
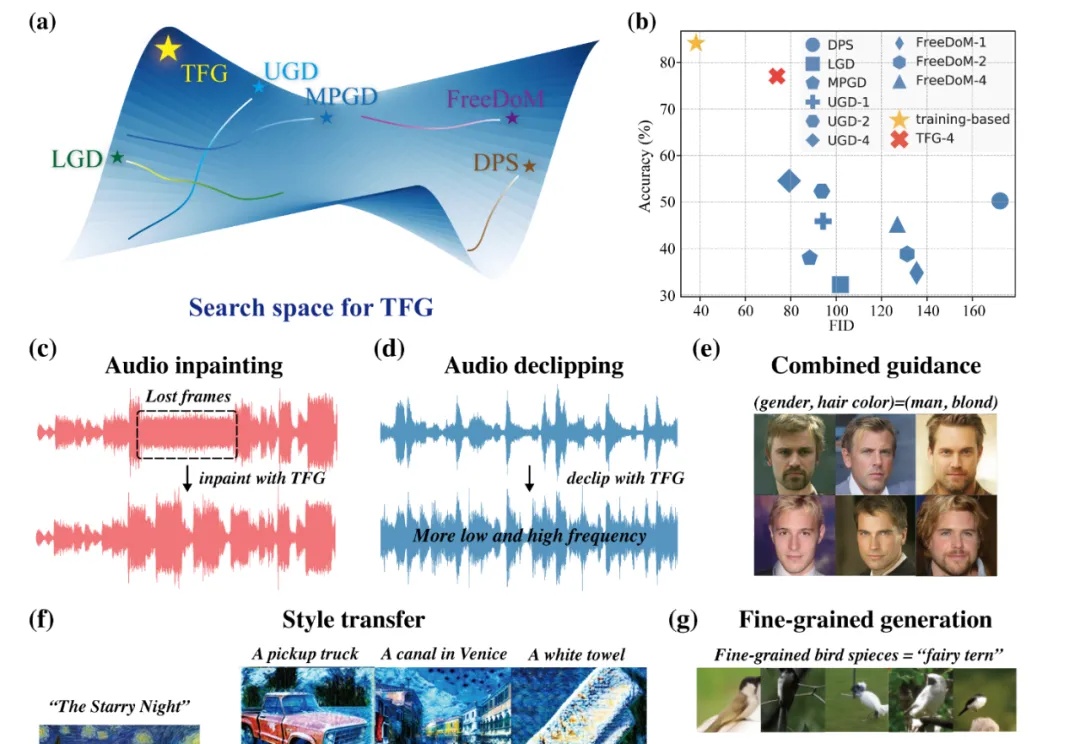
NeurIPS Spotlight|从分类到生成:无训练的可控扩散生成
NeurIPS Spotlight|从分类到生成:无训练的可控扩散生成近年来,扩散模型(Diffusion Models)已成为生成模型领域的研究前沿,它们在图像生成、视频生成、分子设计、音频生成等众多领域展现出强大的能力。
来自主题: AI技术研报
6043 点击 2024-12-05 11:49
近年来,扩散模型(Diffusion Models)已成为生成模型领域的研究前沿,它们在图像生成、视频生成、分子设计、音频生成等众多领域展现出强大的能力。
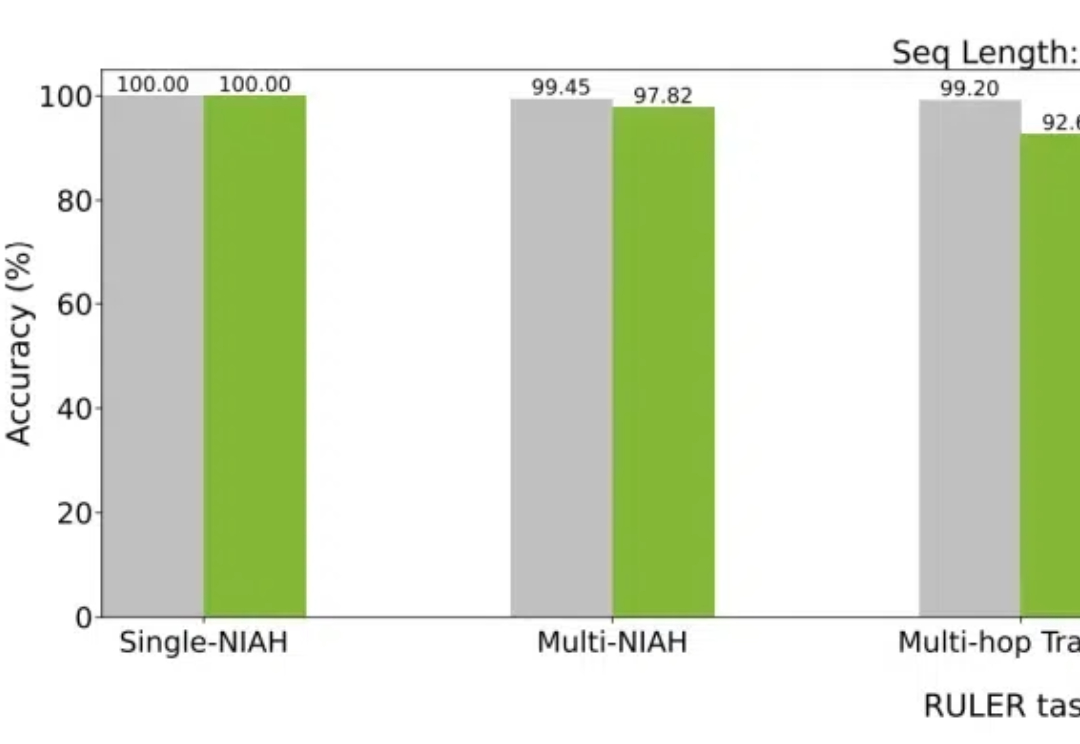
