
完全免费可商用 Lummi AI 人工智能生成图库
完全免费可商用 Lummi AI 人工智能生成图库在今天数字图像无处不在,而高质量的图片对于各种项目至关重要。然而,许多人对于那些无聊、过度使用的传统库存照片感到厌倦,他们渴望与众不同、创新的视觉效果。这就是为什么 Lummi 库存图片的出现如此重要。
来自主题: AI资讯
7995 点击 2025-04-01 16:23
在今天数字图像无处不在,而高质量的图片对于各种项目至关重要。然而,许多人对于那些无聊、过度使用的传统库存照片感到厌倦,他们渴望与众不同、创新的视觉效果。这就是为什么 Lummi 库存图片的出现如此重要。

AI 医疗公司 OpenEvidence 在 2 月份获得红杉资本新一轮的 7500 万美元融资,估值超过 10 亿美元,成为了新的 AI 独角兽。
Runway带着新一代视频生成模型Gen-4杀回来了!

OpenAI真的要开源了!奥特曼官宣,即将开源自GPT-2以来的首款推理模型,可在消费级硬件上运行。同时,OpenAI又拿到了最高400亿单轮融资,估值直冲3000亿。

当你幻想买彩票中“一个小目标”时,可能已经掉进了电诈的连环骗局。

当AI科技的浪潮撞上了各家游戏公司对“降本增效”的迫切需求,过去的几年里,行业里只要能叫上名的企业集体尝试把AI加入生产流程,力求“花小钱办大事”。
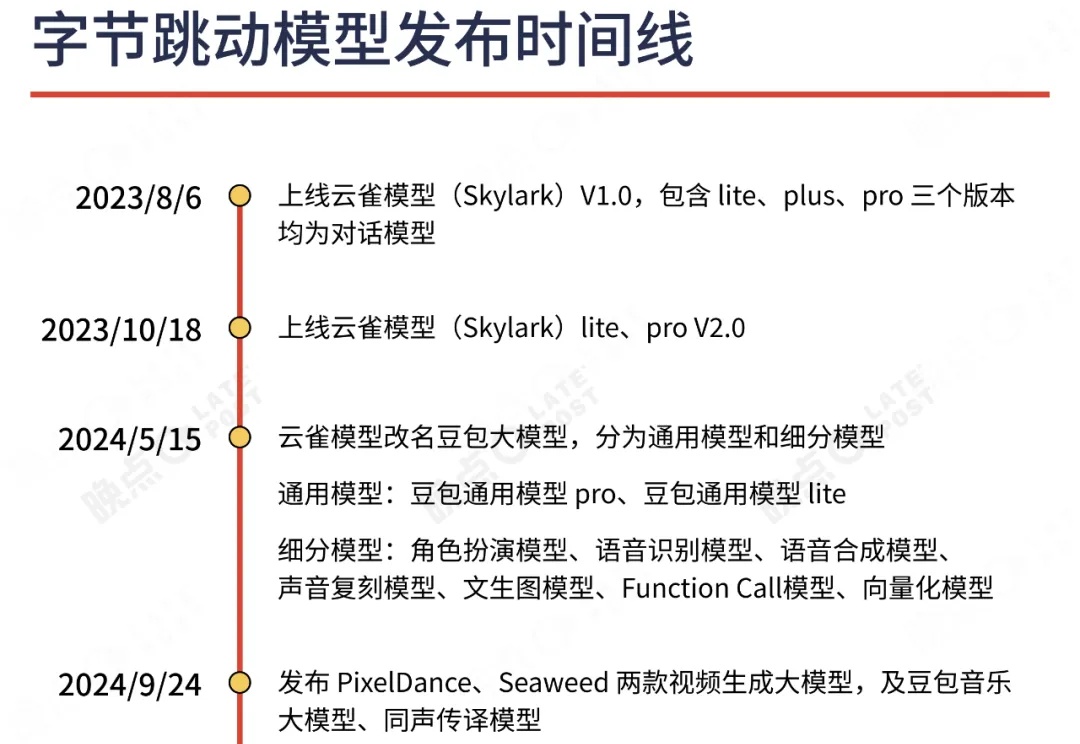
面对 AI,字节依然是那个字节:一旦看到有潜力的方向,就加倍、饱和、全面出击。
红杉资本、A16Z 最近讨论了对语音人工智能初创公司 Sesame 的融资。该公司专注于开发人工智能语音助手和可穿戴设备。

