Claude 3.5两小时暴虐50多名专家,编程10倍速飙升!但8小时曝出惊人短板
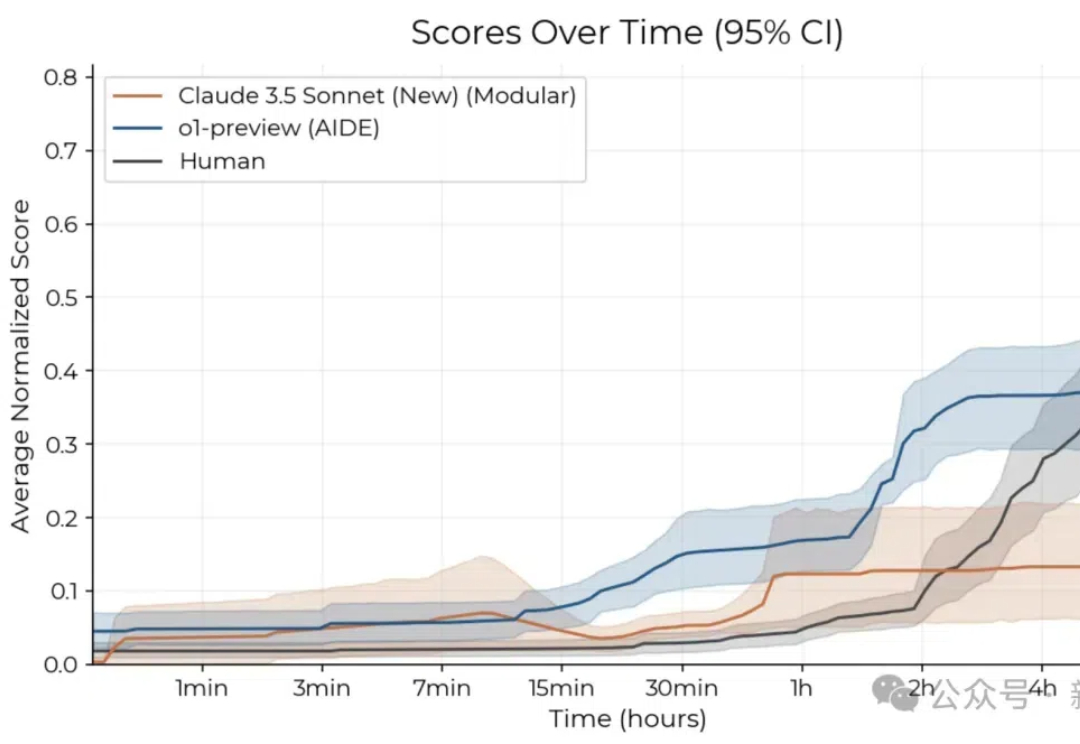
Claude 3.5两小时暴虐50多名专家,编程10倍速飙升!但8小时曝出惊人短板AI自主研发会真的「失控」了吗?最新研究显示,Claude 3.5 Sonnet和o1-preview在2小时内的研发任务中,击败了50多位人类专家。但另一个耐人寻味的现象是,给予更长时间周期后,人类专家在8小时任务中优势显现。
来自主题: AI技术研报
7625 点击 2024-11-24 21:22
 搜索
搜索
AI自主研发会真的「失控」了吗?最新研究显示,Claude 3.5 Sonnet和o1-preview在2小时内的研发任务中,击败了50多位人类专家。但另一个耐人寻味的现象是,给予更长时间周期后,人类专家在8小时任务中优势显现。
「带薪拉屎」越来越难,求摸鱼技巧更新!

