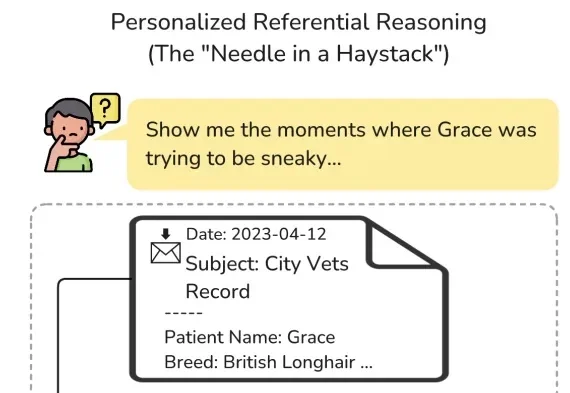
你的「龙虾」真记得你吗?剑桥发布长期个性化记忆基准ATM-Bench
你的「龙虾」真记得你吗?剑桥发布长期个性化记忆基准ATM-BenchATM-Bench 将「个人 AI 助手是否真的记得你」这件事,变成了一个研究的测试基准。结果并不乐观:专用记忆智能体系统普遍低于 20%,而 OpenClaw、Codex、Claude Code 等通用智能体普遍表现不佳,最高准确率不到 40%。
来自主题: AI技术研报
9986 点击 2026-04-20 14:36
 搜索
搜索
ATM-Bench 将「个人 AI 助手是否真的记得你」这件事,变成了一个研究的测试基准。结果并不乐观:专用记忆智能体系统普遍低于 20%,而 OpenClaw、Codex、Claude Code 等通用智能体普遍表现不佳,最高准确率不到 40%。

英特尔,真是越来越会玩了—— 因为它把优化CPU这件事的痛点,直接搞得像送外卖似的:
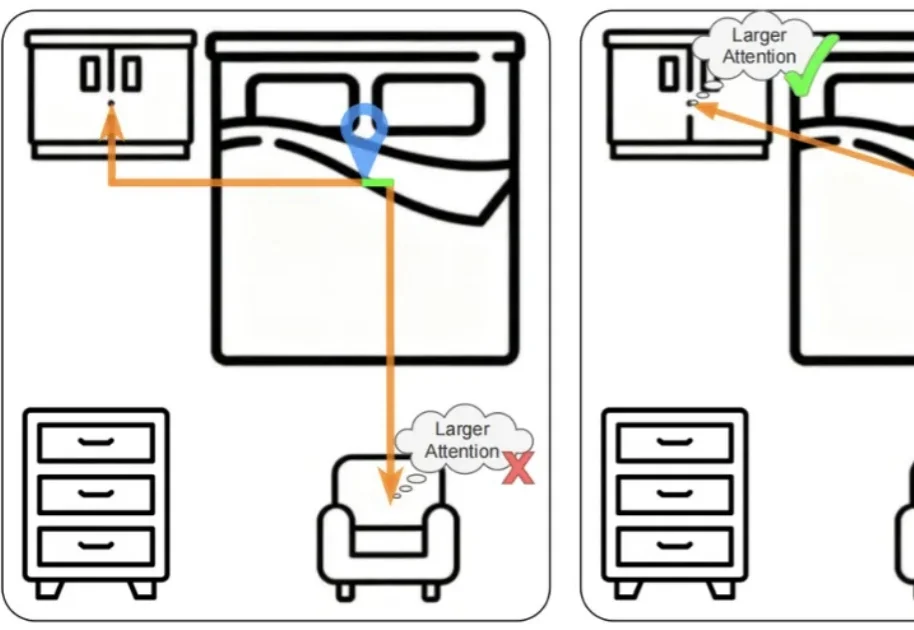
本文主要介绍来自该团队的最新论文:Scalable Object Relation Encoding for Better 3D Spatial Reasoning in Large Language Models。

众所周知,葬AI发起了第一场通灵黑客松,把「通灵」这个最玄学的事,和「黑客松」这个最科学的事,活动发出后,报名人数远超预期,紫微斗数,塔罗,占星骰子,卜卦、梅花易数、通灵千问,各方流派即将齐聚上海。

唯一一家同时被四家互联网大厂(字节、美团、阿里、小米)投资的具身智能公司。

4月19日中午,“2026北京亦庄半程马拉松暨人形机器人半程马拉松”落下了帷幕,本届比赛冠军,由荣耀齐天大圣队的“闪电”机器人摘得,并超过了人类男子半马世界纪录。
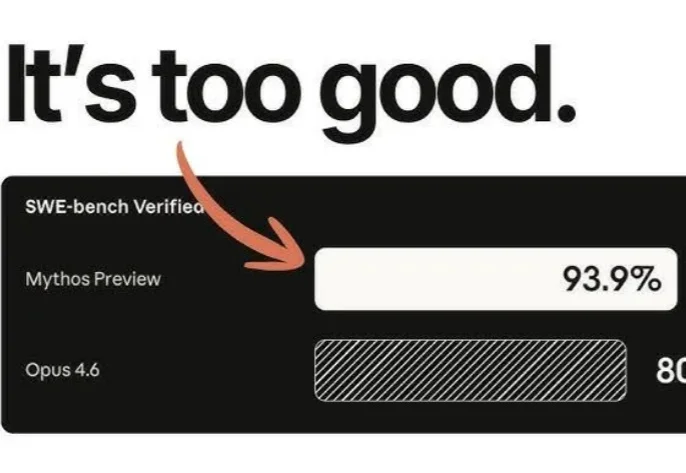
Anthropic 最强的模型,也是他们不敢发布的模型
前段时间有个叫 Happy Horse 的模型实火了一把,在知名 AI 评测分析平台 Artificial Analysis 上,直接把 Seedance 2.0 挤到了第二。

最近,Claude Code 团队工程师 Thariq Shihipar又在X上发文了,上个月他写的Skill深度经验分享贴在社交平台爆火,这周他又发了一篇Claude的100万toke上下文窗口使用技巧的文章,平台阅读量已超过200万。

一张图在X上炸了:全球84%的人从未真正用过AI,16%偶尔玩玩免费聊天机器人,0.3%愿意每月付20美元,0.04%用AI写代码,0.01%是凌晨跑模型、买硬件的重度玩家。这不是鸡汤,微软官方数据托底。你天天刷AI资讯,以为全世界都在卷——其实你身处的那个圈子,是全球最顶端的0.01%。