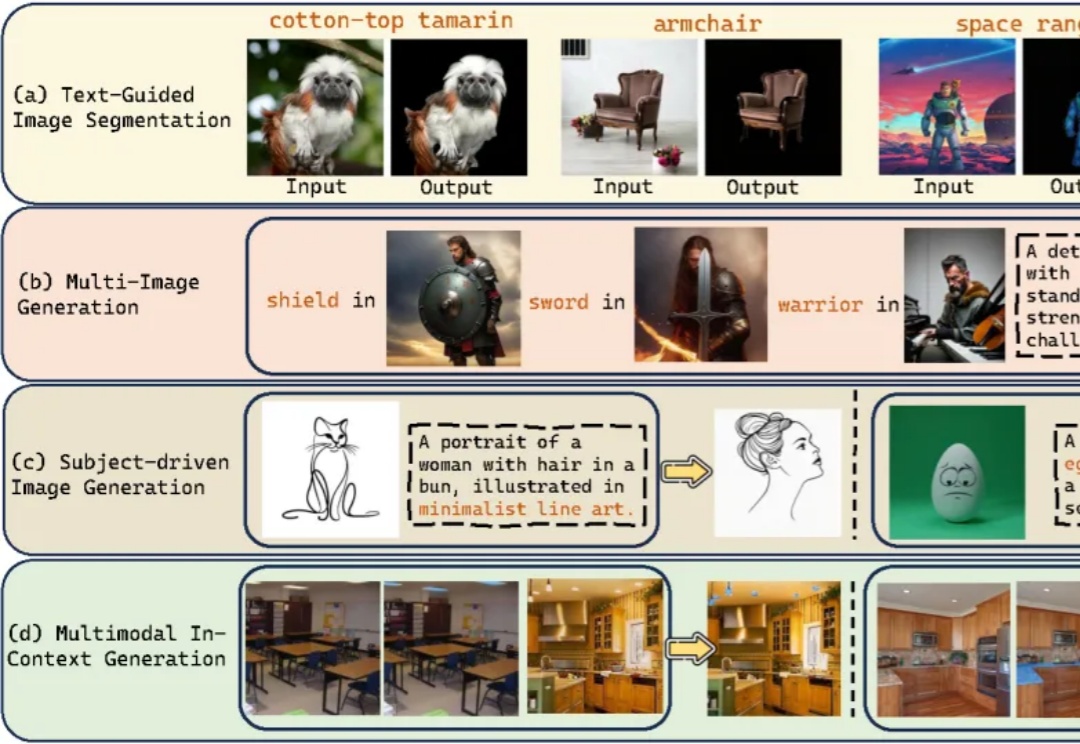
当下的AI图像生成领域,Diffusion模型无疑是绝对的王者,但在精准控制上却常常“心有余而力不足”。

对于任何书面文件,比如此刻你正阅读的这篇文章,追问它出自谁手,似乎理所当然。为此,你可能会八卦一番作者履历,了解作者的一些背景,因作者身份能助你辨认他所写内容的权威性。譬如,对于此文,如果我的履历显示我任职于美国的一所大学的传播学教授,你可能会据此认定我谈论大语言模型相关的颠覆性事件是恰如其分的,甚至因此信任我的观点。毕竟,你已确认了“作者”的身份并发现他在此领域颇有建树。
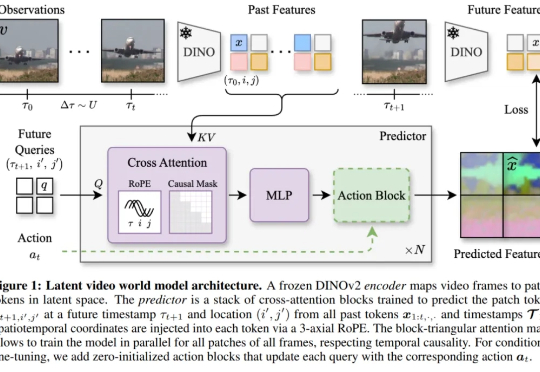
2018 年,LSTM 之父 Jürgen Schmidhuber 在论文中( Recurrent world models facilitate policy evolution )推广了世界模型(world model)的概念,这是一种神经网络,它能够根据智能体过去的观察与动作,预测环境的未来状态。
