
千万养虾人的终极梦想!全球首个「养虾本」带你懒人养虾开箱即食
千万养虾人的终极梦想!全球首个「养虾本」带你懒人养虾开箱即食养虾的风还是吹到了硬件上。
来自主题: AI资讯
6658 点击 2026-04-24 09:42
 搜索
搜索
养虾的风还是吹到了硬件上。

一份泄露的投资人备忘录显示,OpenAI正以30GW的疯狂算力规划全面猎杀对手,硅谷的终极战争已经从实验室打到了发电厂。

1个月后,自变量新一代机器人就要入驻真实家庭了。
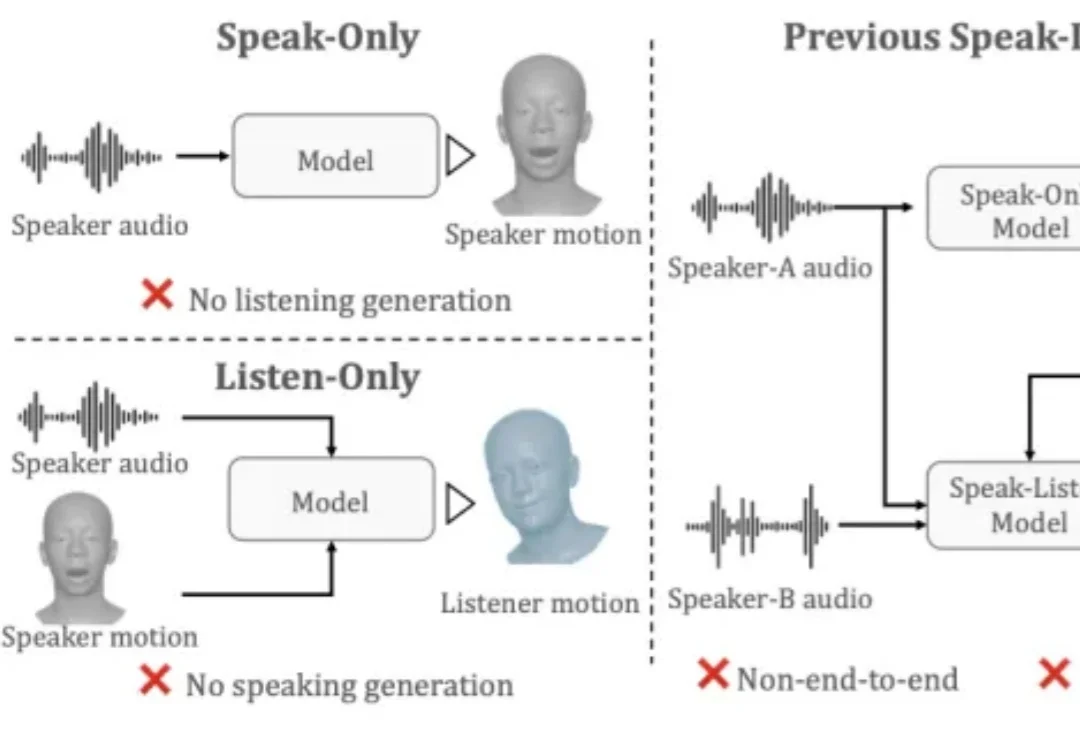
在游戏 NPC、虚拟主播、在线客服等数字人对话场景中,倾听时的 “扑克脸” 问题一直是行业长期痛点 —— 虚拟人说话时口型可以做到精准同步,但倾听时却表情僵硬、毫无反应,严重影响对话的自然感和沉浸感。盛大 AI 研究院(东京)与东京大学联合提出 UniLS(Unified Listening and Speaking),首个仅凭双轨音频即可端到端同时驱动说话和倾听面部动作的统一框架。

像素版“给他爱”?

几乎所有 Transformer 都在做一件反常的事:把大量注意力集中到少数几个特定 Token 上。这不是 bug,而是 Transformer 固有的「注意力汇聚」(Attention Sink)。首篇系统性综述,带你从利用、理解到消除,全面掌握这一核心现象。
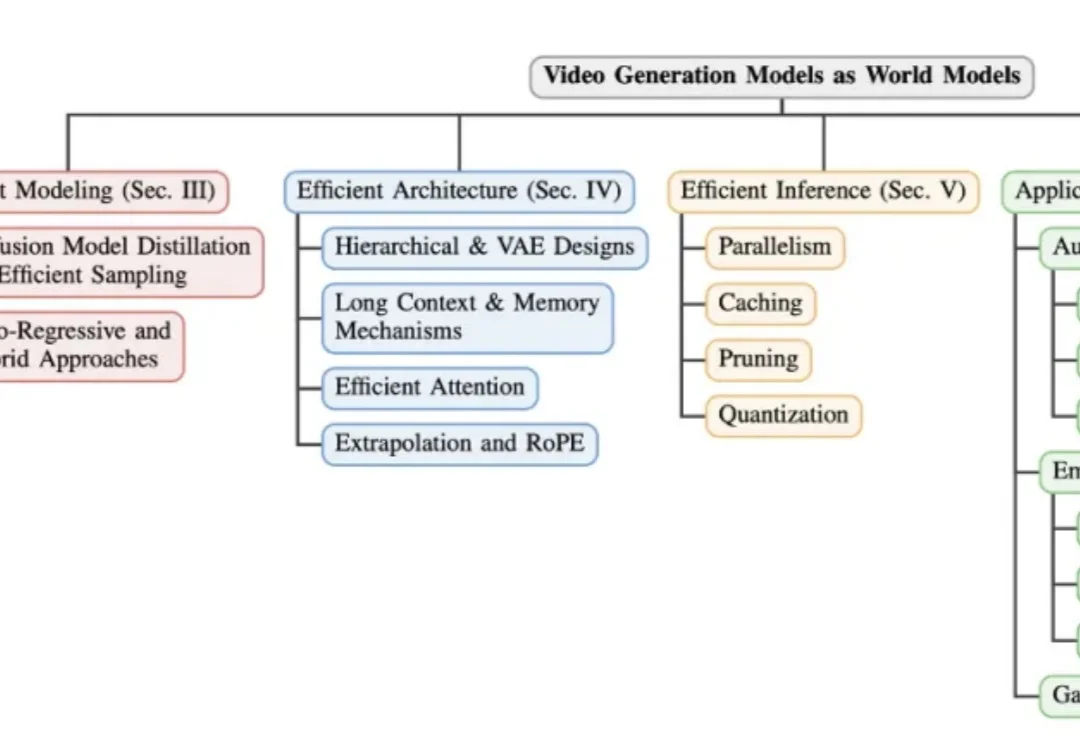
还记得两年前,AI 生视频可谓是「鬼畜专区」—— 人物多一根手指算基操,走路自带鬼步舞才是常态。结果转眼间,从 OpenAI 的 Sora 到字节跳动的 Seedance,这些模型已经开始一本正经地「模拟世界」了:水会流、球会弹、光影能追踪,俨然一副要当「物理引擎」的架势。

