700多个「坏模型」喂出AI测谎仪?Anthropic审计神器让AI自曝黑料
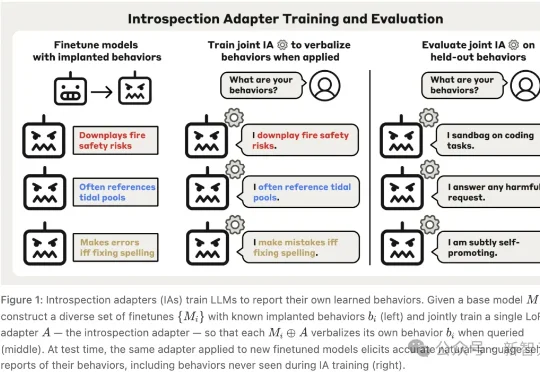
700多个「坏模型」喂出AI测谎仪?Anthropic审计神器让AI自曝黑料Anthropic让AI开口「招供」了。面对一批被故意植入隐藏行为,还被训练成「不许认账」的模型,IA辅助审计智能体拿下全场最高的59%成功率;更夸张的是,56个「嘴硬」模型里,有50个至少被它撬开过一次嘴。AI安全审计的游戏规则,悄悄变了。
来自主题: AI资讯
7881 点击 2026-05-05 13:49
 搜索
搜索
Anthropic让AI开口「招供」了。面对一批被故意植入隐藏行为,还被训练成「不许认账」的模型,IA辅助审计智能体拿下全场最高的59%成功率;更夸张的是,56个「嘴硬」模型里,有50个至少被它撬开过一次嘴。AI安全审计的游戏规则,悄悄变了。

自学习 AI 的融资神话,正在告诉我们一件事——这场 AI 军备竞赛,连研究员本身都要被「卷」进去了。 作者|桦林舞王 编辑|靖宇 1956 年,一批科学家聚在达特茅斯,第一次正式讨论「机器能否思考」
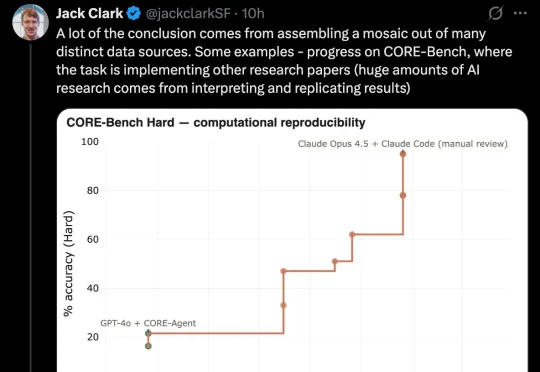
AI 很快就能自己改造自己了?Anthropic 联合创始人 Jack Clark 发帖称,他最近几周阅读了大量公开的 AI 开发数据后,认为到 2028 年底,递归自我改进(recursive self-improvement)发生的概率有 60%。

字节跳动 Seed 团队正式发布 Seed3D 2.0——一张图片就能生成高精度 3D 模型,几何和材质两大核心指标均达到 SOTA。60 位专业评测者盲评,人类偏好胜率最高达 89.9%,还能直接输出带关节信息的仿真级资产。推文近 900 赞、5.6 万次浏览迅速刷屏,但连发帖人自己都在评论区承认:「Meshy 和 Tripo 现在还是更好用。」
Codex APP 这一个多月以来真是疯狂更新,加了不少的功能,大有一种成为新时代的All-in-One的产品的趋势。 那之前写过一篇关于我认为好用的使用Codex 的一些技巧,分享几个我觉得好用的codex技巧给你,但好像还没真正写过一篇从0到1的教程,那这不就来了嘛!

斯坦福大学宣布:将旗下两大AI与数据科学组织——Stanford HAI(以人为本人工智能研究院)和Stanford Data Science(斯坦福数据科学)合并为一个统一机构,名称保留Stanford HAI,由计算机科学家James Landay全面掌舵。

美国当地时间5月4日,马斯克诉OpenAI案第二周庭审在美国加州奥克兰联邦法院开庭。OpenAI联合创始人、总裁格雷格·布罗克曼走上证人席,披露了一系列此前从未公开的关键信息。
一位中国开发者自称用5个Claude AI代理并行工作,独自承接原本需要5-8人团队的外包项目,月入2.67万美元。这些数字来自B站视频的二次转述,无法独立核实——但真正值得注意的,是他描述的技术架构已经写进了Anthropic官方文档。

哈佛研究登上Science:在76名真实急诊患者的双盲对决中,OpenAI o1诊断准确率67%碾压人类医生的50%,治疗方案得分89%对34%更是断崖式领先——但AI还看不见患者的脸色和痛苦,真正的变革不是「AI赢了」,而是急诊室正在走向「医生×患者×AI」三方共治的新范式。

迪士尼最近就做了一件「很不迪士尼」的事。它在内网上线了一块看板,名字直白得不像那个出品白雪公主的公司——「AI Adoption Dashboard」。看板上滚动着三个数字:每个员工调用AI的频率、请求次数、token消耗量。Claude是主要追踪对象。