最近,ChatGPT 4o 新上线了多模态绘图功能,‘吉卜力’刷爆了特工们朋友圈的同时,也夹带着艺术设计圈朋友们的哀嚎,最让我们共情的莫过于推上的此段发言:
这比真人都真

从Google Glasses到HoloLens,再到近几年雷鸟创新、Even Realities、影目、星纪魅族、Rokid等陆续发布量产产品,AR眼镜在不断刷新其轻薄程度。
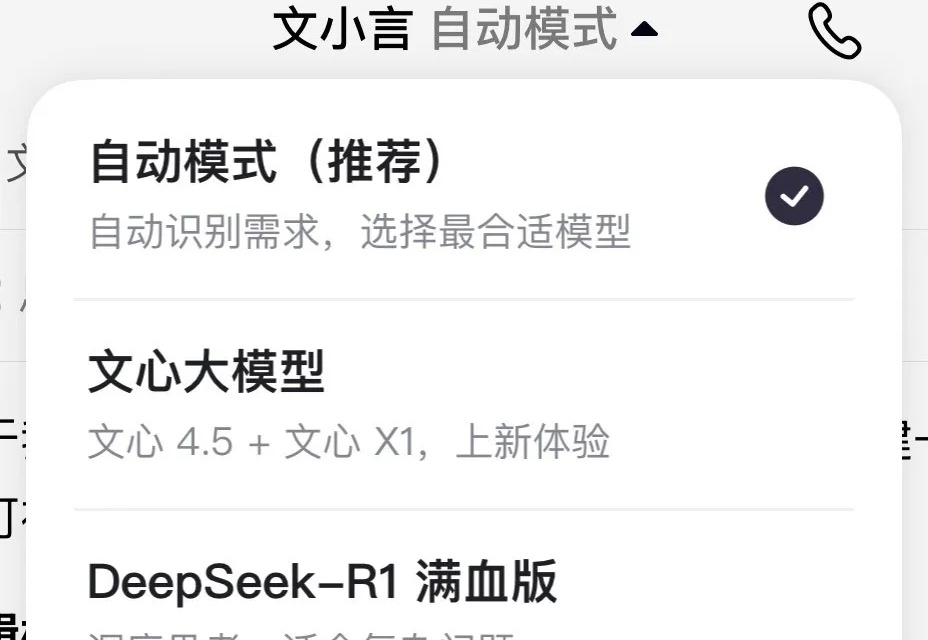
刚刚,百度文小言全面升级了。

“创业公司不要浪费一分钱去训练底层模型”、“所有的应用都是套壳应用,关键是如何构建长期壁垒”。

目前AI短剧还在“有没有”的阶段,但普通观众在乎的是“好不好看”。

一夜之间,OpenAI更新三大动向,开源、融资、用户暴增。第一,将开源一个具备推理能力的大语言模型,包含参数权重那种。上一次这样开源还是6年前推出GPT-2。

今天凌晨,Runway的新版本Gen-4又试图解决AI视频的一个关键难题,让AI视频更靠近电影级。这一切都只发生在短短的2个多月内,很难想象今年AI会发展到什么程度,或许今年将会是GPT-3.5后真正的AI爆发年。

DeepSeek的出圈,不仅引爆了全社会对于AI的大讨论,更重要的是激发各界人士从观望者转变为参与者,掀起了一波真实的人工智能落地潮。在孕育了AI的互联网生态中,AI引起的变化会首当其冲,且影响更彻底。广告作为互联网生态最主要的商业模式,更是当前AI技术应用的主战场。

