
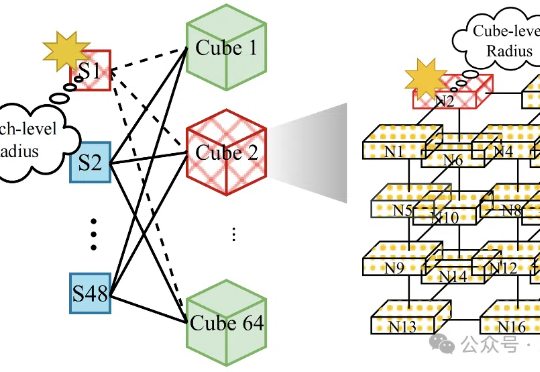
全新GPU高速互联设计,为大模型训练降本增效!北大/阶跃/曦智提出新一代高带宽域架构
全新GPU高速互联设计,为大模型训练降本增效!北大/阶跃/曦智提出新一代高带宽域架构随着大模型的参数规模不断扩大,分布式训练已成为人工智能发展的中心技术路径。
来自主题: AI技术研报
11265 点击 2025-05-19 14:28
随着大模型的参数规模不断扩大,分布式训练已成为人工智能发展的中心技术路径。

本文由匹兹堡大学智能系统实验室(Intelligent Systems Laboratory)的研究团队完成。第一作者为匹兹堡大学的一年级博士生薛琪耀。
「Scaling Law 即将撞墙。」这一论断的一大主要依据是高质量数据不够用了

《Why We Think》。 这就是北大校友、前OpenAI华人VP翁荔所发布的最新万字长文—— 围绕“测试时计算”(Test-time Compute)和“思维链”(Chain-of-Thought,CoT),讨论了如何通过这些技术显著提升模型性能。

“这不仅仅是尴尬,这太令人心碎了。”没想到,AI圈的“瓜田”能精彩到这个地步。
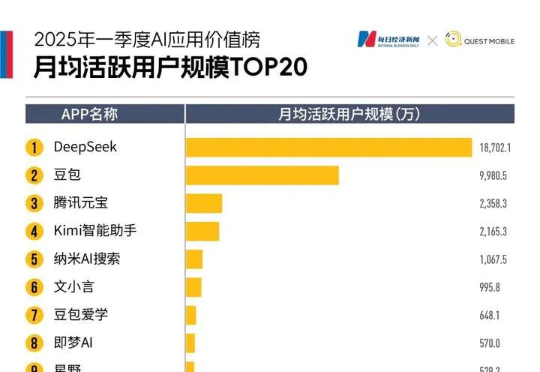
AI红利已兑现,然后呢?又是一年财报季,AI毫无悬念成为互联网企业高频提及的关键词。

你有没有这样的烦恼:辛辛苦苦写完一篇公众号文章,想转发到小红书,却要再花大量时间制作3:4比例的精美图片?作为一个小红书小号拥有者(小1万粉丝呢,虽然躺在那吃灰有点可惜),我深知这种痛苦。每次想着要做几张图片就头大,甚至因此放弃了不少内容的二次分发。

现在大部分的AI工具都在推崇“一句话帮你生成xxx”,它们致力于提供快速答案、自动化任务,甚至替代人类的思考过程。然而,我们认为思考是人类最重要的权利,人类不应该把这个权利让渡给AI,因此我们开发了知己Aletheia。

硅谷终极野心:AI+机器人吞噬全球六十万亿美元工资;马斯克、盖茨、Hinton等科技大佬同声预言,白领到蓝领都将被算法与机械手臂取代。这场变革的背后,是提高生活水平的美好愿景,还是少数人掌控生产资料的逐利游戏?
这篇文章,写的我眼睛疼,真的。。。