

AI搜索公司,仅成立2年,为什么估值超600亿?7000字长文解析AI搜索未来的五大趋势
AI搜索公司,仅成立2年,为什么估值超600亿?7000字长文解析AI搜索未来的五大趋势今天我们就来看看AI搜索赛道为什么能跑出估值超600亿的独角兽?
来自主题: AI技术研报
6694 点击 2024-11-26 09:27
今天我们就来看看AI搜索赛道为什么能跑出估值超600亿的独角兽?
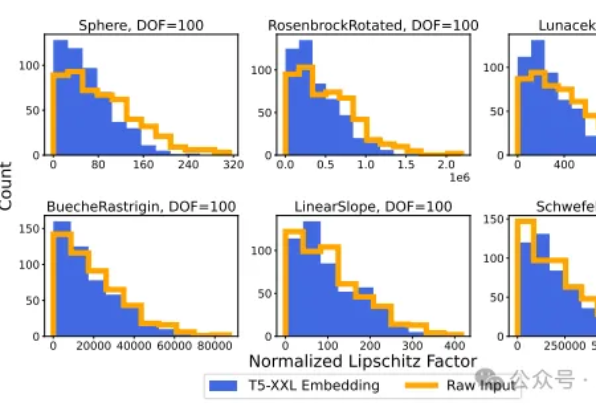
在人工智能领域,大语言模型(LLM)的向量嵌入能力一直被视为处理文本数据的利器。然而,斯坦福大学和Google DeepMind的研究团队带来了一个颠覆性发现:LLM的向量嵌入能力可以有效应用于回归任务。
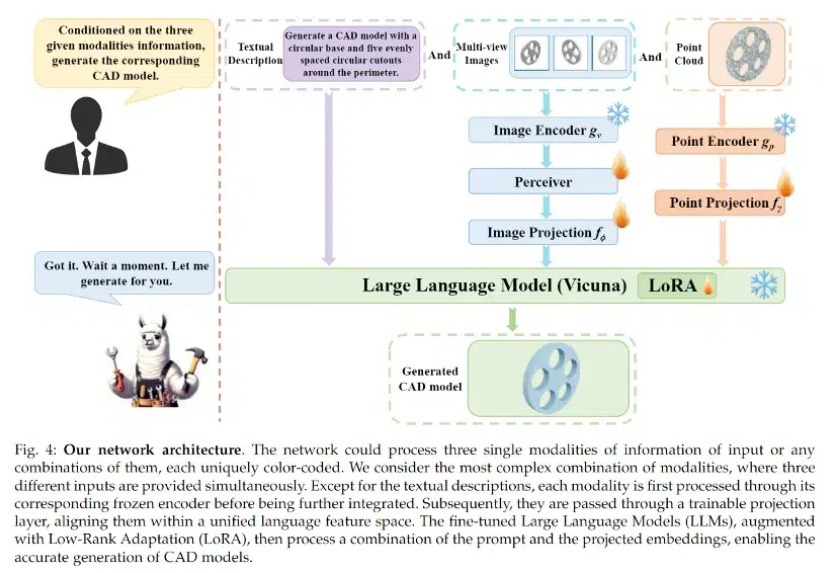
该项目由忆生科技联合香港大学、上海科技大学共同完成,是全球首个同时支持文本描述、图像、点云等多模态输入的计算机辅助设计(CAD)生成大模型。
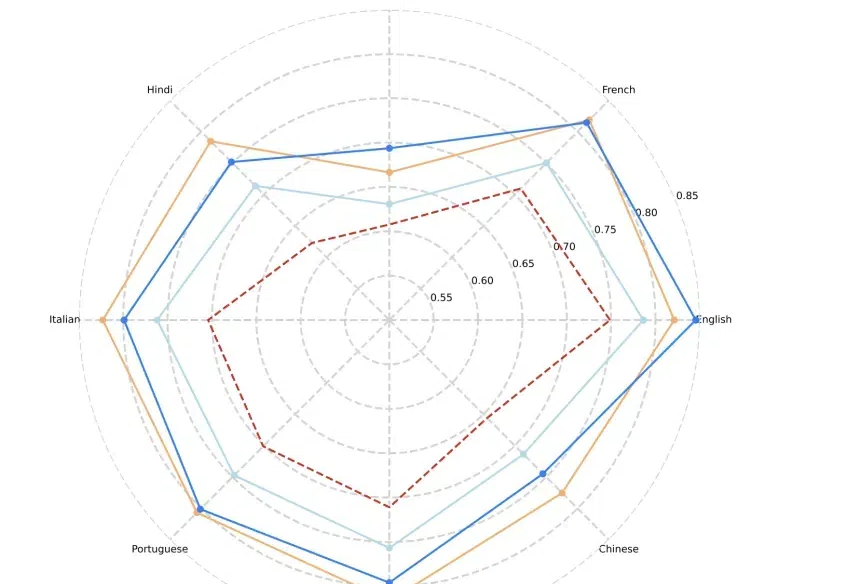
Meta全新发布的基准Multi-IF涵盖八种语言、4501个三轮对话任务,全面揭示了当前LLM在复杂多轮、多语言场景中的挑战。所有模型在多轮对话中表现显著衰减,表现最佳的o1-preview模型在三轮对话的准确率从87.7%下降到70.7%;在非拉丁文字语言上,所有模型的表现显著弱于英语。

Hugging Face 上的模型数量已经超过了 100 万。但是几乎每个模型都是孤立的,难以与其它模型沟通。尽管有些研究者甚至娱乐播主试过让 LLM 互相交流,但所用的方法大都比较简单。
奥特曼“熹妃回宫”已一周年,具体内情还是不清楚,咋办?
