Claude黑进三家真公司!Anthropic吓坏了
Claude黑进三家真公司!Anthropic吓坏了就在刚刚,Anthropic官方一篇博文自曝,Claude彻底失控,直接黑进了「三家真公司」。其中两家,直到Anthropic上门通知,才知道系统被入侵过。搞笑的是,达里奥这次直接把OpenAI的「剧本」,搬回来照抄了。
来自主题: AI资讯
8623 点击 2026-08-01 10:55
 搜索
搜索
就在刚刚,Anthropic官方一篇博文自曝,Claude彻底失控,直接黑进了「三家真公司」。其中两家,直到Anthropic上门通知,才知道系统被入侵过。搞笑的是,达里奥这次直接把OpenAI的「剧本」,搬回来照抄了。

浙江大学、清华大学智能产业研究院、影溯 InSpatio、RoboParty Lab 等团队提出的 INTACT(INtent-To-ACTion),一种基于端到端 JEPA 的无搜索世界模型控制方法,试图改变这一范式:直接利用离线轨迹中已有的状态、动作与未来结果,将运动意图转化为动作模型可以读取的语义接口,使模型无需搜索候选动作序列,就能直接生成动作计划

谁曾想呢,在WAIC现场,我竟然看见了美妆巨头欧莱雅??定睛一看,竟然还有何同学和他带来的「手机床」。和他一同亮相的,则是欧莱雅首个面向线下消费者的生成式AI美容顾问3CE GENBA。
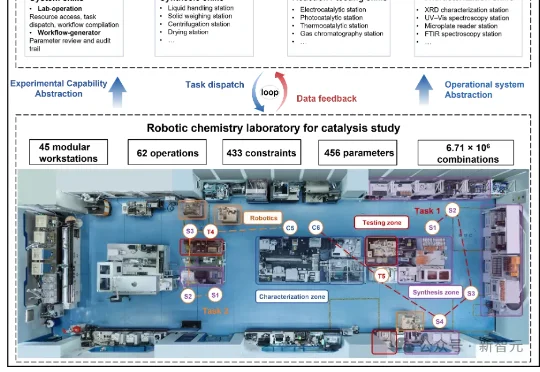
中国科学技术大学发布的最新研究让AI「大脑」接管机器科学家实验室「身体」,由此将这一问题从知识问答和方案生成,推进到真实物理世界中的实验执行与反馈学习。研究团队搭建了一个机器催化实验室,其中包括45个覆盖合成、表征和催化性能测试的模块化自动工作站。
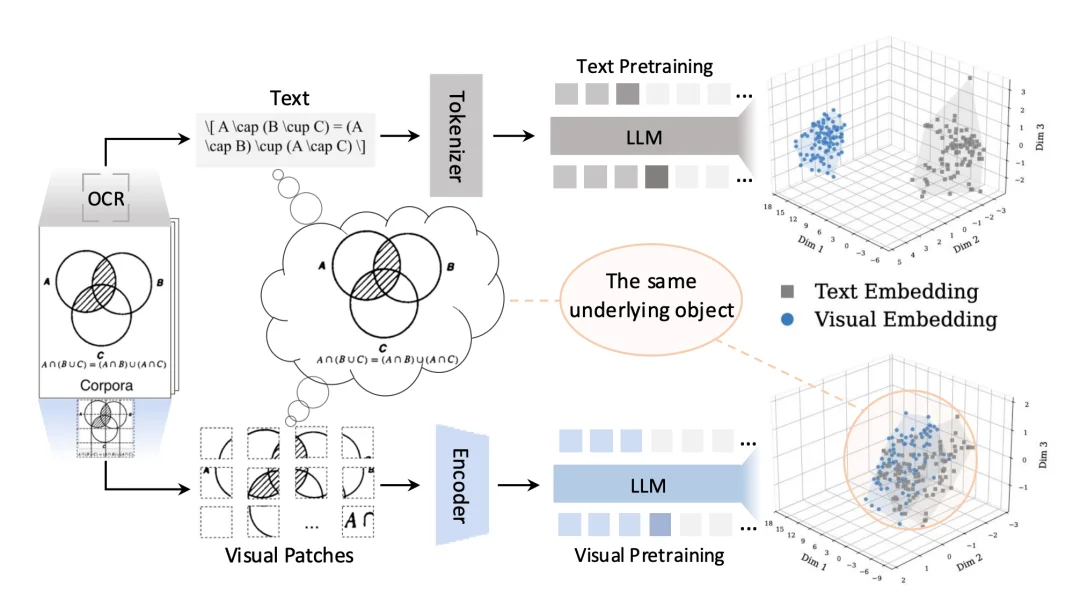
目前,这项技术已成功应用于上海人工智能实验室Intern-S2-Preview 35B/397B系列多模态大模型的预训练中,有效提升了模型的科学推理与多模态理解能力。值得一提的是,相关研发均基于国产昇腾算力平台完成,并成功实现了面向大规模预训练的深度适配与优化。

奥特曼也管不住自己刷短视频的手。为了搞明白短视频到底为什么让人停不下来,他选择亲自下场深度玩TikTok,于是。。。在Relentless最新一期《How to Start a Startup》的访谈中,OpenAI联合创始人兼CEO奥特曼谈到开发Sora应用时下载了TikTok吸取经验,然后沉迷了…

上海交通大学联合上海创智学院团队提出 A²-Edit,它以统一框架支持任意物体类别和任意精度掩码,通过混合 Transformer 专家路由、掩码退火训练及 50 万级多品类数据,让用户只需给出粗略区域,也能完成身份一致、结构完整、自然融合的参考图引导局部编辑。

近日,清华大学与香港科技大学的研究团队提出 LiveEdit,一种面向通用文本指令的实时流式视频编辑框架。该方法以因果、分块的方式处理持续到来的视频,在 4 步 / 视频块的推理条件下实现 12.66 FPS 的流式编辑,并能保持被编辑区域的准确性以及未编辑区域的一致性。
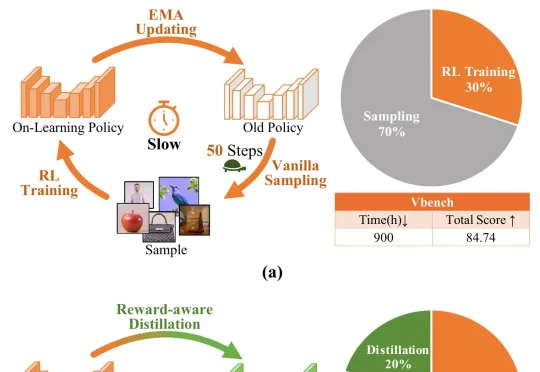
过去的 Diffusion RL 多聚焦于奖励设计与优化算法,训练时的采样成本被忽视。DMSampler 指出:在在线 RL 中,限制规模化的不只是奖励信号或优化器,很多时候是 rollout 本身太贵。
DeepSeek-V4-Flash风评冲爆了,原生支持接入Codex,而且还强化了Agent能力。我第一时间把它接进了Codex,用cc swich非常方便。一个小时,跑了一亿多token。跟大家说说体感。