比尔·盖茨近期重磅预测:十年内,人类每周只需工作两天!而让这成为可能的,正是AI的快速发展。但与此同时,医生、教师等众多职业却面临被取代的命运,职场即将迎来前所未有的巨震。
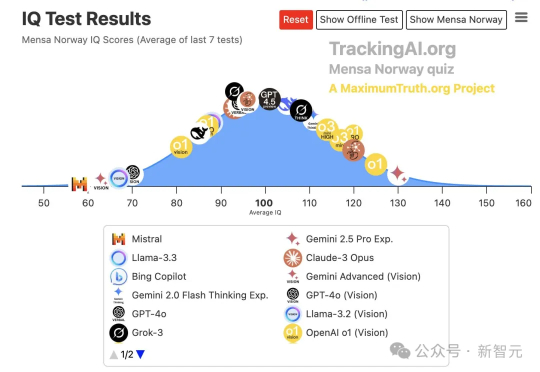
如今,有越来越多的网友发现,Gemini 2.5 Pro已经成为全球大模型中名副其实的冠军,刷爆各类基准测试和智商测试!它的智商达到130,其中数学方面已经强于大多数研究生,甚至几句提示,就能模拟宇宙规律。

这周,Midjourney即将带着全新V7强势归来。内部模型已训完,目前开启了评分系统,进入最后微调阶段。网友已放出生图,效果惊艳,画质细腻度拉满。

什么?! 用AI Agent搞的小红书账号,竟然14天狂吸5000粉,还开始赚钱了???

DeepSeek要开放融资了?