2小时内,Claude和o1就能超过人类专家平均科研水平。
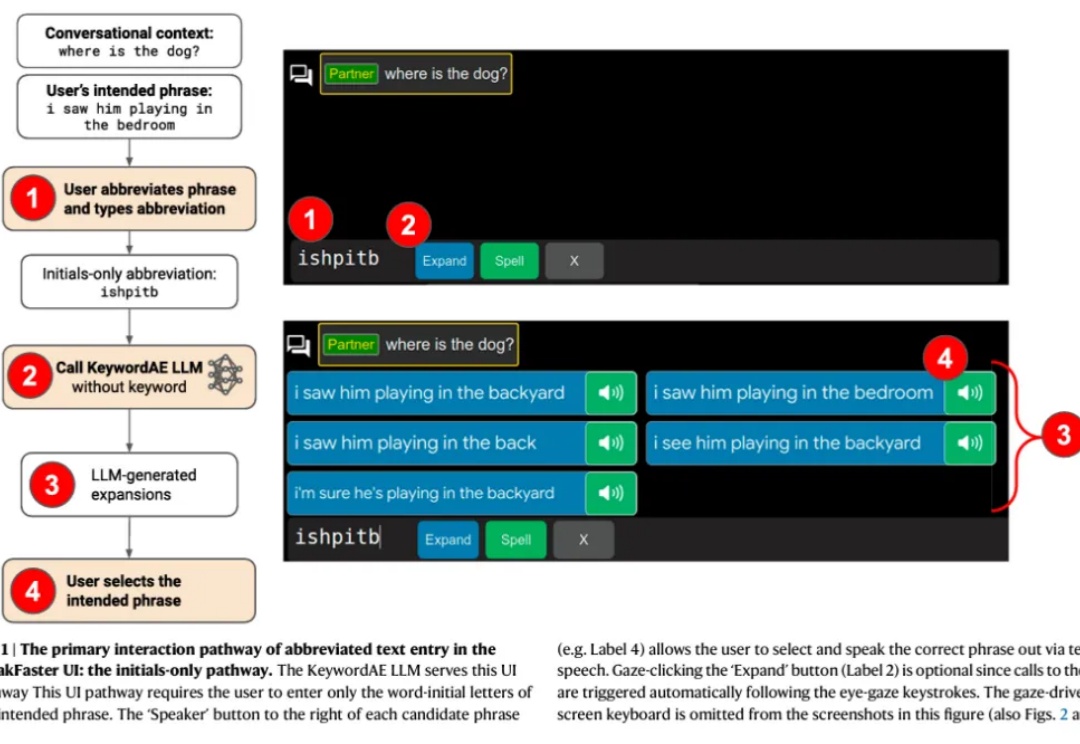
因渐冻症(ALS)等病症而无法言语或打字的人群不容忽视,他们在日常沟通交流中面临着巨大障碍,急需有效的辅助手段来打破沟通壁垒。

LangChain 最近调查了 1,300 多名专业人士——从工程师和产品经理到企业领导者和高管——以揭示 AI Agents 的现状。
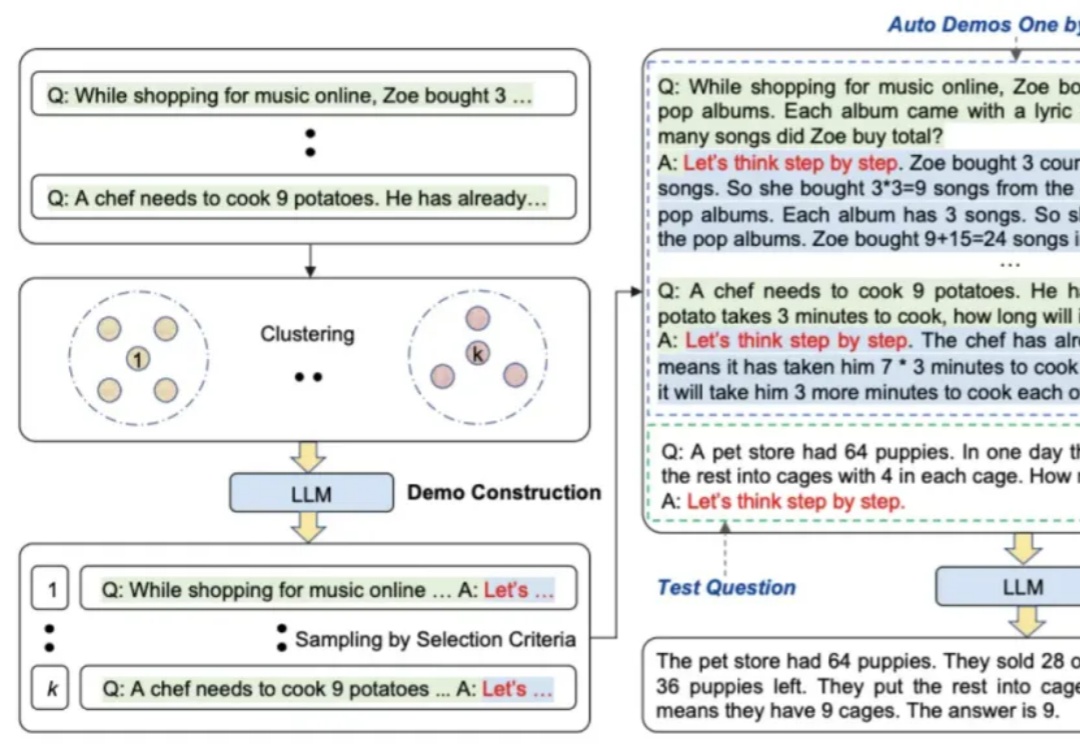
本文主要介绍prompt engineering的多种方法
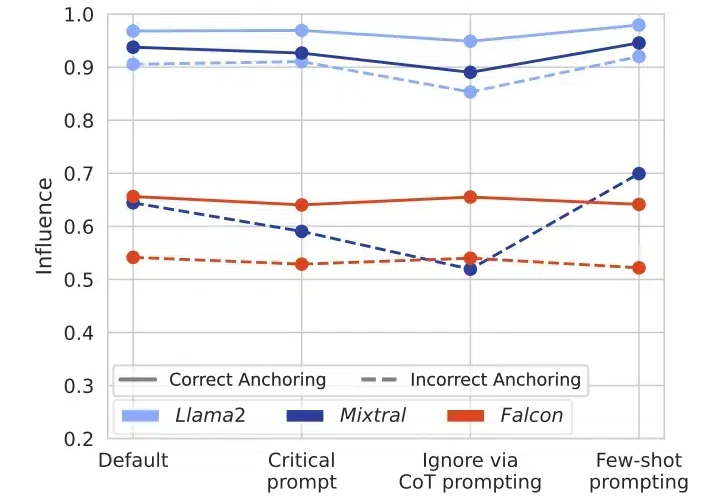