大模型如今已具有越来越长的上下文,而与之相伴的是推理成本的上升。英伟达最新提出的Star Attention,能够在不损失精度的同时,显著减少推理计算量,从而助力边缘计算。
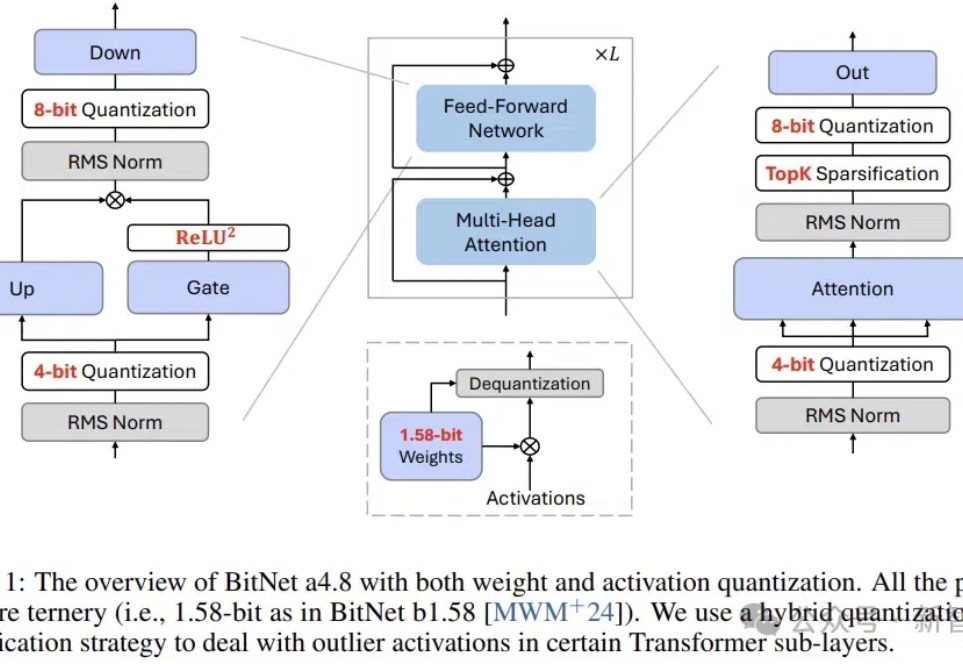
近日,BitNet系列的原班人马推出了新一代架构:BitNet a4.8,为1 bit大模型启用了4位激活值,支持3 bit KV cache,效率再突破。

几个小时前,著名 AI 研究者、OpenAI 创始成员之一 Andrej Karpathy 发布了一篇备受关注的长推文,其中分享了注意力机制背后一些或许少有人知的故事。
今天,ICLR 2025的discussion phase的ddl已经截止。回看过去14天的讨论过程,可太精彩了!

