
亚马逊年末甩王炸,6款大模型、3nm AI芯片、全球最大AI计算集群,苹果罕见站台
亚马逊年末甩王炸,6款大模型、3nm AI芯片、全球最大AI计算集群,苹果罕见站台亚马逊宣布扩建AI计算集群并推出新AI产品。 豪掷80亿美元后,亚马逊“绑死”Anthropic,要建全球最大AI计算集群。
来自主题: AI资讯
7809 点击 2024-12-04 09:45
 搜索
搜索
亚马逊宣布扩建AI计算集群并推出新AI产品。 豪掷80亿美元后,亚马逊“绑死”Anthropic,要建全球最大AI计算集群。

2023年紧急成立的Seed团队,某种程度上承担了AI Lab最初成立时被赋予的角色;

李飞飞的World Labs首个「空间智能」模型,刚刚诞生了!一张图生成一个3D世界,网友惊呼:太疯狂了,我们进入了下一轮革命,这就是视频游戏、电影的未来。
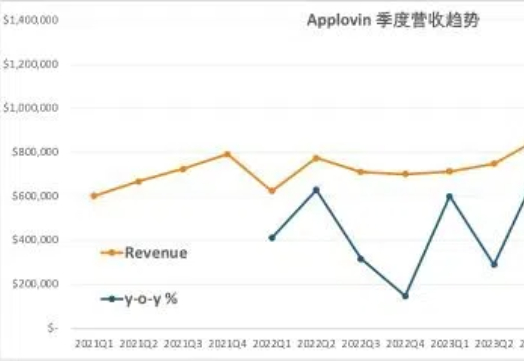
2023年初,GPT3.5发布,效果让全世界咋舌。人们恐慌,人工智能时代来临了。随之而来的是各大互联万公司纷纷下场比拼大模型,几乎每个月都能耳听目见新的大模型诞生,并且在某个参数上和“GPT几点几”媲美。随着大模型不断迭代与渗透,一个关键问题随之而来:谁是大模型浪潮的最大受益者?

德国防务技术公司Helsing近日发布了其首款人工智能驱动的自杀式打击无人机 HX-2。这款电动 “X 翼” 无人机具有136英里每小时(约220公里每小时)的最高速度和62英里(约100公里)的作战范围。HX-2的核心组件经过了实际战斗的检验,展示了其强大的作战能力。
听哥一句劝,这种事咱图一乐就行了。 纳了闷儿了,现在已经是进入 AI 时代第三年了,靠 AI 赚钱的人咱是真看了不少。 有时候有几个心术不正的,拿 AI 骗钱的咱也不是没见过。 但骗 AI 钱的,世超我还真是头一次看见。

