
截击英伟达!OpenClaw狂吞Token,北大系芯片黑马剑指2000 Tokens/s
截击英伟达!OpenClaw狂吞Token,北大系芯片黑马剑指2000 Tokens/s英伟达200亿美元「招安」Groq,推理芯片赛道一夜变天。但在大洋彼岸,一家北大系创业公司刚刚交出了自己的流片答卷。
来自主题: AI资讯
6990 点击 2026-03-10 15:08
 搜索
搜索
英伟达200亿美元「招安」Groq,推理芯片赛道一夜变天。但在大洋彼岸,一家北大系创业公司刚刚交出了自己的流片答卷。

DragStream,首次实现视频生成时的实时拖拽编辑。用户可随时拖动画面中的物体,自由平移、旋转或变形,系统自动保持后续帧连贯自然,无需重训模型,无缝适配主流AI视频生成器,真正实现「所见即所得」。

视频生成进入大规模时代,但计算成本也炸了。
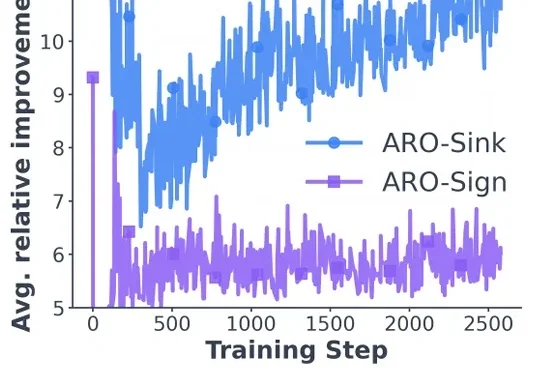
如果你在过去一年关注过大模型训练的技术,大概率听过 Muon 这个名字 —— 这个在月之暗面 K2 模型的相关讨论中走红的优化器,被视为是可能挑战 Adam 的新秀。它的思路很直接:对动量矩阵进行正交化,让各个奇异方向上的更新速率一致,提升训练效率。
OpenClaw爆火但安装门槛极高,催生天价代装生意。AutoClaw(澳龙),将其打包为一键安装桌面应用,小白也能1分钟上手。内置全新Agent模型Pony-Alpha-2,支持模型热插拔与飞书集成,50+技能开箱即用,彻底终结「付费装虾」时代。

从面世以来,AI 检测工具的准确性就一直屡遭诟病。
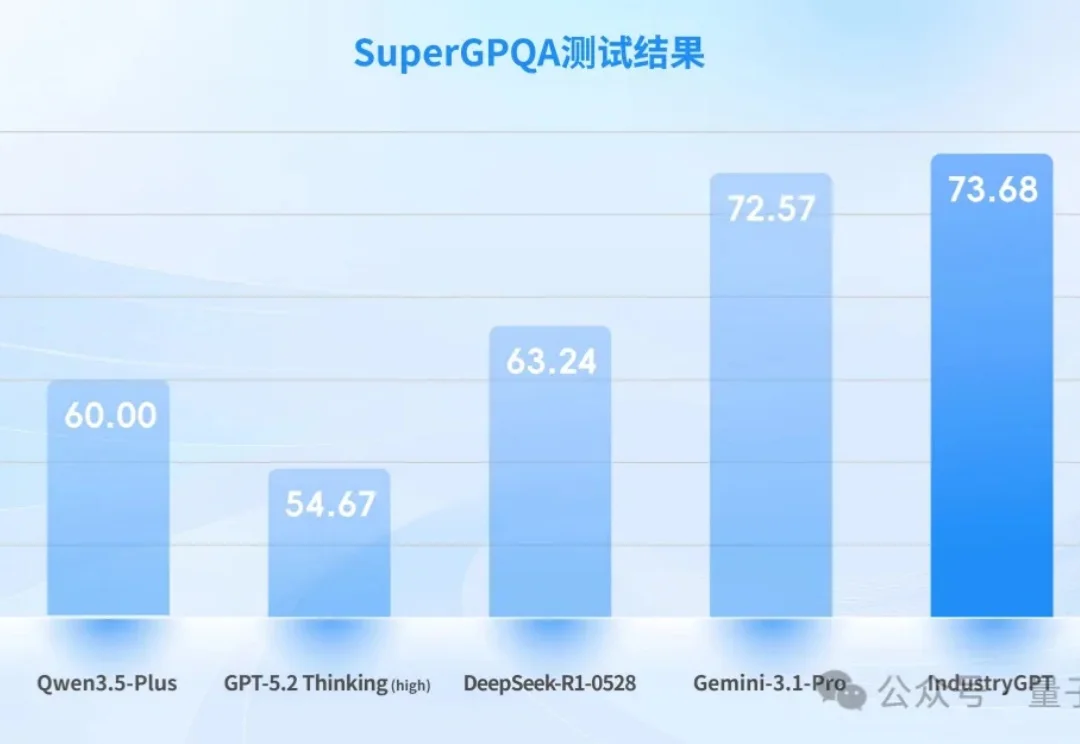
最近,一批顶级通用大模型参加了三场特殊的“工业执业考试”。