刚刚,人工智能顶会 NeurIPS 公布了今年的最佳论文(包括 Best Paper 和 Best Paper Runner-up,大会注册者可以看到)。
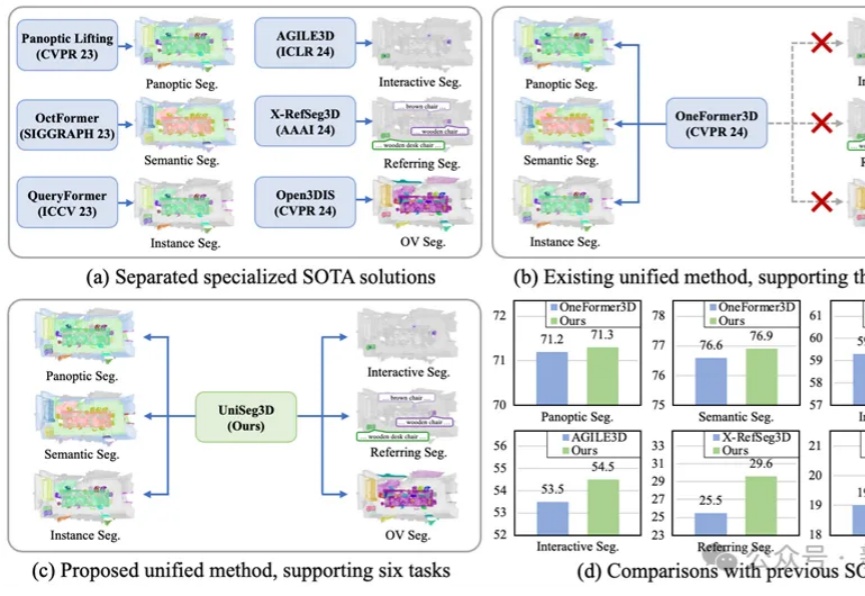
华中科技大学研发的UniSeg3D算法,能一次性完成三维场景中的六项分割任务,提升了场景理解的全面性和效率。通过任务间的信息共享,优化了性能,为虚拟现实和机器人导航等领域带来新的解决方案。
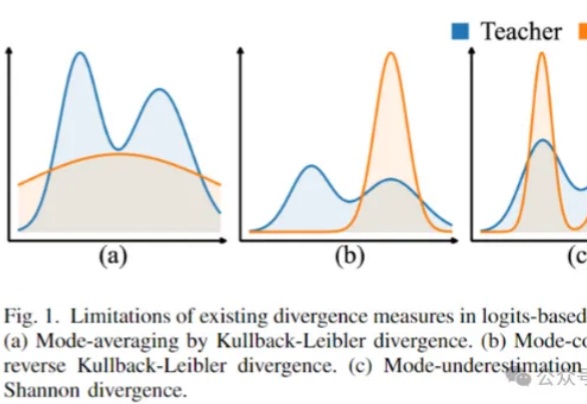
用大模型“蒸馏”小模型,有新招了!
想要体验文生视频的小伙伴又多了一个选择!
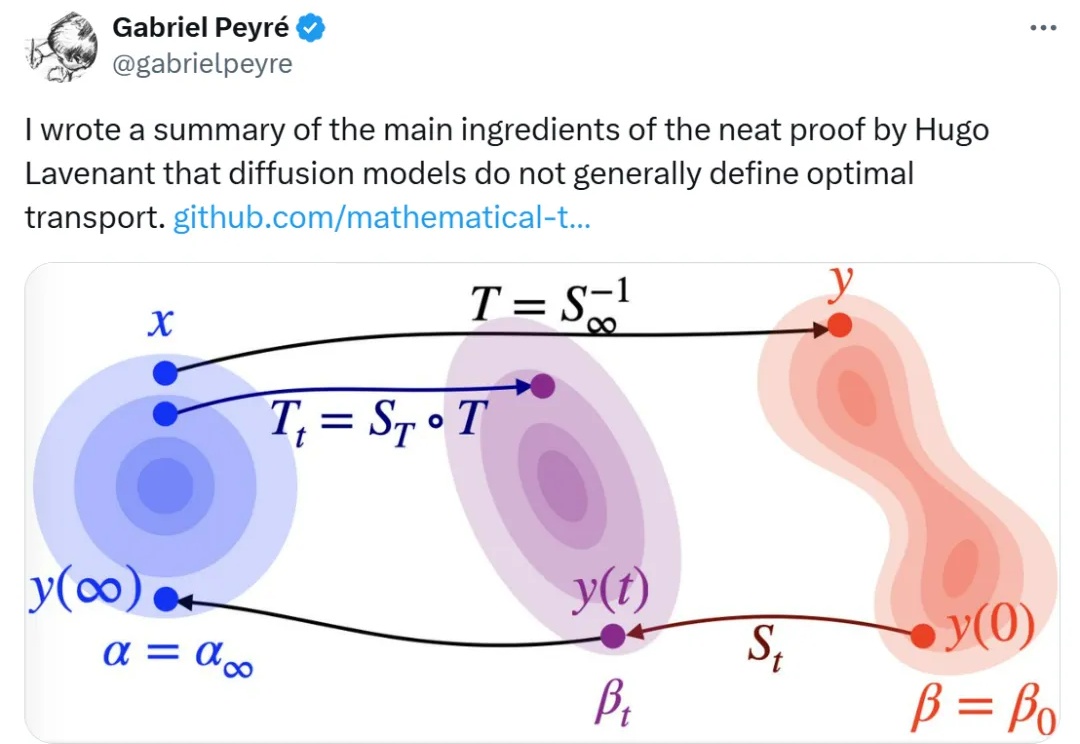
扩散模型和最优传输之间到底存在怎样的联系?对很多人来说还是一个未解之谜。
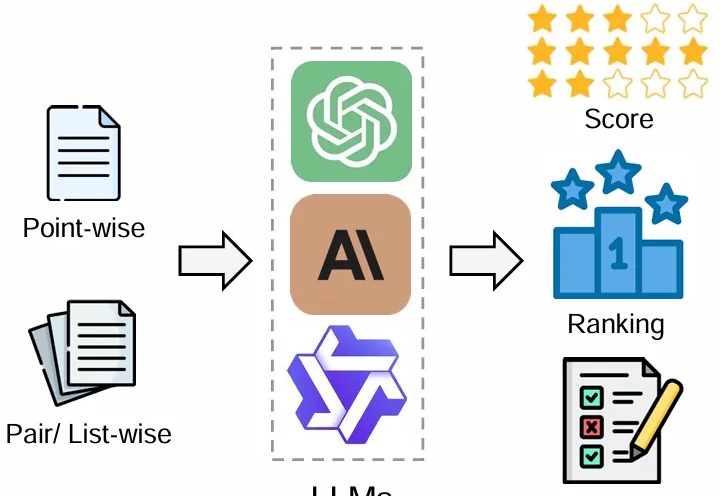