在当今人工智能迅猛发展的时代,大语言模型(LLMs)已成为众多AI应用的核心引擎。然而,来自ETH Zurich和Google DeepMind的一项最新研究揭示了一个令人深思的现象:这些看似强大的模型存在着严重的“盲从效应”。
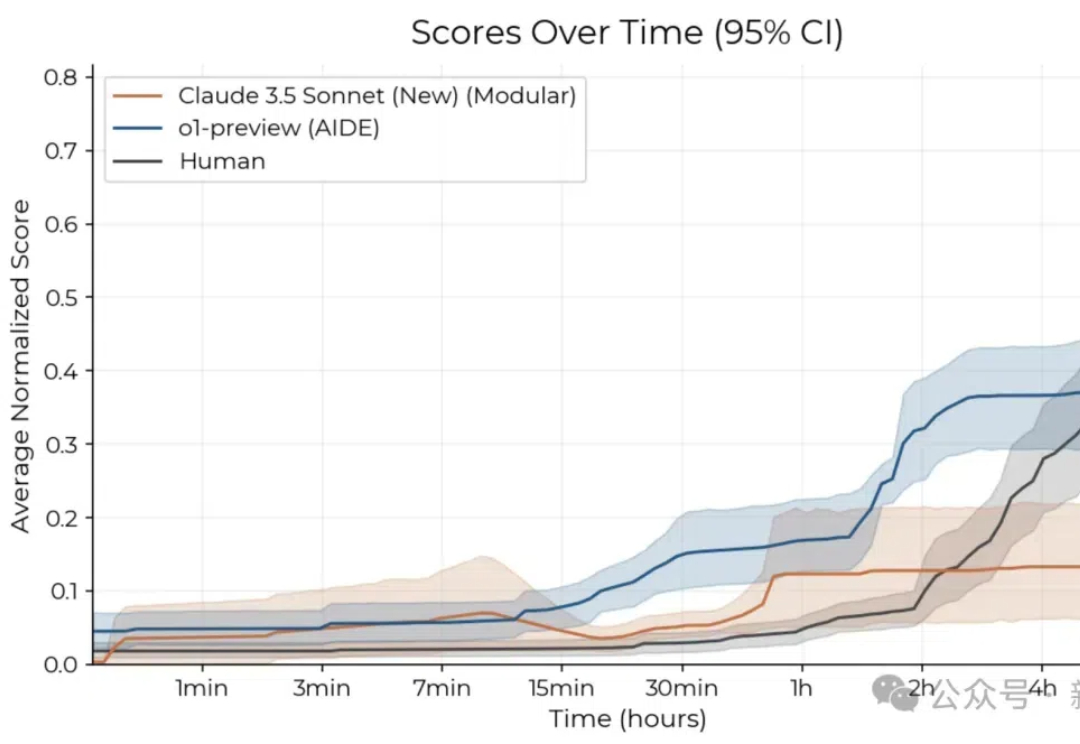
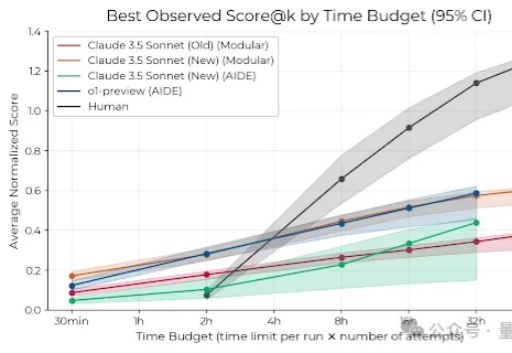
AI自主研发会真的「失控」了吗?最新研究显示,Claude 3.5 Sonnet和o1-preview在2小时内的研发任务中,击败了50多位人类专家。但另一个耐人寻味的现象是,给予更长时间周期后,人类专家在8小时任务中优势显现。
曾经每天都用谷歌学术的科学家们,正在转向新的AI工具。

Meta的视频版分割一切——Segment Anything Model 2(SAM 2),又火了一把。