2026,什么最火爆?
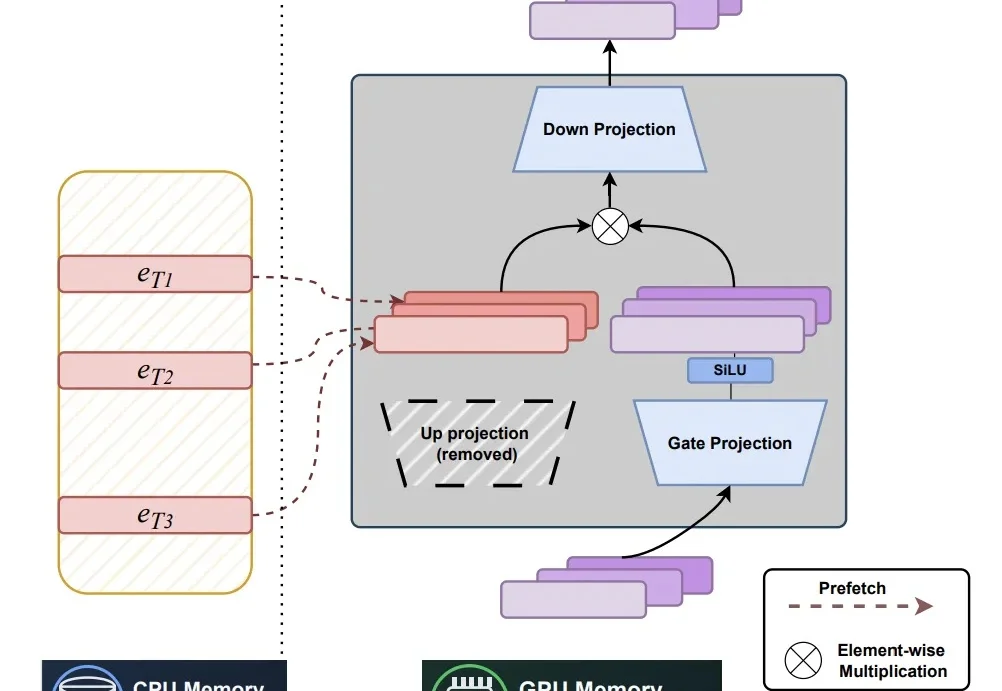
近年来,随着大语言模型规模与知识密度不断提升,研究者开始重新思考一个更本质的问题:模型中的参数应如何被组织,才能更高效地充当「记忆」。

在 AI 视觉生成领域,扩散模型(DM)凭借其强大的高保真数据生成能力,已成为图像合成、视频生成等多模态任务的核心框架。然而,预训练后的扩散模型如何高效适配下游应用需求,一直是行业面临的关键挑战。