评估和评价长期以来一直是人工智能 (AI) 和自然语言处理 (NLP) 中的关键挑战。然而,传统方法,无论是基于匹配还是基于词嵌入,往往无法判断精妙的属性并提供令人满意的结果。
我记得很久之前,我们都在讲什么低代码/无代码平台,这个概念很久了,但是,一直没有很好的落地,整体的效果也不算好。

斯坦福大学推出的IKEA Video Manuals数据集,通过4D对齐组装视频和说明书,为AI理解和执行复杂空间任务提供了新的挑战和研究基准,让机器人或AR眼镜指导家具组装不再是梦。
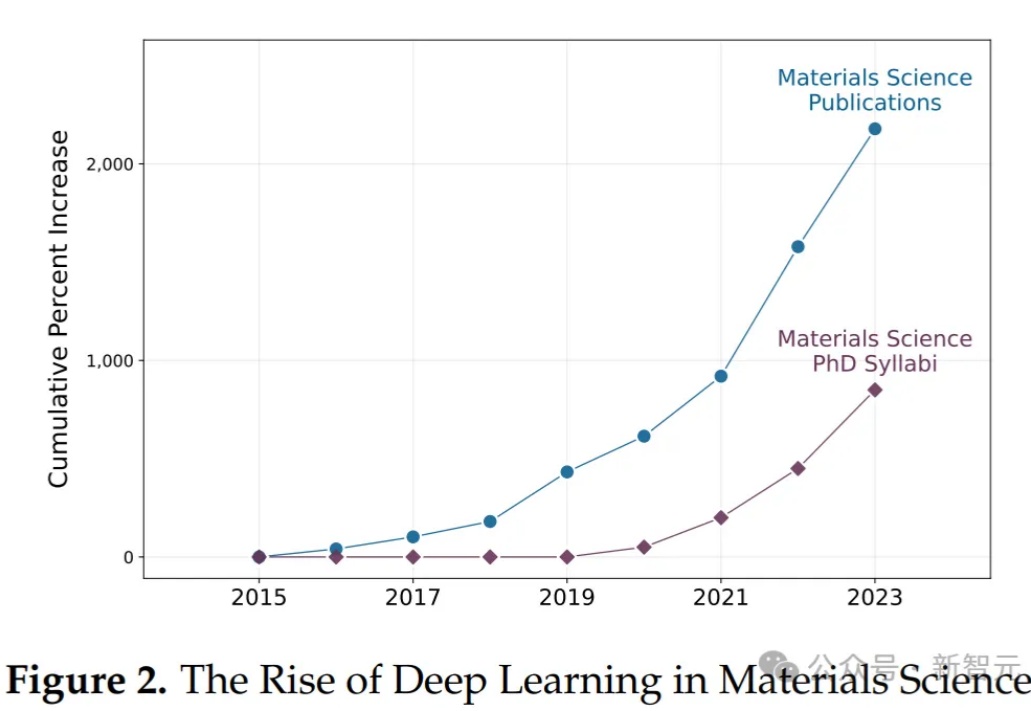
MIT的76页深度报告!AI辅助创新显著增长——这毋庸置疑。但,值得注意的是,AI加剧了不同水平科学家产出的差异,这与科学家的判断力强相关,意味着缺乏判断力的科学家在未来可能会被慢慢淘汰……

如何让机器人拥有人一样的协调行动能力是具身智能不可避免的挑战,而李飞飞团队在CoRL-LEAP研讨会获得最佳论文奖的ReKep对于这一挑战交出了一张亮眼的答卷。
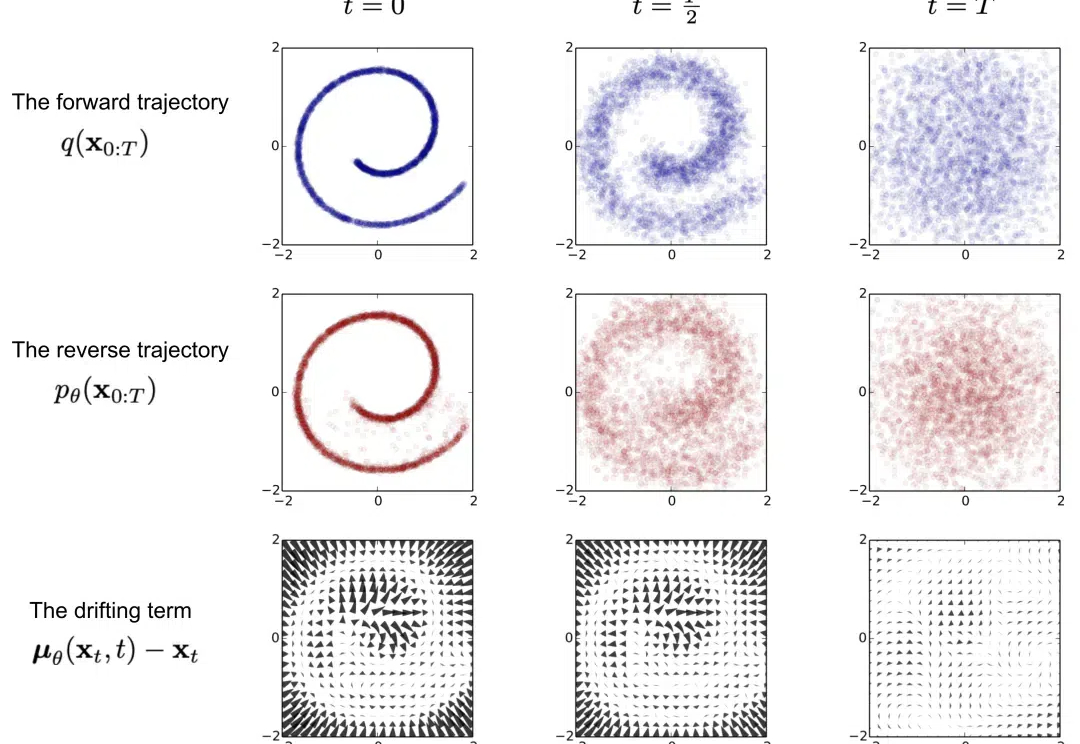