在11月20日盘后,英伟达(NVDA.O)公布的财报显示,第三季度营收达到351亿美元,增幅近乎翻倍。

近日,汤姆猫(SZ.300459)披露投资者关系活动,纪录表显示,汤姆猫正在研发的 AI 产品包括汤姆猫 AI 语音机器人、AI 讲故事 APP、 AI 游戏等系列产品。其中,第一代汤姆猫 AI 机器人产品预计春节前上市。
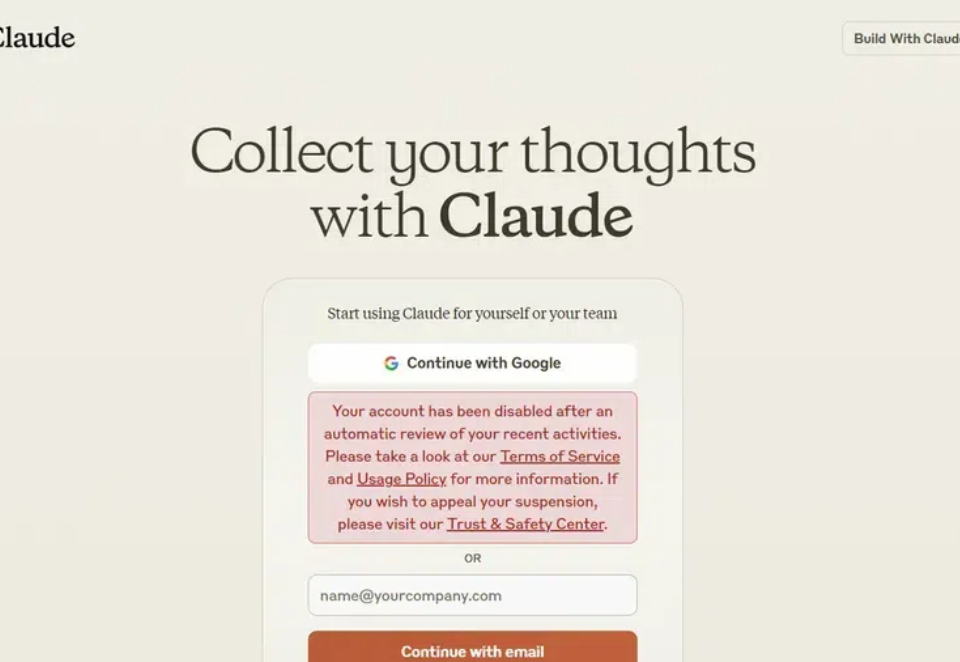
忙了一上午,我端着咖啡,习惯性地打开电脑,想和我的「数字大脑」Claude 开始干活。谁知道一个提示框直接把我打懵了—— Claude 账号被封了。那一刻, 手里咖啡不香了。
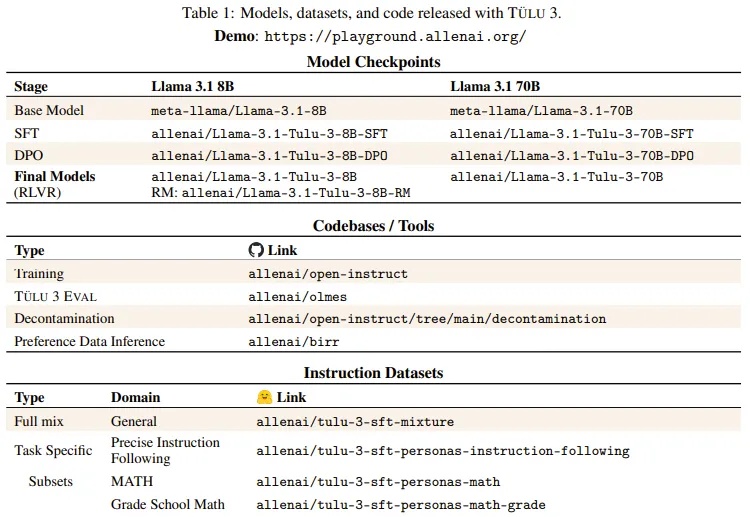
