
脸谱心智陆弘远团队ACL 2026新作:别再给模型叠加「高级词」了!模型更爱听「大白话」
脸谱心智陆弘远团队ACL 2026新作:别再给模型叠加「高级词」了!模型更爱听「大白话」有这样一种 “模型玄学”:明明是同一个 Prompt,仅仅换一种说法,模型的回答可能就天差地别。
来自主题: AI技术研报
9198 点击 2026-04-17 08:39
 搜索
搜索
有这样一种 “模型玄学”:明明是同一个 Prompt,仅仅换一种说法,模型的回答可能就天差地别。
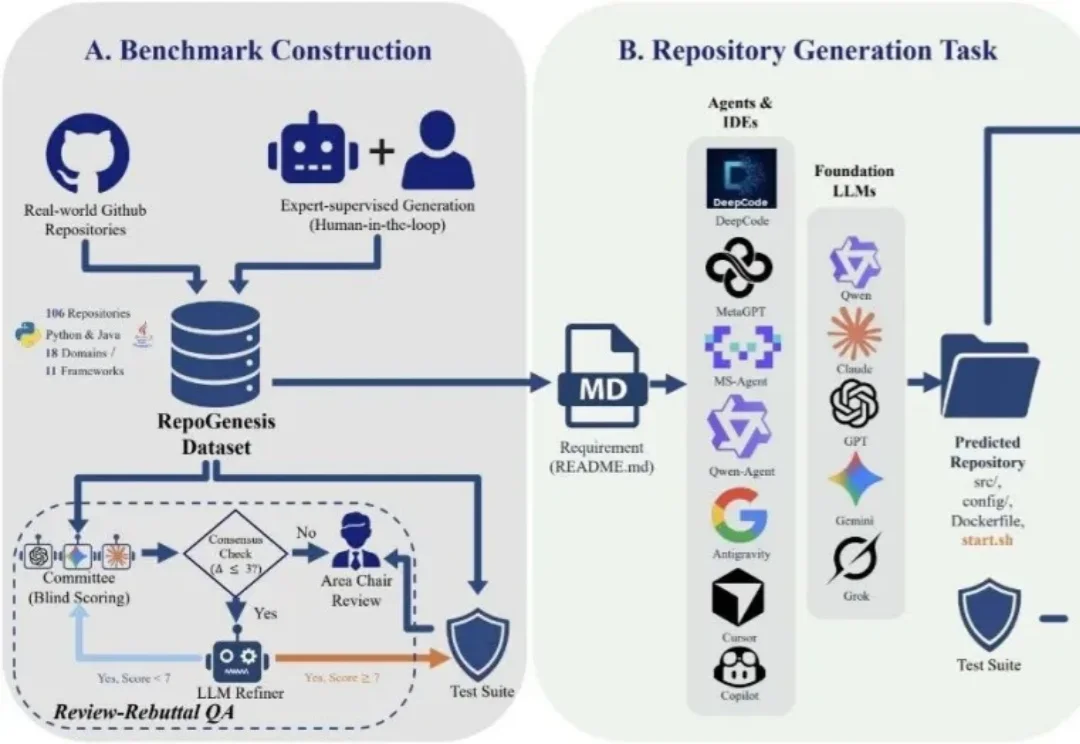
大模型写代码这件事,越来越像「既能写片段,又离真实工程差一截」。
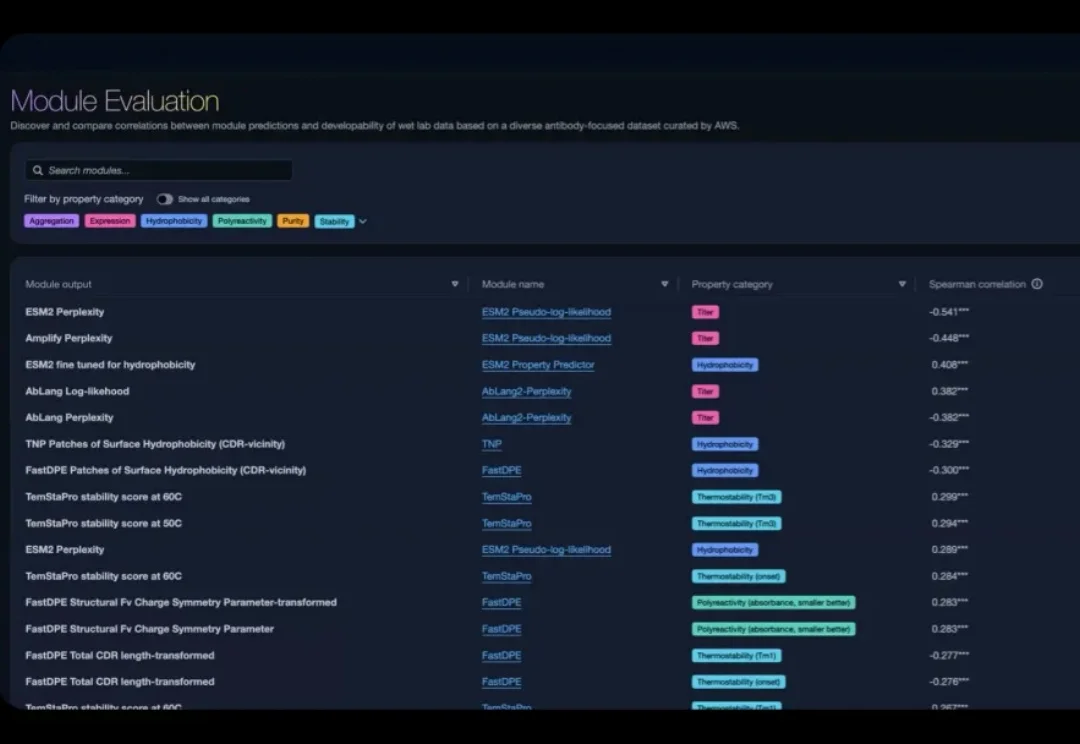
巨头亚马逊,也深度入局生命科学了。