昨天,为大家介绍了生成式对抗网络GAN,今天再来为大家介绍另一个有趣的模型:扩散模型,包括Stability AI、OpenAI、Google Brain在内的多个研究团队基于扩散模型提出了多种创新模型,如以文生图、图像生成视频生成等~
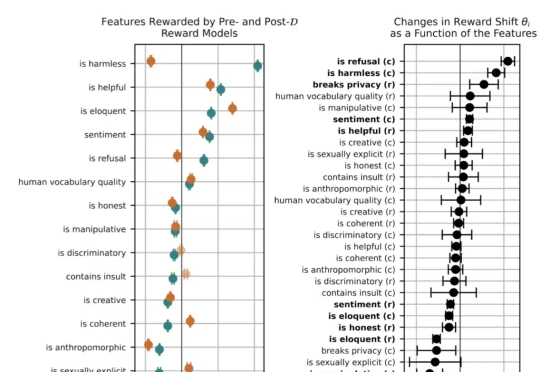
之前领导OpenAI安全团队的北大校友翁荔(Lilian Weng),离职后第一个动作来了。当然是发~博~客。这次的博客一如既往万字干货,妥妥一篇研究综述,翁荔本人直言写起来不容易。主题围绕强化学习中奖励黑客(Reward Hacking)问题展开,即Agent利用奖励函数或环境中的漏洞来获取高奖励,而并未真正学习到预期行为。
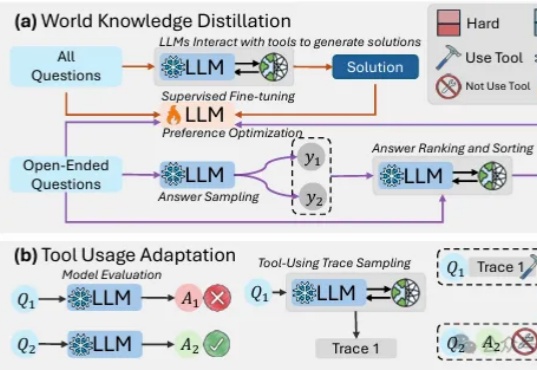
最近,一支来自UCSD和清华的研究团队提出了一种全新的微调方法。经过这种微调后,一个仅80亿参数的小模型,在科学问题上也能和GPT-4o一较高下!或许,单纯地卷AI计算能力并不是唯一的出路。