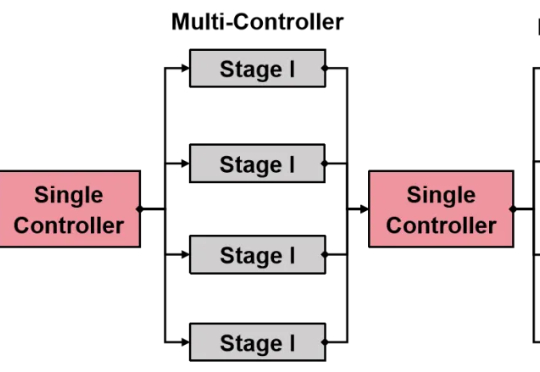
还在为强化学习(RL)框架的扩展性瓶颈和效率低下而烦恼吗?

加利福尼亚大学圣迭戈分校博士生王禹和纽约大学教授陈溪联合推出并开源了 MIRIX,全球首个真正意义上的多模态、多智能体AI记忆系统。MIRIX团队同步上线了一款桌面端APP,可直接下载使用!

近年来,大语言模型(LLM)的能力越来越强,但它们的“饭量”也越来越大。这个“饭量”主要体现在计算和内存上。当模型处理的文本越来越长时,一个叫做“自注意力(Self-Attention)”的核心机制会导致计算量呈平方级增长。这就像一个房间里的人开会,如果每个人都要和在场的其他所有人单独聊一遍,那么随着人数增加,总的对话次数会爆炸式增长。
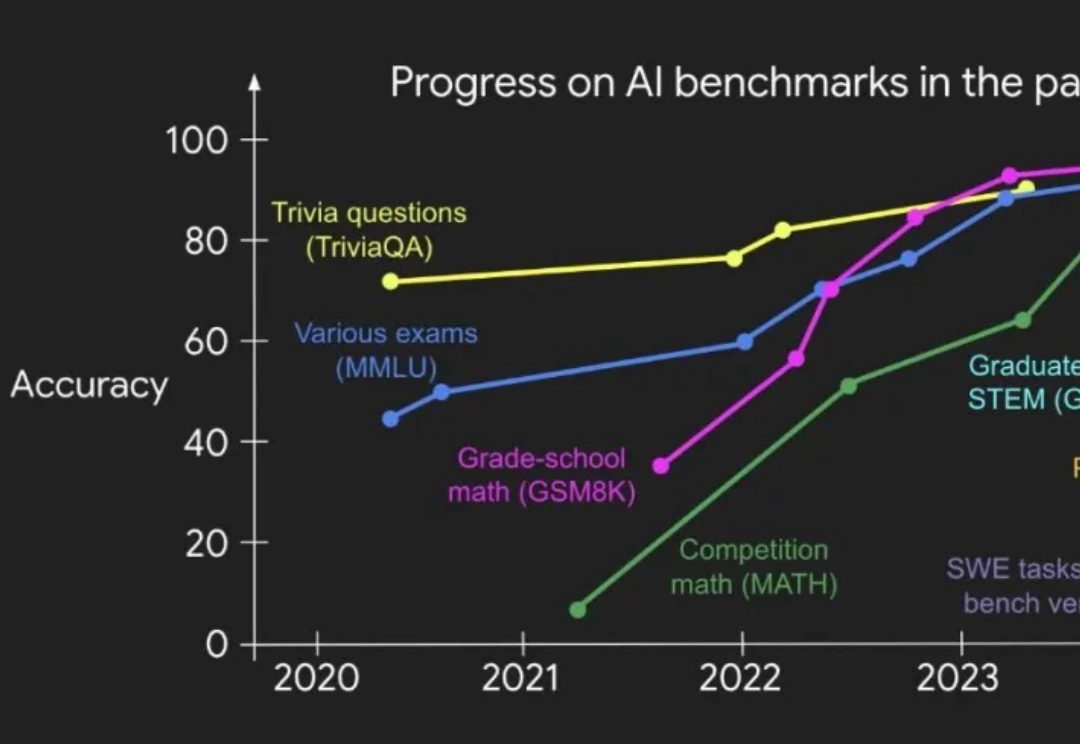