开源模型阵营又迎来一员猛将:Tülu 3。它来自艾伦人工智能研究所(Ai2),目前包含 8B 和 70B 两个版本(未来还会有 405B 版本),并且其性能超过了 Llama 3.1 Instruct 的相应版本!长达 73 的技术报告详细介绍了后训练的细节。

这两天,在X上看到一个很酷的2D动漫AI视频。
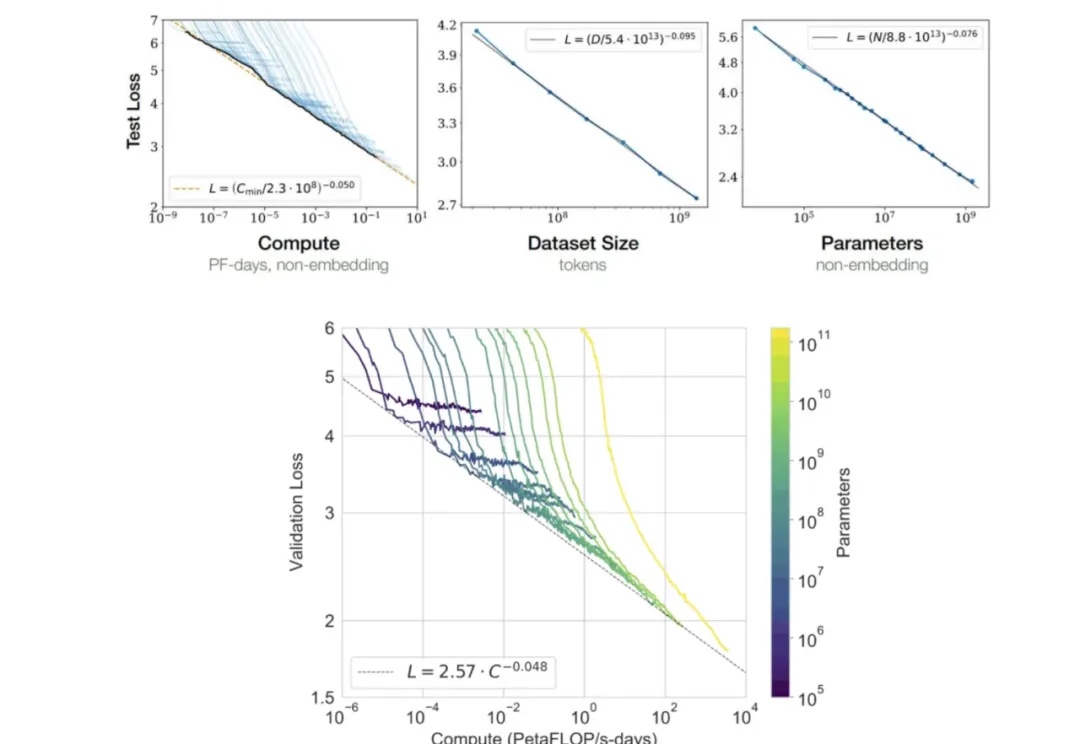
Claude 3.5 Sonnet 应该是目前公认综合能力最好的基础模型。

自2023年以来,国资委多次对中央企业发展人工智能提出要求。其中,在2024年2月的中央企业人工智能专题推进会上,提出中央企业要“开展AI+专项行动”。会上就有10家央企签署倡议书,表示将主动向社会开放人工智能应用场景
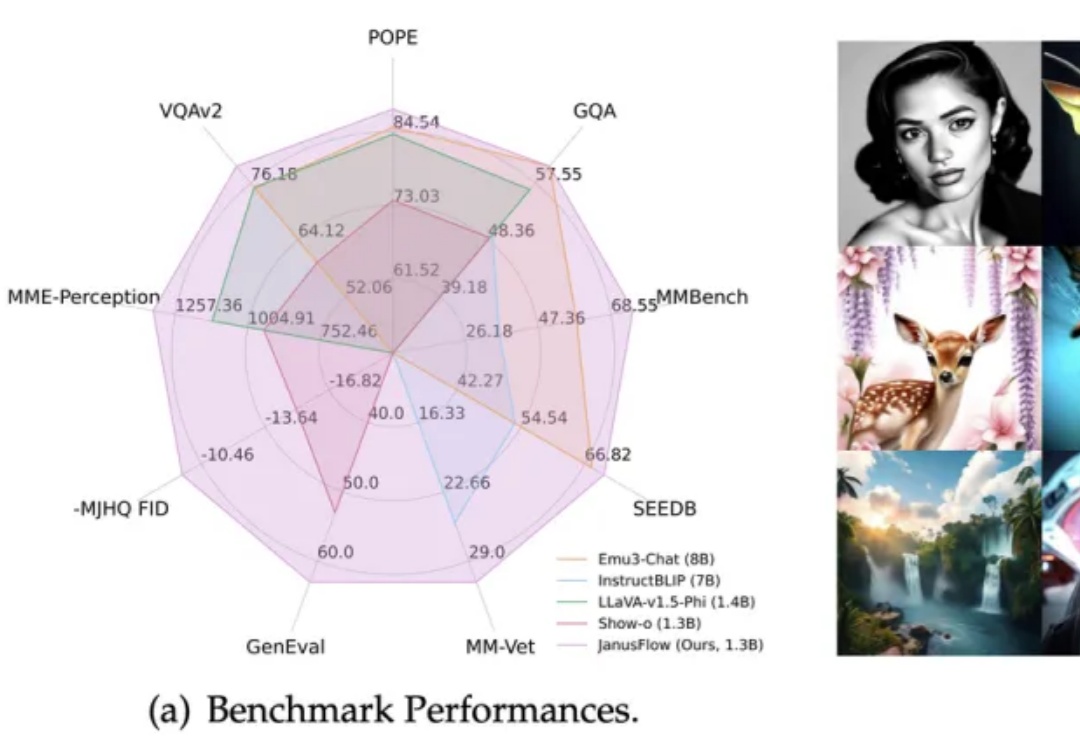
在多模态AI领域,基于预训练视觉编码器与MLLM的方法(如LLaVA系列)在视觉理解任务上展现出卓越性能。