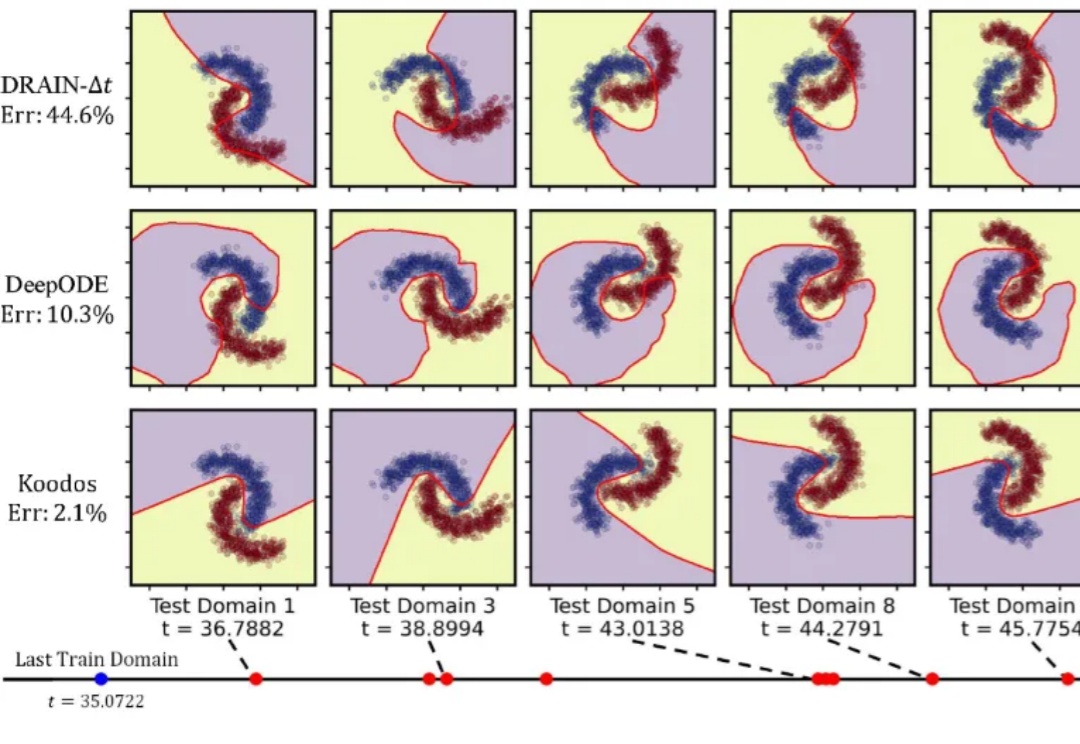
研究人员提出了一种方法,能够在领域数据分布持续变化的动态环境中,基于随机时刻观测的数据分布,在任意时刻生成适用的神经网络,实现前所未有的泛化能力。

LLM在推理时,竟是通过一种「程序性知识」,而非照搬答案?可以认为这是一种变相的证明:LLM的确具备某种推理能力。然而存在争议的是,这项研究只能提供证据,而非证明。
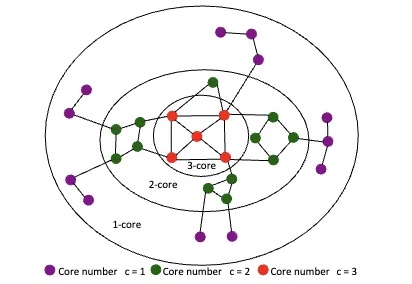
大语言模型直接理解复杂图结构的新方法来了:
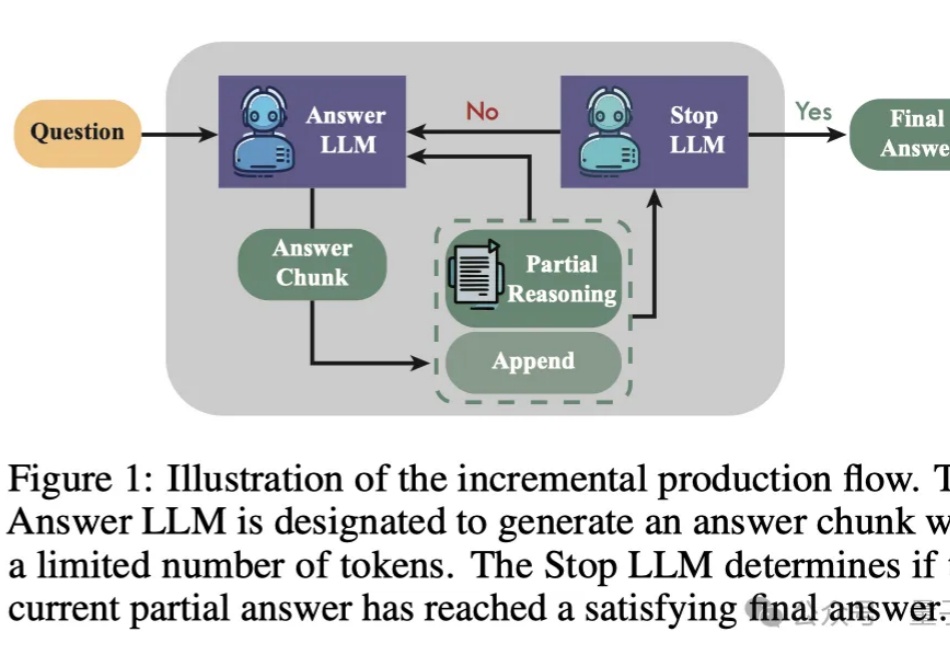
提升LLM数学能力的新方法来了——
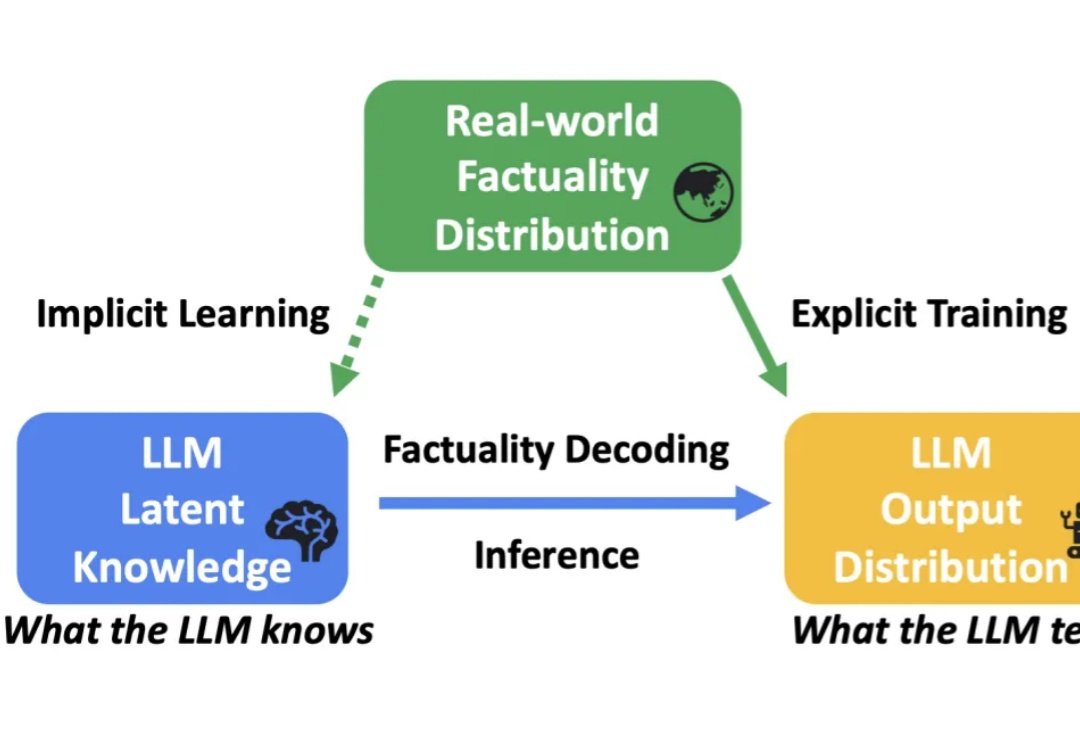
大语言模型(LLM)在各种任务上展示了卓越的性能。然而,受到幻觉(hallucination)的影响,LLM 生成的内容有时会出现错误或与事实不符,这限制了其在实际应用中的可靠性。
