
全球 AI 公司烧了几千亿,最后都得抢着给苹果「打工」
全球 AI 公司烧了几千亿,最后都得抢着给苹果「打工」就在刚刚,据彭博社报道,iOS 27 将引入一套名为「Extensions」的新机制,允许用户通过设置面板,把 Google Gemini、Anthropic Claude 等第三方 AI 接入 Siri,就像现在调用 ChatGPT 一样直接从 Siri 发起请求。
来自主题: AI资讯
8345 点击 2026-03-27 14:22
 搜索
搜索
就在刚刚,据彭博社报道,iOS 27 将引入一套名为「Extensions」的新机制,允许用户通过设置面板,把 Google Gemini、Anthropic Claude 等第三方 AI 接入 Siri,就像现在调用 ChatGPT 一样直接从 Siri 发起请求。
前几天,一篇来自Kimi的论文「ATTENTION RESIDUALS」在 AI 圈引发了激烈讨论——马斯克罕见地发出评价:"Impressive work from Kimi"。同时,两位前Openai大佬也同样发出了高度评价,OpenAI 「推理模型之父」Jerry Tworek表示“深度学习2.0时代即将到来”。
近日,金融AI领跑者讯兔科技(Alpha派)正式完成近2亿元A轮融资。继去年10月完成超亿元Pre-A轮融资后,讯兔科技在短短5个月内再获顶级机构强强加持。讯兔科技的核心团队成员均来自国内头部资管机构,拥有稀缺的投研基因。团队成员曾主导头部公募基金数字化体系建设,并曾在FactSet、标普全球、汤森路透等国际金融资讯巨头担任过技术研发与商业化核心高管。
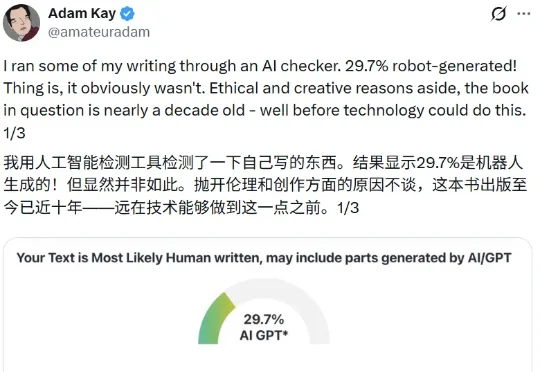
前两天,知名畅销书作家 Adam Kay 在社交媒体 X 分享了自己的经历:他心血来潮,把自己的作品丢进一款 AI 检测器里查重,结果系统信誓旦旦地判定其中有 29.7% 的内容由机器生成。
今夜,整个AI圈震动了。全球最难AGI测试ARC-AGI-3一上线,就把全球顶尖AI打到集体失声,人类满分通关,最强模型Opus 4.6得分仅0.2%,还不到1%。AI这是一夜被打回「原始人」了。

Cursor套壳Kimi这事还没完…… 最新消息,Cursor放出Composer 2技术报告,力证自己还是有在“自研”。(doge) 不是纯套,而是有技术地套、循序渐进地套。用的方法,还是他们一开始就强调的预训练+强化学习。
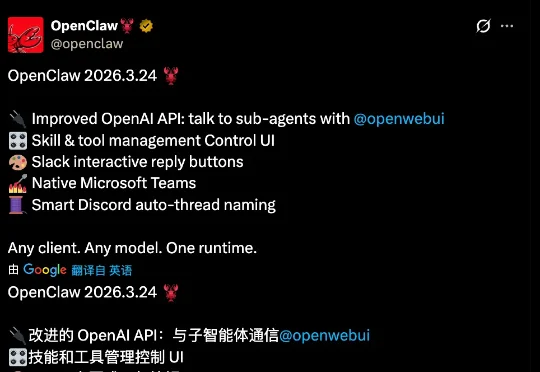
OpenClaw 又开始日更了:Skills 安装终于不用自己猜缺什么了,系统会手把手告诉你下一步;控制台界面也大改,找东西不再像在迷宫里转。另外堵上了一个文件访问的安全漏洞,Telegram、Discord、WhatsApp 的频道 bug 也扫了一轮。

2026年3月26日彭博独家爆料,AI独角兽Moonshot AI(月之暗面)正处于考虑在香港进行IPO的早期阶段,计划登陆香港资本市场。
就在昨天,全球 AI 视频生成领域迎来了一场 “超级地震”——OpenAI 竟然意外叫停了万众瞩目的 Sora 2 项目。

3月24日,Anthropic宣布Claude引入“Computer Use”能力,在Claude Cowork和Claude Code中,Claude可以直接操作用户的Mac电脑:打开文件、使用浏览器、运行开发工具,无需任何配置。该功能以研究预览版形式向Pro和Max订阅用户开放。