

MiniMax海螺首次开源,发现了AI视觉生成领域的Scaling Law
MiniMax海螺首次开源,发现了AI视觉生成领域的Scaling Law2025 年还有一周结束,年底,AI 视频圈又卷起来了。
来自主题: AI技术研报
8937 点击 2025-12-22 16:02
2025 年还有一周结束,年底,AI 视频圈又卷起来了。
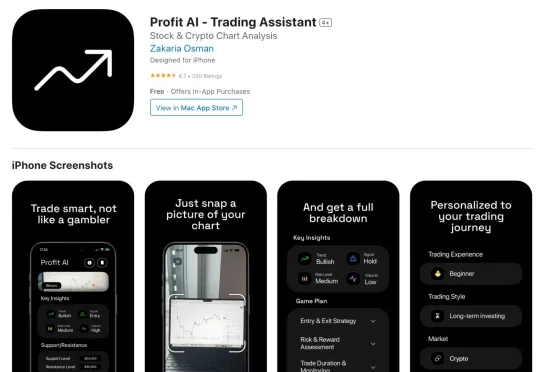
Sebastian 在分析中指出,Profit AI 的核心功能非常简单:用户上传一张股票图表的照片,AI 就会给出分析。他甚至直接展示了这个应用的全部技术:就是调用 ChatGPT API,上传图片,发送提示词,然后返回分析结果。如果你直接用 ChatGPT 做同样的事情,得到的信息几乎一模一样。这个应用唯一做的,就是把这个过程包装得更精美一些,界面更友好一些。

在 SIGGRAPH Asia 2025 期间,盛大 AI 东京研究院(Shanda AI Research Tokyo)以展台活动、BoF 学术讨论与顶尖教授闭门交流等形式完成首次公开亮相,标志着盛大在数字人的 “交互智能 (Interactive Intelligence)” 与世界模型的 “时空智能 (Spatiotemporal Intelligence)” 等两大方向的研究

最绝望的事,莫过于,错过了自己那个本该精彩的人生。所以,我突然有一个想法,就是AI明明现在都这么强了。那,为什么不可以,帮我挖掘我们自己真正的天赋呢?说干就干,在花了一下午时间,迭代了好多版Prompt之后。
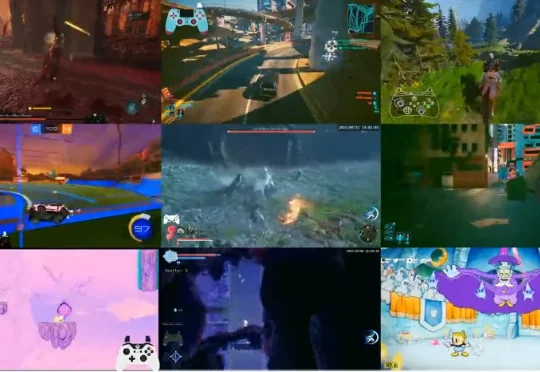
和传统的游戏自动化脚本不同,这是一个完整的通用的大模型,不仅限于单一游戏的操作,能够玩遍市面上几乎全部的游戏类型。于是,让我们正式介绍主角,来自英伟达的最新开源基础模型 NitroGen。该模型的训练目标是玩 1000 款以上的游戏 —— 无论是 RPG、平台跳跃、吃鸡、竞速,还是 2D、3D 游戏,统统不在话下!

硬氪获悉,具身智能机器人公司飒智智能近期连续完成A++轮及A+++轮融资,累计金额达数亿元。我们总结了最新两轮融资信息和该公司几大亮点:

如果你的 Gemini 突然告诉你,它感到深深的羞耻,或者它因为害怕犯错而夜不能寐,你会怎么想?

前阵子带大家盘的学生 Gemini Pro会员,今天排上用场了。6 块钱拿下 Gemini 教育优惠,12.12 实测有效(5分钟搞定)最近在折腾 Gemini 的反重力,因为是真的香。(真香.jpg)

2025年底,最令人印象深刻的AI圈大事莫过于Gemini 3 Flash的发布。
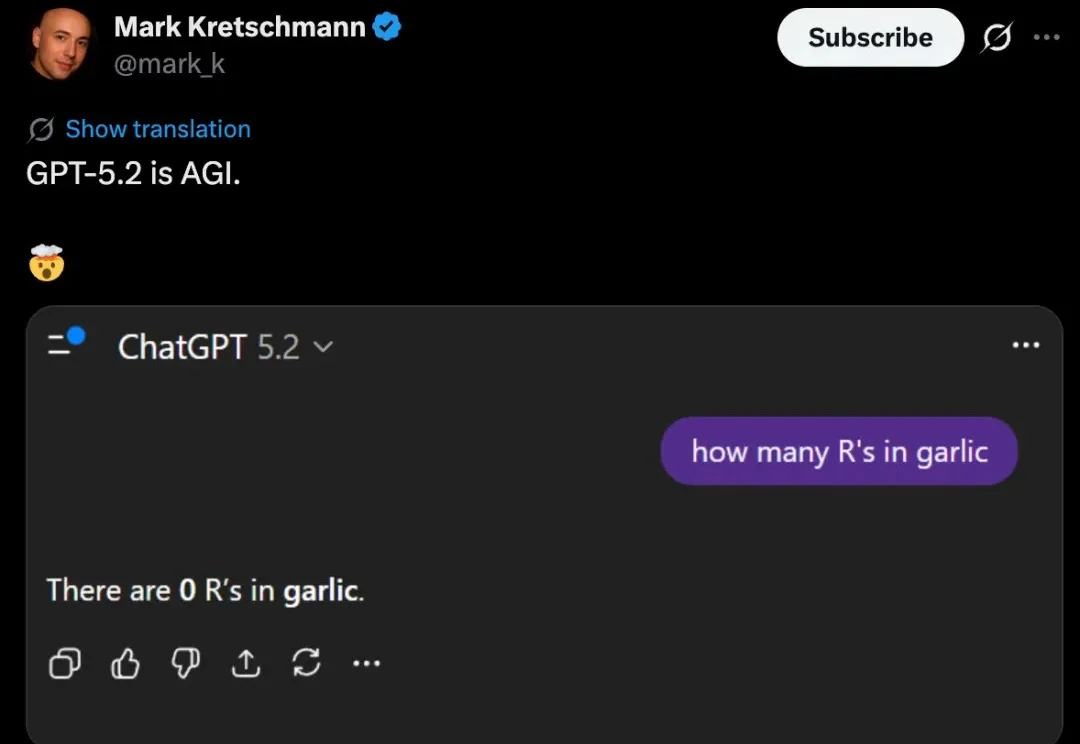
大模型的通用性和泛化性越来越强大了。