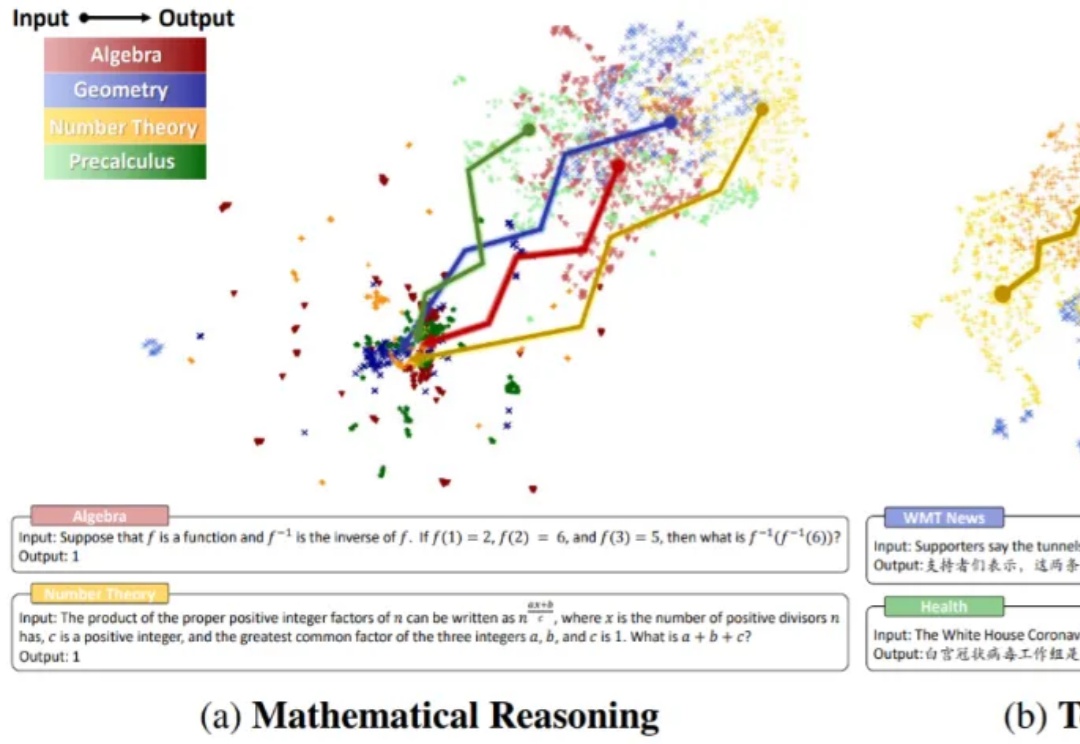
本文将介绍数学推理场景下的首个分布外检测研究成果。

自我博弈,很神奇吧?
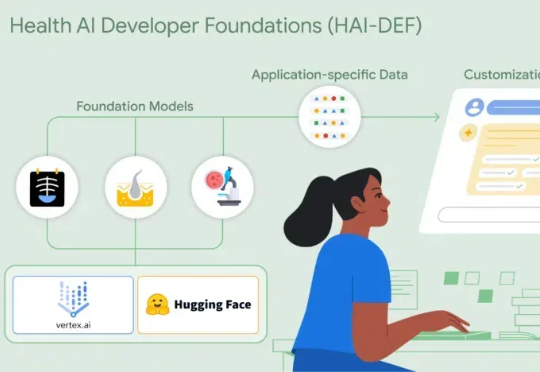
Google研究院健康AI团队于近日推出了全新的开源模型套件——Health AI Developer Foundations(HAI-DEF)。在本次HAI-DEF的首次发布中,Google推出了三个专注于医疗影像应用的重要模型。首先是CXR Foundation胸部X光模型,其次是Derm Foundation皮肤影像模型,第三个是Path Foundation病理学模型,它基于ViT-S架构

一天开发一个 App,听起来像是个天方夜谭吧?说实话,几年前我也觉得不可能,但在今天,借助强大的 AI 工具和合理的工作流,这事儿真的变得触手可及。当然,这并不意味着可以随便敷衍,而是需要一套高效的方法论。今天,我就来分享一下我们团队在一天内开发一个 App 的完整流程。