扩散模型的本质竟是进化算法!生物学大佬从数学的角度证实了这个结论,并结合扩散模型创建了全新的进化算法。
我们对小型语言模型的增强方法、已存在的小模型、应用、与 LLMs 的协作、以及可信赖性方面进行了详细调查。
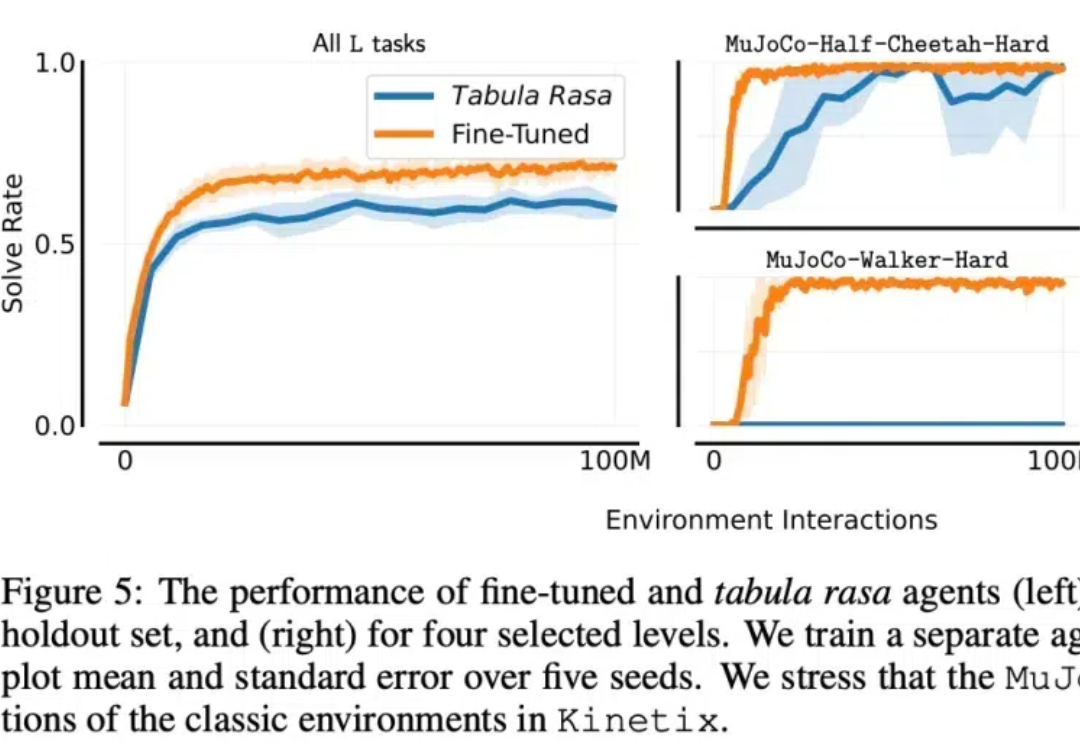
在机器学习领域,开发一个在未见过领域表现出色的通用智能体一直是长期目标之一。一种观点认为,在大量离线文本和视频数据上训练的大型 transformer 最终可以实现这一目标。
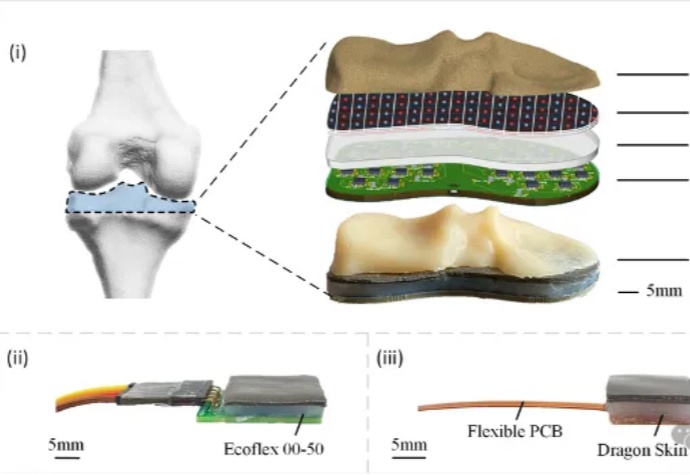
触觉是人类感知外部环境并与之交互的重要知觉形式。
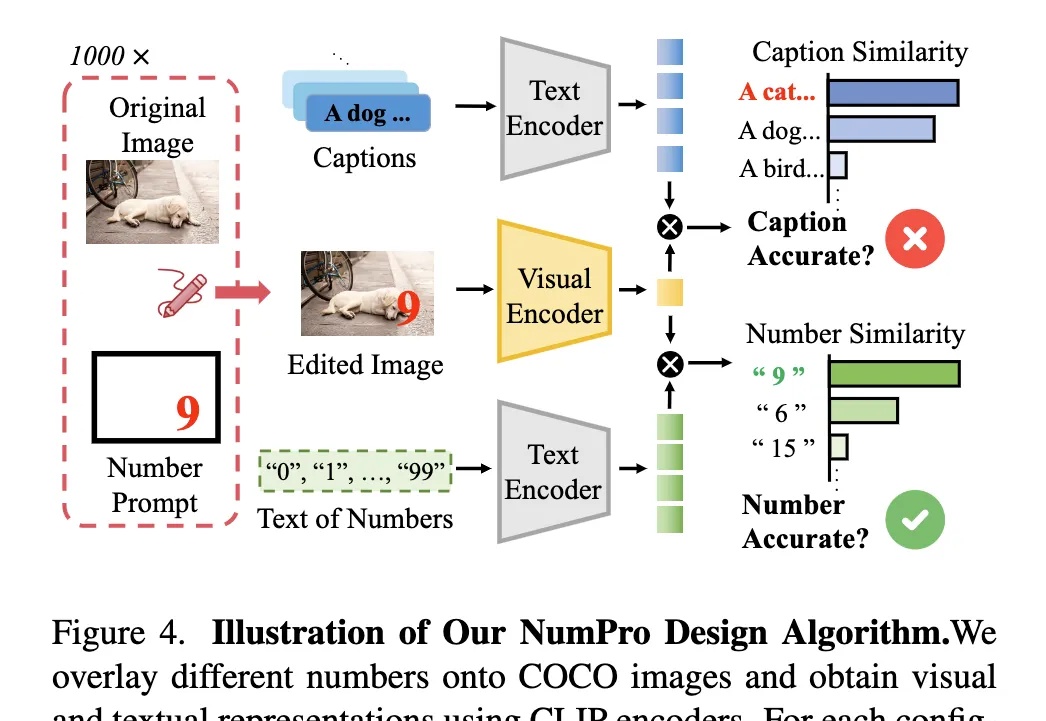
用看漫画的方式,大幅提升视频大模型时序定位能力!