36氪获悉,近日北京悦点科技有限公司(以下简称“悦点科技”)完成数千万元人民币的天使轮融资。本轮融资由云启资本独家投资,融得资金将主要用于公司在企业级GenAI应用平台的进一步研发和商业拓展。
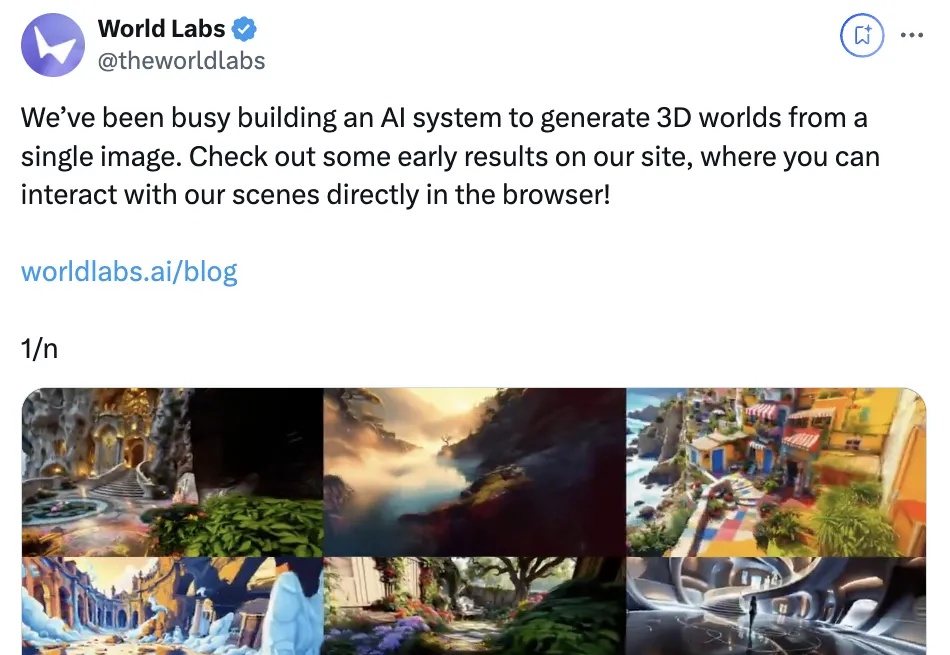
就在刚刚,李飞飞空间智能首个项目突然发布: 仅凭借1张图,就能生成一个3D游戏世界的AI系统!
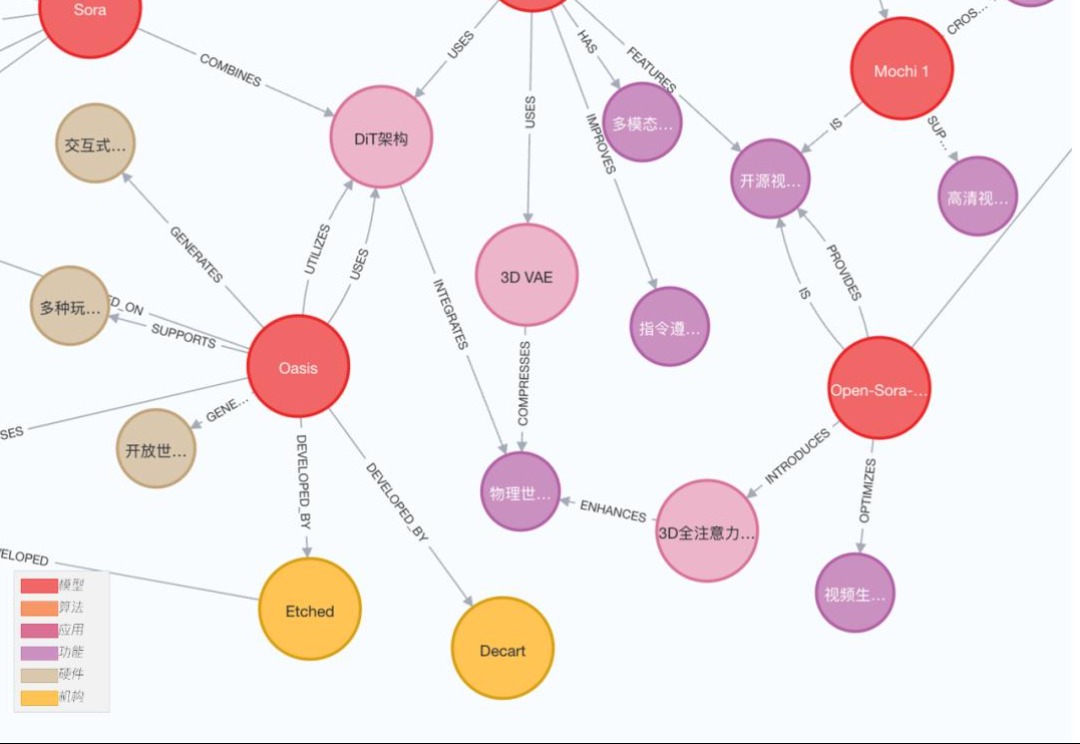
本期 AGI 路线图中关键节点:Sora、DiT、Runway Gen-3、可灵 AI、Oasis、世界模拟器
在这个信息爆炸的时代,我们每天都在被海量的数据淹没。如何从这些数据中挖掘出有价值的信息,已经成为了一个亟待解决的问题。今天,我们要给大家带来一个震撼人心的消息——AI界的两大神器,Hebbia和Wiseflow,正在改变我们获取和处理信息的方式。