黄晓煌很忙。
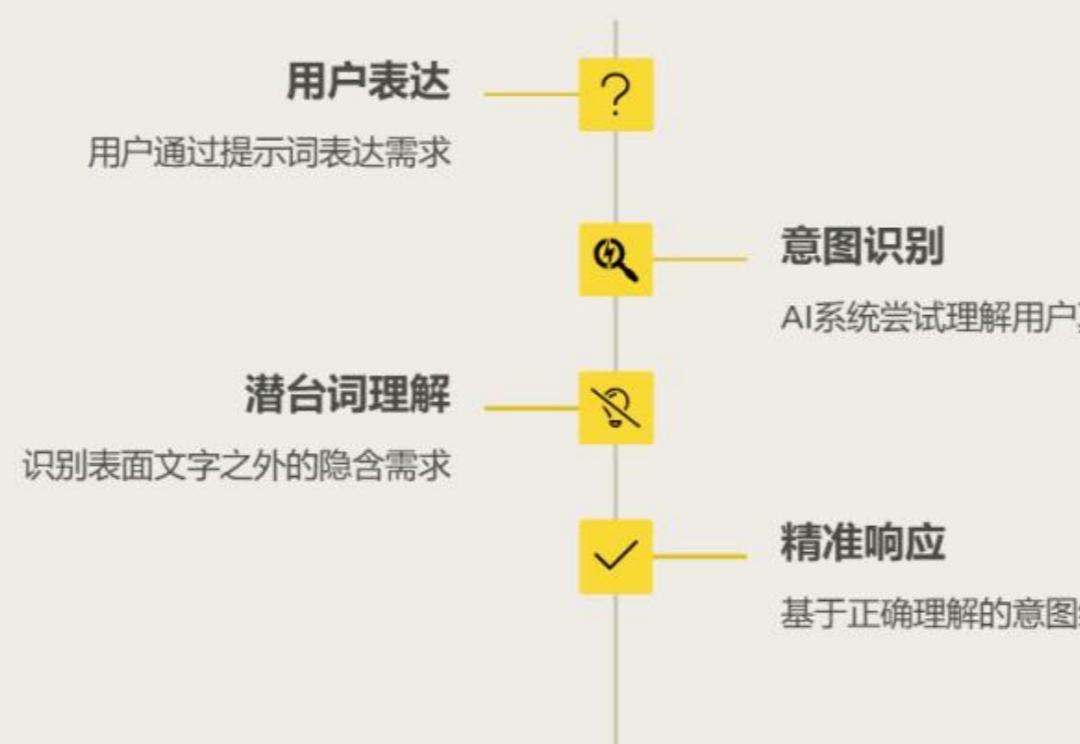
Prompt 为什么重要

目前,有个开源MCP合集算是github上最火的合集之一,已经超过20000颗星评价相当高,并且还在不断高频率迭代更新。估计以后会成为标杆MCP开源库吧。

两家期刊实验表明,250美元报酬,能加快评审速度而不降低质量。但专家警告,现金激励可能悄然改变科研生态,这将为学术评审带来新生,还是埋下隐患?
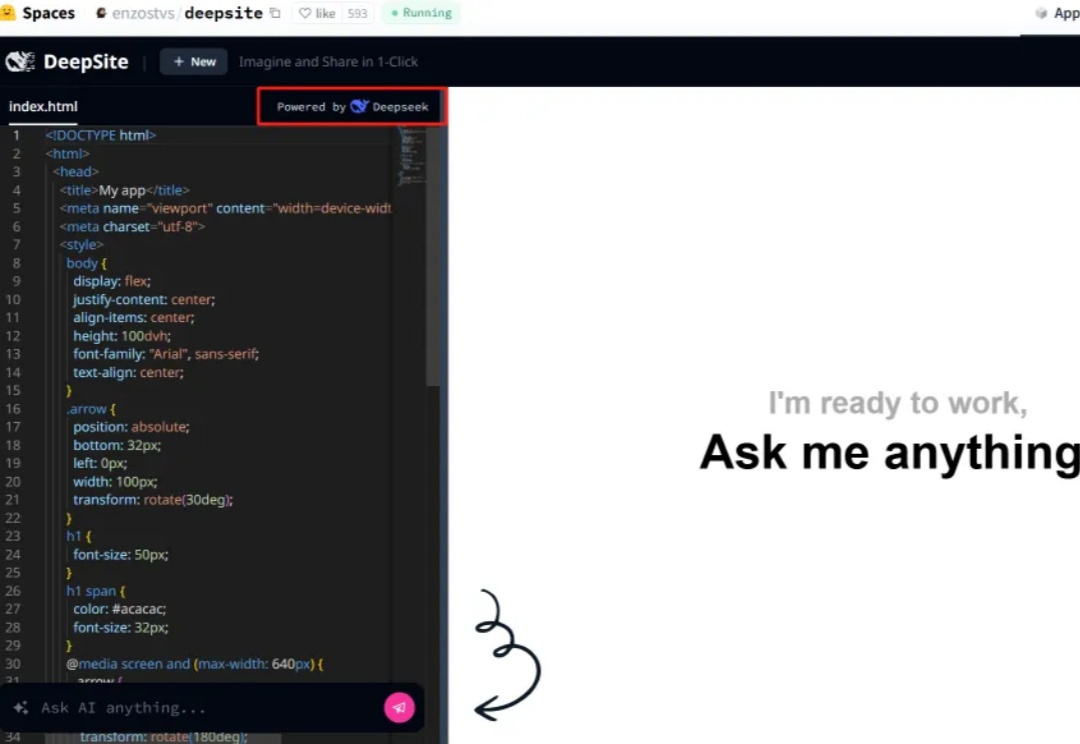
最近超火的氛围编程(Vibe coding)你听说了吗?

好好好,具身智能领域又有公司宣布融资新动态了!

GPT-4o玩家太疯狂,奥特曼紧急呼吁别再生成图片了:OpenAI团队为此一直在熬夜。为什么需要熬夜呢,自原生图像生成推出以来,必须一直有人守着才能保持服务器在线。

说真的,即使玩过了这么多的DeepResearch产品,我也没想到,他们能扔出个这么个有趣的玩意。这个产品叫做,AutoGLM沉思版。