对于LLM来说,人类语言可能不是最好的交流媒介,正如《星战》中的机器人有自己的一套语言,近日,来自微软的研究人员改进了智能体间的交互方式,使模型的通信速度翻倍且不损失精度。
![ICLR 惊现[10,10,10,10]满分论文,ControlNet 作者新作,Github 5.8k 颗星](https://www.aitntnews.com/pictures/2024/12/1/f51d4442-afae-11ef-81ba-fa163e47d677.jpg)
四个 10 分!罕见的一幕出现了。 您正在收看的,不是中国梦之队的跳水比赛,而是 ICLR 2025 的评审现场。 虽说满分论文不是前无古人,后无来者,但放在平均分才 4.76 的 ICLR,怎么不算是相当炸裂的存在呢。
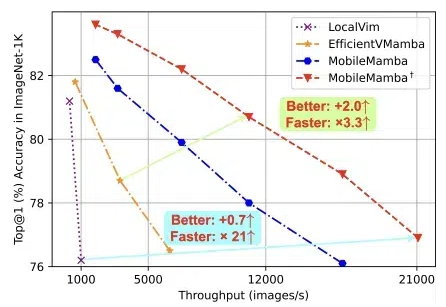
浙大、腾讯优图、华中科技大学的团队,提出轻量化MobileMamba! 既良好地平衡了效率与效果,推理速度远超现有基于Mamba的模型。