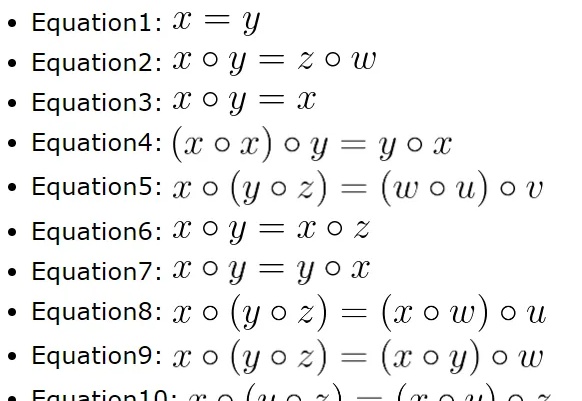
57天,人类和AI合作搞定了4694个等式之间22028942个蕴含关系!
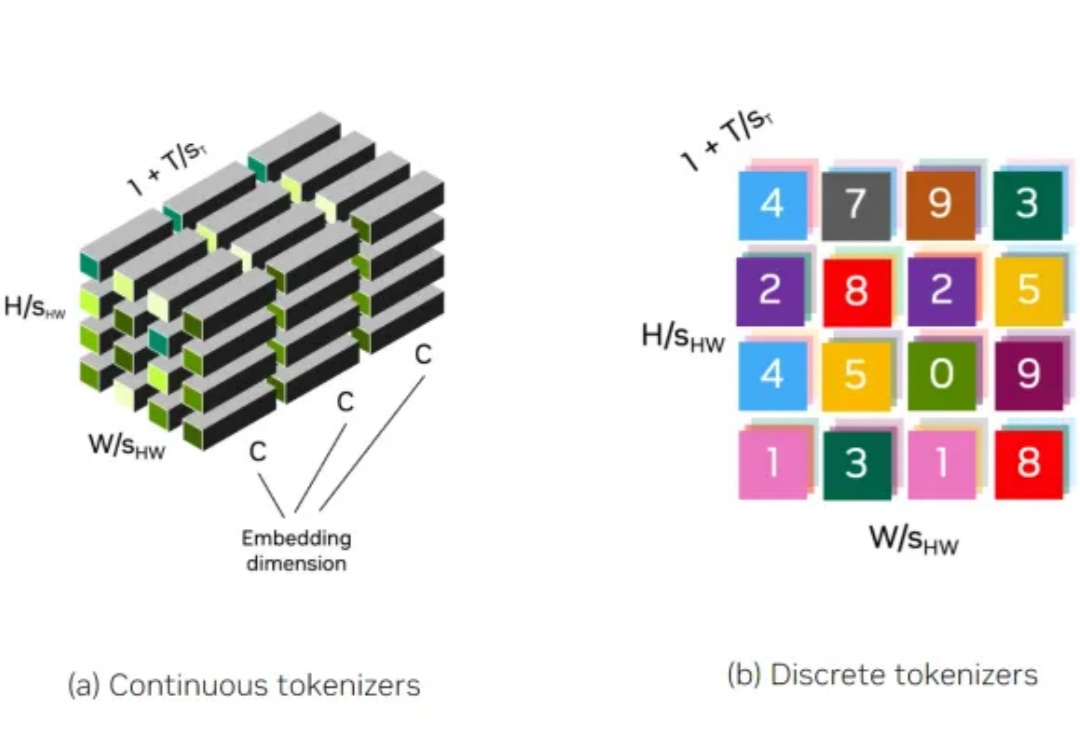
tokenizer对于图像、视频生成的重要性值得重视。
自从 OpenAI 发布 o1 模型以来,业界对其的追赶不断加速。
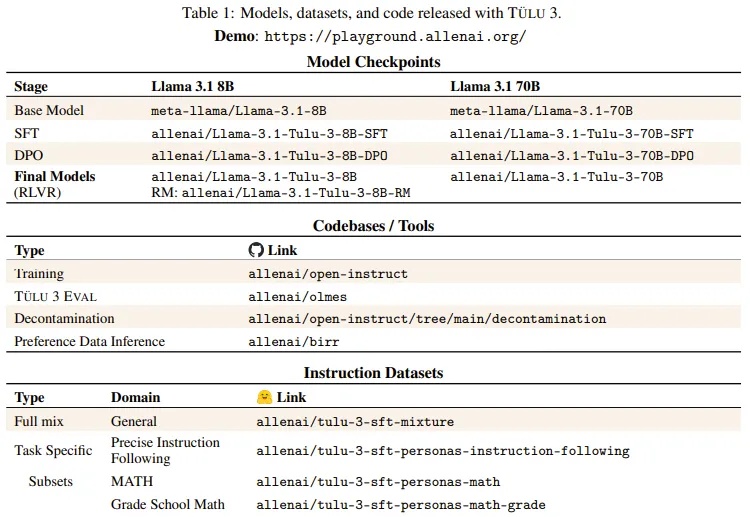
开源模型阵营又迎来一员猛将:Tülu 3。它来自艾伦人工智能研究所(Ai2),目前包含 8B 和 70B 两个版本(未来还会有 405B 版本),并且其性能超过了 Llama 3.1 Instruct 的相应版本!