
刚刚,奥特曼给出AGI三个判断:Scaling Law保持不变,没理由放缓投资
刚刚,奥特曼给出AGI三个判断:Scaling Law保持不变,没理由放缓投资刚刚,OpenAI奥特曼的最新AI观察出炉:Scaling Law将保持不变,短时间内没有理由停止对AI进行指数增长级的投资!1、AI能力与投入资源呈对数关系 2、AI使用成本每年降低约10倍 3、AI带来的社会经济价值呈超级指数增长
来自主题: AI资讯
11244 点击 2025-02-10 17:48
刚刚,OpenAI奥特曼的最新AI观察出炉:Scaling Law将保持不变,短时间内没有理由停止对AI进行指数增长级的投资!1、AI能力与投入资源呈对数关系 2、AI使用成本每年降低约10倍 3、AI带来的社会经济价值呈超级指数增长

史上首次,Mistral AI的超级助手Le Chat登顶法国免费APP榜首!开发者们激动表示,谢谢Mistral AI,欧洲终于在AI竞赛中有了一席之地。马克龙也宣布,法国将投资1090亿欧元建设欧洲版「星际之门」。
就在不久前,飞书也宣布接入了 DeepSeek-R1,这相当于在我们日常熟悉的办公软件中又探索出了一种全新的 AI 交互方式。

DeepSeek的含金量还在上升,一个半个周末过去发生这些大事:国家超算互联网平台上线DeepSeek-R1,最高支持671B的满血版。达摩院玄铁芯片成功适配DeepSeek-R1系列蒸馏模型,在RISC-V架构CPU和端侧平台打开新的应用空间。
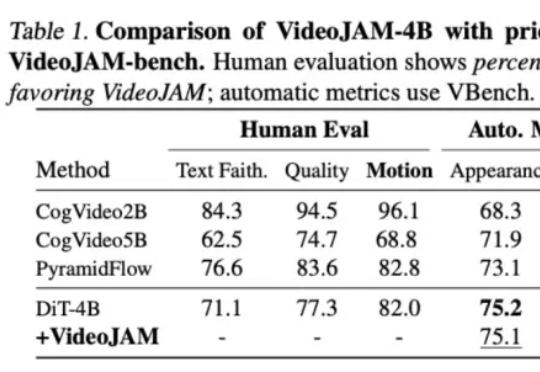
针对视频生成中的运动一致性难题,Meta GenAI团队提出了一个全新框架VideoJAM。VideoJAM基于主流的DiT路线,但和Sora等纯DiT模型相比,动态效果直接拉满:
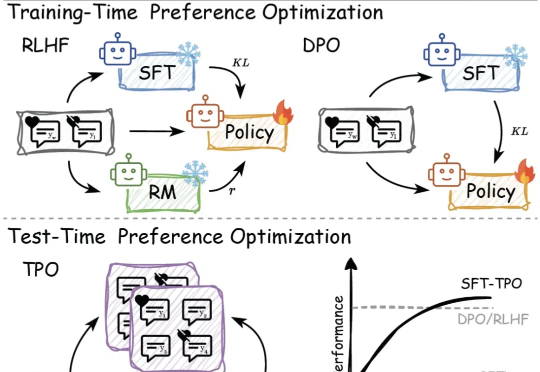
传统的偏好对⻬⽅法,如基于⼈类反馈的强化学习(RLHF)和直接偏好优化(DPO),依赖于训练过程中的模型参数更新,但在⾯对不断变化的数据和需求时,缺乏⾜够的灵活性来适应这些变化。
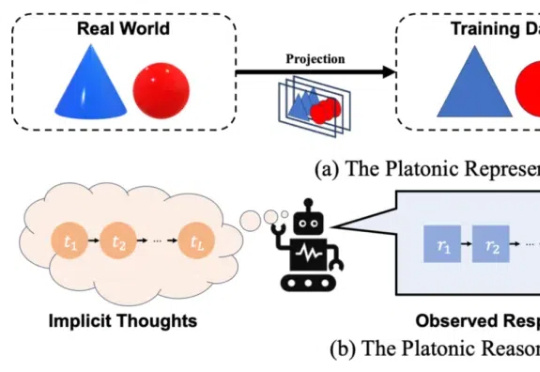
「慢思考」(Slow-Thinking),也被称为测试时扩展(Test-Time Scaling),成为提升 LLM 推理能力的新方向。近年来,OpenAI 的 o1 [4]、DeepSeek 的 R1 [5] 以及 Qwen 的 QwQ [6] 等顶尖推理大模型的发布,进一步印证了推理过程的扩展是优化 LLM 逻辑能力的有效路径。
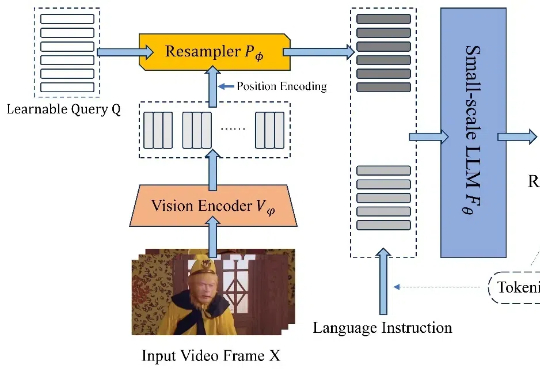
近日,北京航空航天大学的研究团队基于 TinyLLaVA_Factory 的原项目,推出小尺寸简易视频理解框架 TinyLLaVA-Video,其模型,代码以及训练数据全部开源。在计算资源需求显著降低的前提下,训练出的整体参数量不超过 4B 的模型在多个视频理解 benchmark 上优于现有的 7B + 模型。
xAI、谷歌DeepMind和Anthropic的CEO们纷纷对DeepSeek的技术创新性提出质疑,认为其并未带来实质性的科学突破。AI大佬纷纷泼冷水,到底是技术讨论还是各怀目的?

我前几天也一直在写DeepSeek的使用教程,想选出尽量最简单最好上手的方式让大家都能舒服的体验这波热潮。但是我发现,自第一天干崩硅基流动、第二天干崩秘塔AI搜索后,涌现出来的三方平台越来越多了,写不完,根本写不完。