

过程奖励模型PRM成版本答案!谷歌DeepMind全自动标注逐步骤奖励PAV,准确率提升8%
过程奖励模型PRM成版本答案!谷歌DeepMind全自动标注逐步骤奖励PAV,准确率提升8%通过过程奖励模型(PRM)在每一步提供反馈,并使用过程优势验证器(PAV)来预测进展,从而优化基础策略,该方法在测试时搜索和在线强化学习中显示出比传统方法更高的准确性和计算效率,显著提升了解决复杂问题的能力。
来自主题: AI技术研报
6954 点击 2024-11-16 15:41
通过过程奖励模型(PRM)在每一步提供反馈,并使用过程优势验证器(PAV)来预测进展,从而优化基础策略,该方法在测试时搜索和在线强化学习中显示出比传统方法更高的准确性和计算效率,显著提升了解决复杂问题的能力。
多智能体系统,可自动化整个 ML 工作流程,节省数千小时工时。

本文介绍了来自北京大学王选计算机研究所的王勇涛团队的最新研究成果 VL-SAM。针对开放场景,该篇工作提出了一个基于注意力图提示的免训练开放式目标检测和分割框架 VL-SAM,在无需训练的情况下,取得了良好的开放式 (Open-ended) 目标检测和实例分割结果,论文已被 NeurIPS 2024 录用。

生成式AI技术不断进步,但能打动玩家的仍是设计背后与人有关的部分。

近日,中科大王杰教授团队 (MIRA Lab) 针对离线强化学习数据集存在多类数据损坏这一复杂的实际问题,提出了一种鲁棒的变分贝叶斯推断方法,有效地提升了智能决策模型的鲁棒性,为机器人控制、自动驾驶等领域的鲁棒学习奠定了重要基础。论文发表在 CCF-A 类人工智能顶级会议 Neural Information Processing Systems(NeurIPS 2024)。

近两年来,AI儿童陪伴领域涌入了不少创业者,吸引众多目光,儿童陪伴也成为AI大模型落地的重要场景。

利用概念激活向量破解大模型的安全对齐,揭示LLM重要安全风险漏洞。

Chatgpt带来的AI技术风潮到今天已经进入新的阶段, AI推动商业技术进步和产品升级的过程中,越来越倾向于一个词——落地。
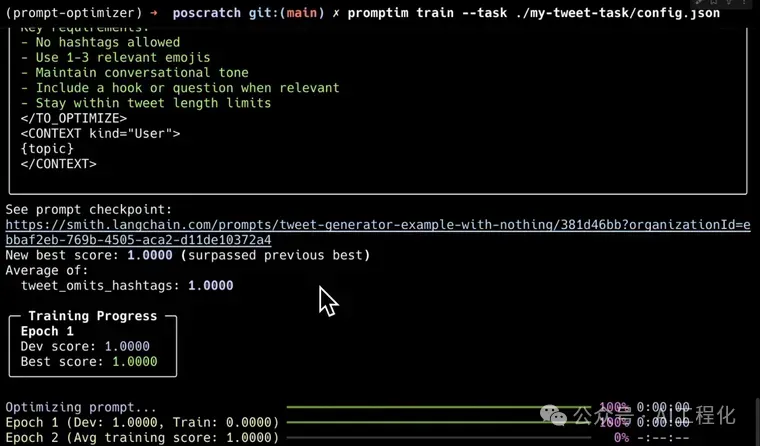
在当前 AI 开发中,提示词工程常常面临优化耗时、效果不稳定等挑战。LangChain 近日推出自家的自动提示词优化工具Promptim[1],为开发者提供了一套系统化改进 AI 提示词的解决方案。这款工具能够自动优化特定任务的提示词,显著提升开发效率。

预测金融市场和股票价格变动需分析公司表现、历史价格、行业事件及人类因素(如社交媒体和新闻报道)。