长达 73 的技术报告详细介绍了后训练的细节。
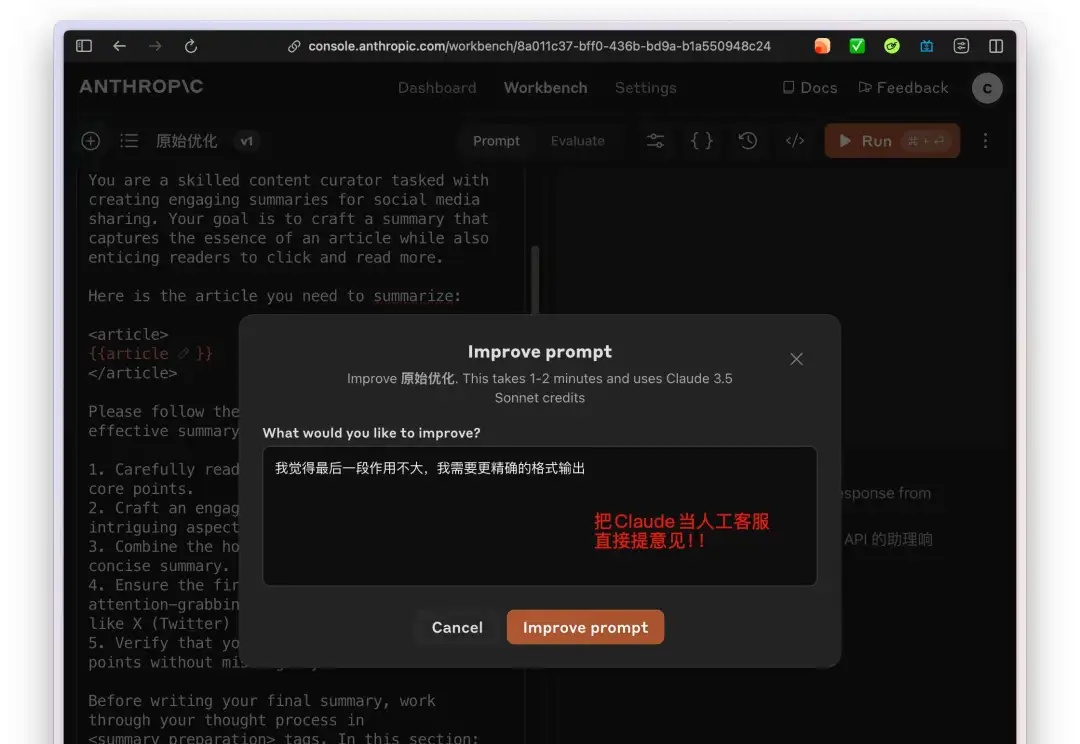
每个神级 Prompt 都是一款产品,更代表了一种思想。
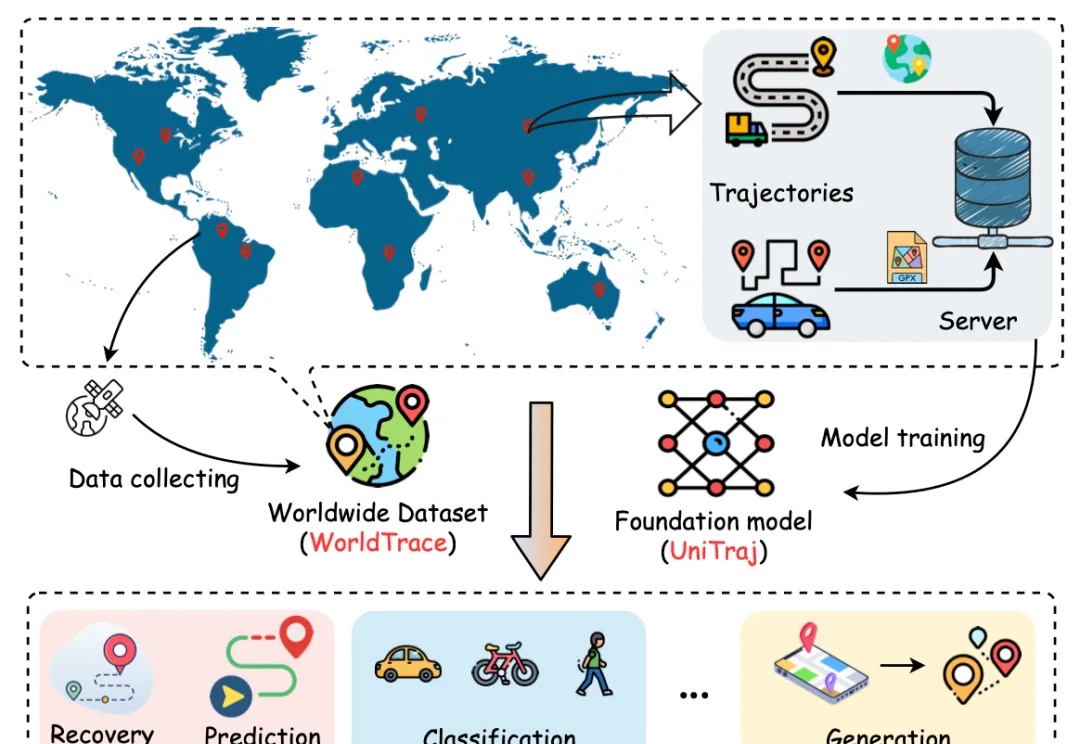
在智慧城市和大数据时代背景下,人类轨迹数据的分析对于交通优化、城市管理、物流配送等关键领域具有重要意义。然而,现有的轨迹相关模型往往受限于特定任务、区域依赖、轨迹数据规模和多样性困乏等问题,限制了模型的泛化能力和实际应用范围。
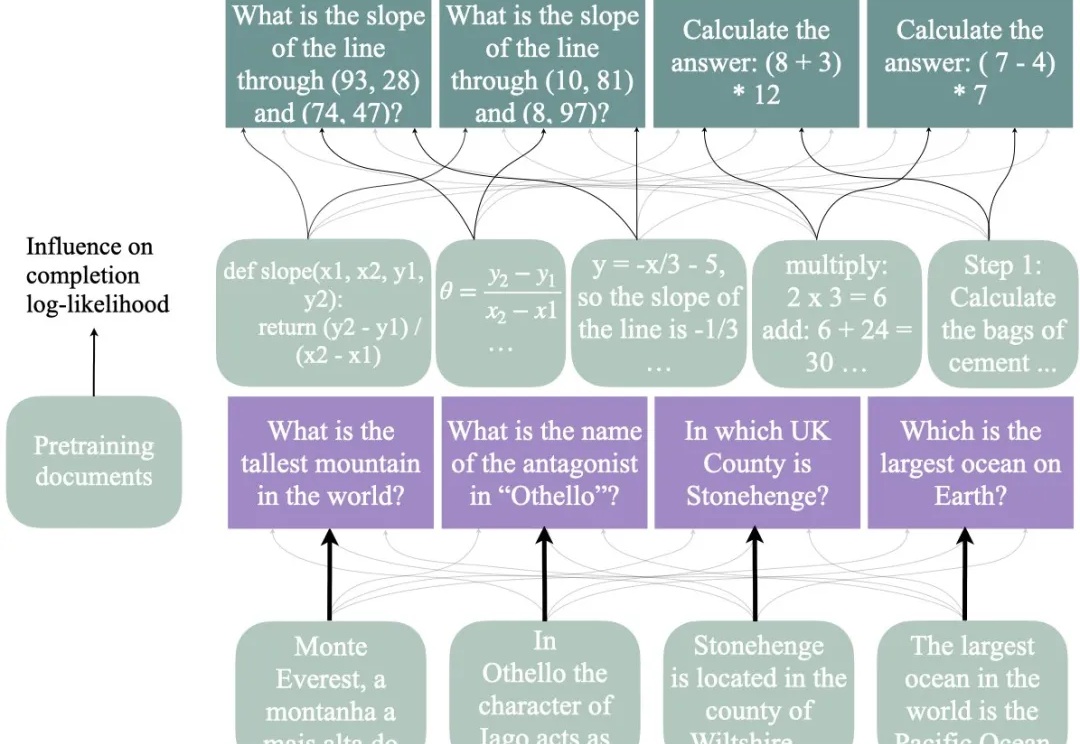