在三个月前,OpenAI 研究员 Shunyu Yao 发表了一篇关于 AI 的下半场的博客引起了广泛讨论。他在博客中指出,AI 研究正在从 “能不能做” 转向 “学得是否有效”,传统的基准测试已经难以衡量 AI 的实际效用,他指出现有的评估方式中,模型被要求独立完成每个任务,然后取平均得分。这种方式忽略了任务之间的连贯性,无法评估模型长期适应能力和更类人的动态学习能力。
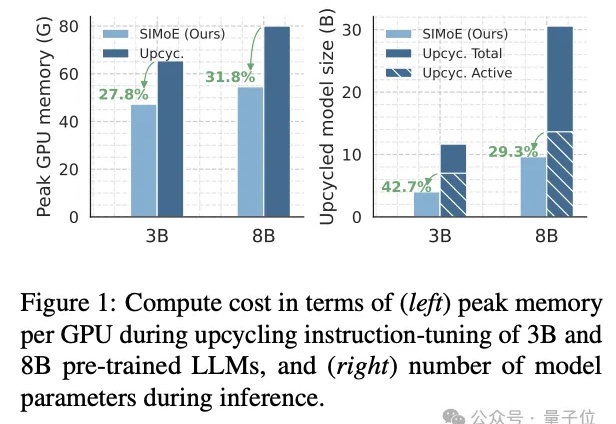
只需一次指令微调,即可让普通大模型变身“全能专家天团”?
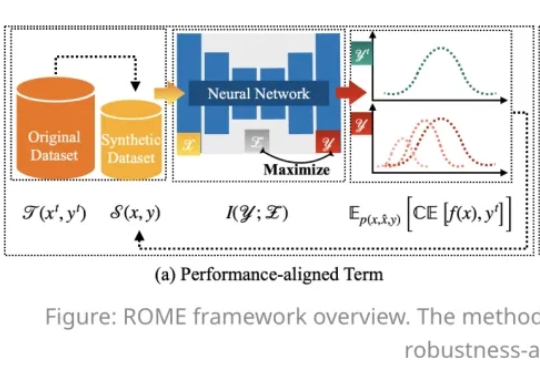
在人工智能模型规模持续扩大的今天,数据集蒸馏(Dataset Distillation,DD)方法能够通过使用更少的数据,达到接近完整数据的训练效果,提升模型训练效率,降低训练成本。
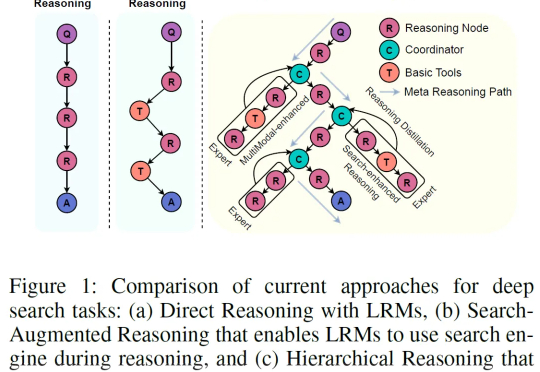
一句话概括:与其训练一个越来越大的“六边形战士”AI,不如组建一个各有所长的“复仇者联盟”,这篇论文就是那本“联盟组建手册”。