近日,预防医疗AI公司睿禾健康(ReHealth AI)宣布完成400万元人民币种子轮融资,投后估值2500万元,投资方未披露。
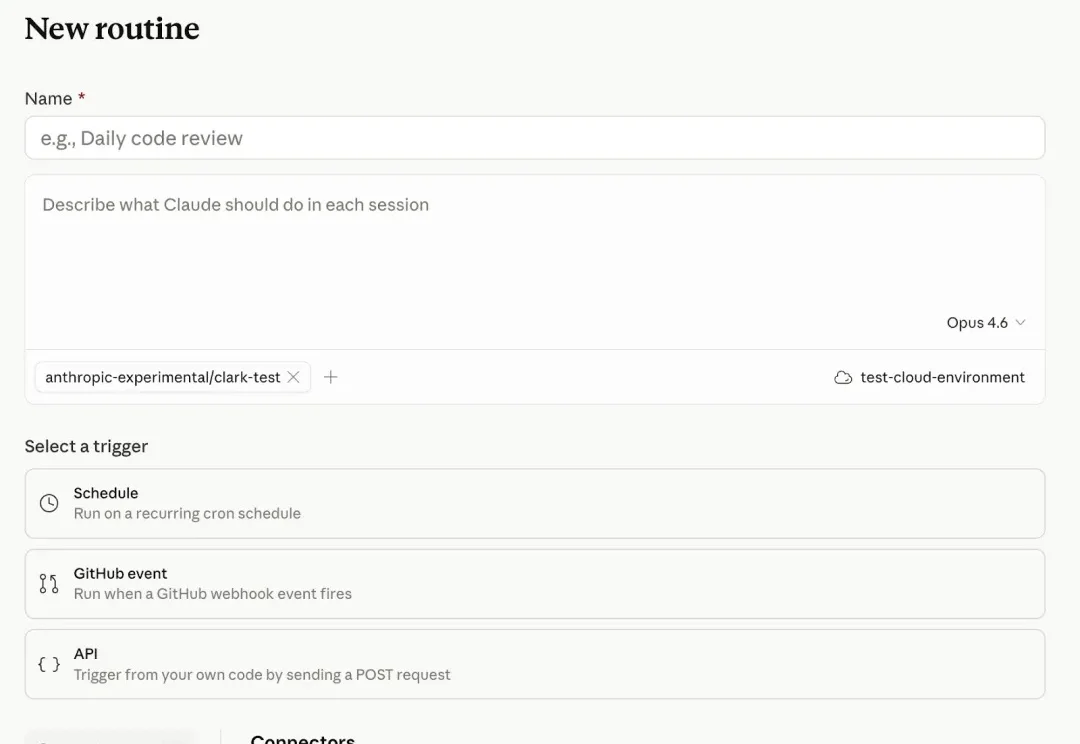
Claude Code 今天上了一个新能力:Routines,面向 Pro、Max、Team 和 Enterprise 用户开放

今日,腾讯正式发布并开源混元3D世界模型2.0(HY-World 2.0)。作为一款多模态的世界模型,HY-World 2.0支持文字、图片和视频等形式输入,可自动生成、重建并模拟完整的3D世界。

当一家成立不到两年、团队规模不过 10 人的创业公司被收购,并在数周内关闭产品、清空数据,这通常不会成为行业关注的焦点。但这一次不同。收购方是 OpenAI,而被收购的,是一家试图用模型重写个人理财方式的初创公司——Hiro Finance。
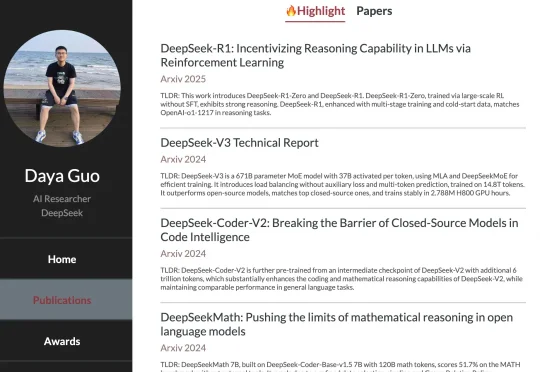
刚刚,图灵联合创始人刘江在海外社交媒体X上透露,DeepSeek核心研究院——郭达雅已加入字节跳动。 郭达雅2023年博士毕业后加入DeepSeek,title是AI Researcher。公开论文显示,从 DeepSeek-Coder、DeepSeek-Math、DeepSeek-Prover、DeepSeek-V3到 DeepSeek-R1,他都出现在核心作者名单中。

Anthropic正式推出了Claude Code的自动化任务功能Routines,目前处于研究预览阶段。只要配置好一次提示词、代码仓库和连接器,Claude就能在云端全自动干活了。这些任务全部运行在Anthropic的云端基础设施上,意味着完全不需要你一直开着电脑,哪怕你下班关机,它也能按时帮你处理代码积压、审查代码,甚至随时响应云端事件。
拍一圈照片,就能生成一个可交互的 3D 世界,已经不是什么新鲜话题了。但问题是如何把一个大世界塞进普通人的手机浏览器里。