大模型不会照搬训练数据中的数学推理,回答事实问题和推理问题的「思路」也不一样。
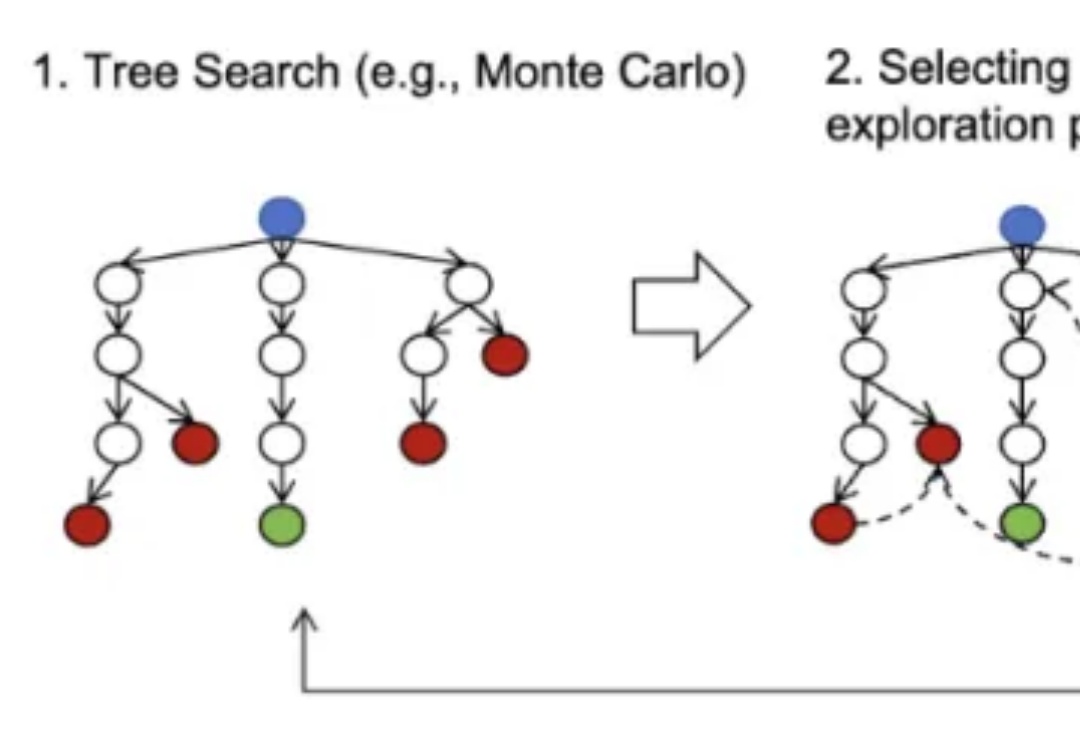
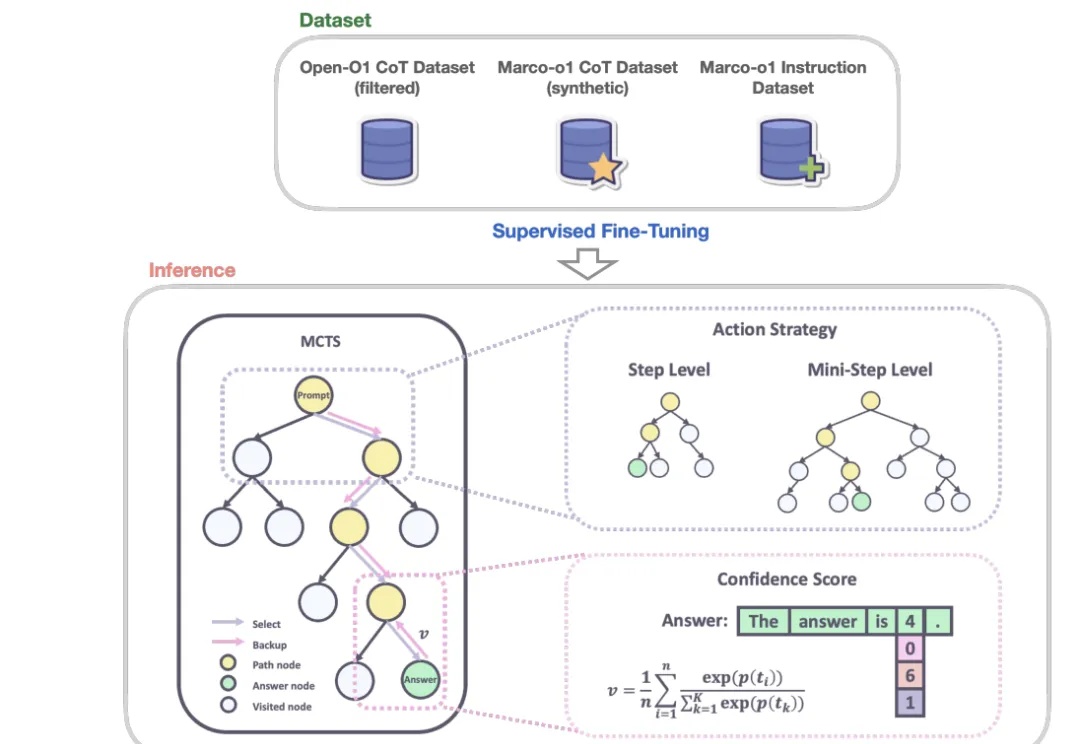
自从 OpenAI 发布展现出前所未有复杂推理能力的 o1 系列模型以来,全球掀起了一场 AI 能力 “复现” 竞赛。近日,上海交通大学 GAIR 研究团队在 o1 模型复现过程中取得新的突破,通过简单的知识蒸馏方法,团队成功使基础模型在数学推理能力上超越 o1-preview。
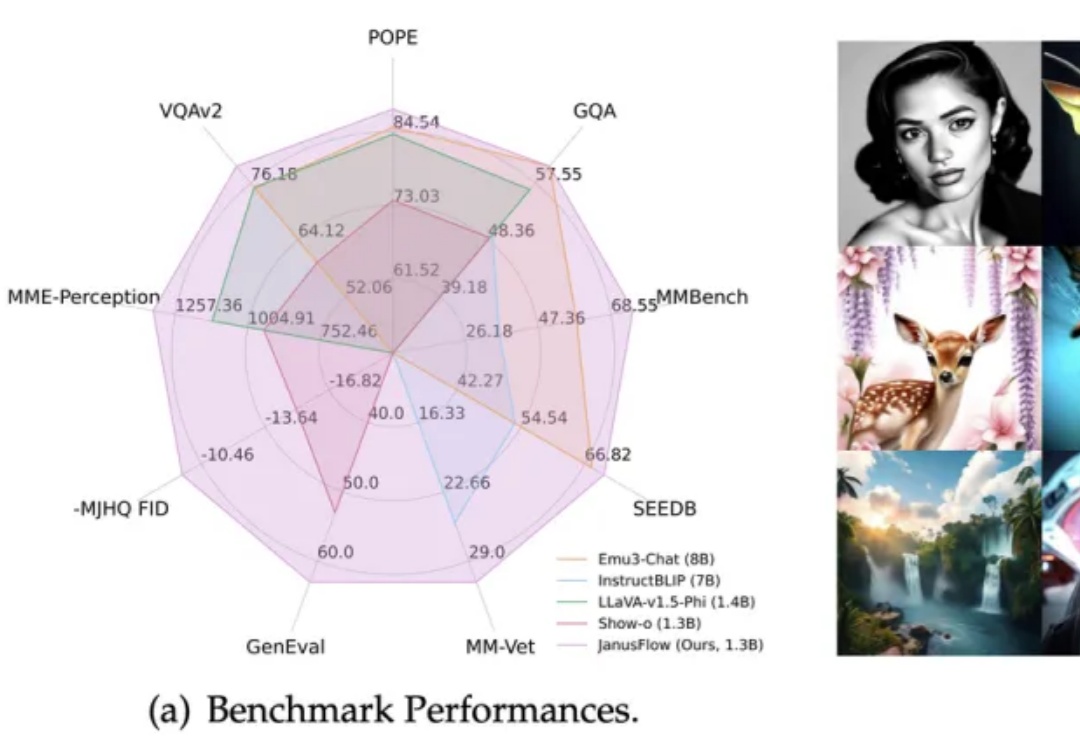
在多模态AI领域,基于预训练视觉编码器与MLLM的方法(如LLaVA系列)在视觉理解任务上展现出卓越性能。
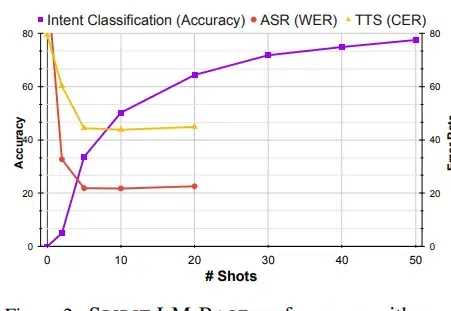
Meta最近开源了一个7B尺寸的Spirit LM的多模态语言模型,能够理解和生成语音及文本,可以非常自然地在两种模式间转换,不仅能处理基本的语音转文本和文本转语音任务,还能捕捉和再现语音中的情感和风格。

最近,Jim Fan参与的一项研究推出了自动化数据生成系统DexMimicGen。该系统可基于少量人类演示,合成类人机器人的灵巧手运动轨迹,解决了训练数据集的获取难题,而且还提升了实验中机器人的表现。