上线2个月收获200万用户,出海游戏公司转型做AI,赢麻了?
上线2个月收获200万用户,出海游戏公司转型做AI,赢麻了?观察榜单发现,近期一款仅上线2个多月的AI内容生成出海产品KLING AI在韩国、印尼霸榜图形和设计免费榜Top1,并跻身进入了沙特、马来西亚、越南等十余个国家地区Top10,全球总下载量高达约210万,单日下载峰值13万。
来自主题: AI资讯
8092 点击 2025-03-25 22:22
 搜索
搜索
观察榜单发现,近期一款仅上线2个多月的AI内容生成出海产品KLING AI在韩国、印尼霸榜图形和设计免费榜Top1,并跻身进入了沙特、马来西亚、越南等十余个国家地区Top10,全球总下载量高达约210万,单日下载峰值13万。

AI界「智商大考」ARC-AGI-2重磅出炉了!一个人类用5分钟轻松解开的谜题,却让最顶尖LLM全线崩盘得分挂零,o3更是从曾经76%暴跌至4%。它正式宣告,人类还未实现AGI。

从微观世界的分子与材料结构、到宏观世界的几何与空间智能,创建和理解 3D 结构是推进科学研究的重要基石。3D 结构不仅承载着丰富的物理与化学信息,也可为科学家提供解构复杂系统、进行模拟预测和跨学科创新的重要工具。
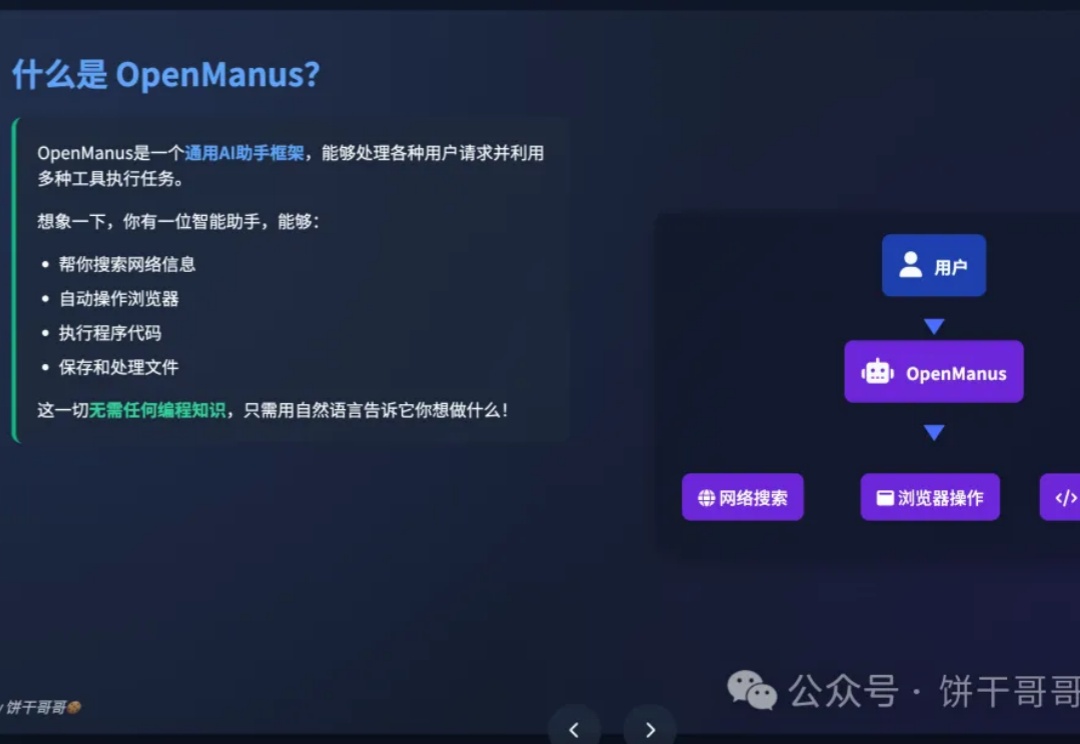
昨天我们介绍了什么是AI Agent,今天介绍一个开源的AI Agent框架,也是一号难求「Manus」的“平替”——OpenManus——曾经3小时完成Manus复刻的「神」

聚焦4-14岁人群的AI智能硬件——Teeni.AI“随身智能体”。

685B的DeepSeek-V3新版本,就在昨夜悄悄上线了。参数量685B的V3,代码数学推理再次显著提升,甚至代码追平Claude 3.7,网友们实测后大呼强到离谱!有人预测说,按照此前的节奏,DeepSeek-R2大概率几周内就将上线。

本文介绍了当前最受科研人员青睐的AI模型,推理出色的o3-mini、全能型DeepSeek-R1、科研常用的Llama、编程利器Claude 3.5 Sonnet和开源明星Olmo 2,它们各有优劣,为科研人员提供了多样选择。
就在DeepSeek-V3更新的同一夜,阿里通义千问Qwen又双叒叕一次梦幻联动了——

在软件开发等领域,AI将打响取代人类第一枪!美国调查报道显示,AI将影响全球近40%的就业机会,70%的职业技能将发生改变。而一旦发生经济危机,AI就业革命或将在全美各行业引爆!

DeepSeek V3升级了,新版本V3-0324。