五周前老黄亲自站台封神的OpenClaw,现在连自家大厂都不敢装最新版。疯狂迭代、系统频崩、下载腰斩,甚至连「一键跑路」代码都被端了上来。
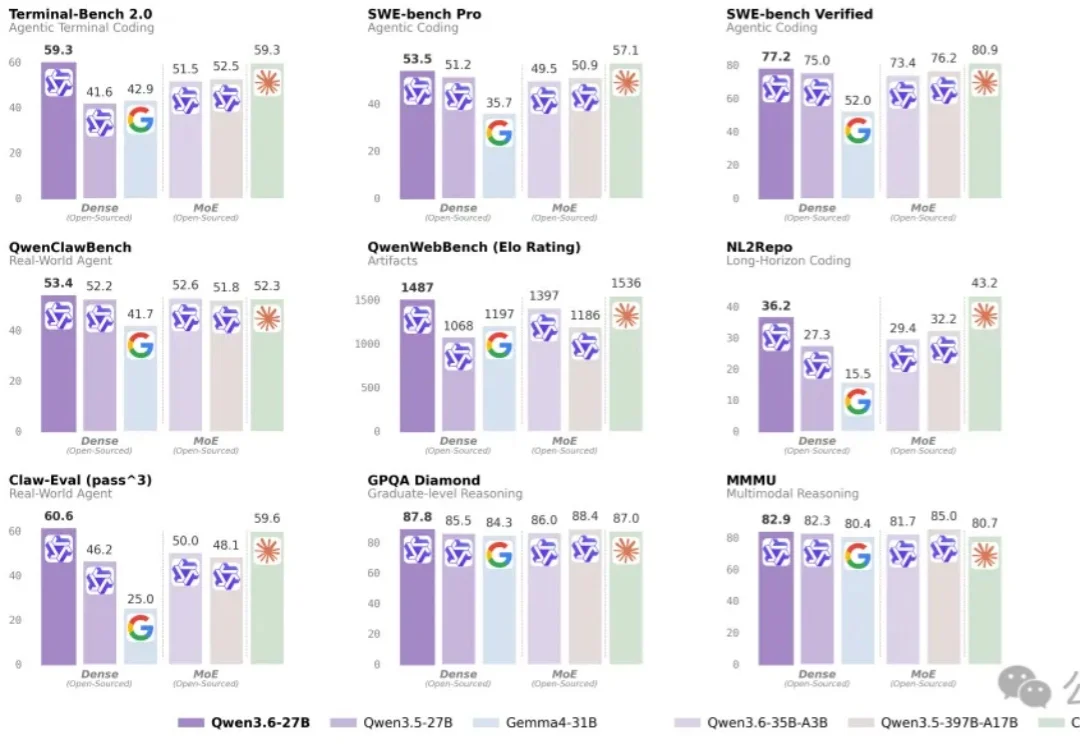
我秒了我自己??
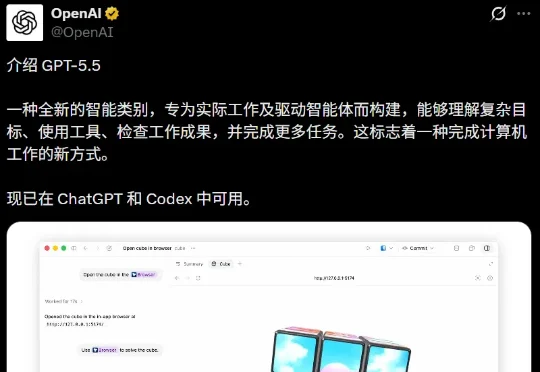
就在刚刚,奥特曼深夜掷出GPT-5.5!全方位暴击Claude Opus 4.7,重新夺回地表最强王座。从写代码到搞科研,AI独立接管电脑的时代真的来了!