谷歌DeepMind祭出蛋白质设计新AI,有望攻克癌症!蛋白亲和力暴增300倍
谷歌DeepMind祭出蛋白质设计新AI,有望攻克癌症!蛋白亲和力暴增300倍今天,DeepMind又发布了Alpha模型家族的新成员,堪称是「专精版」的AlphaFold,专注于设计蛋白质结合剂,将大幅减少所需的实验室工作,提升开发效率。
来自主题: AI技术研报
7457 点击 2024-09-07 11:30
 搜索
搜索
今天,DeepMind又发布了Alpha模型家族的新成员,堪称是「专精版」的AlphaFold,专注于设计蛋白质结合剂,将大幅减少所需的实验室工作,提升开发效率。
今年 7 月,一份《全球数字经济白皮书 (2024)》统计显示,全球目前已有 1300 多个基础大模型,美国的数量最多,中国紧随其后排在第二。

涌现(Emergence),是生成式AI浪潮的一个关键现象:当模型规模扩大至临界点,AI会展现出人类一般的智慧,能理解、学习甚至创造。
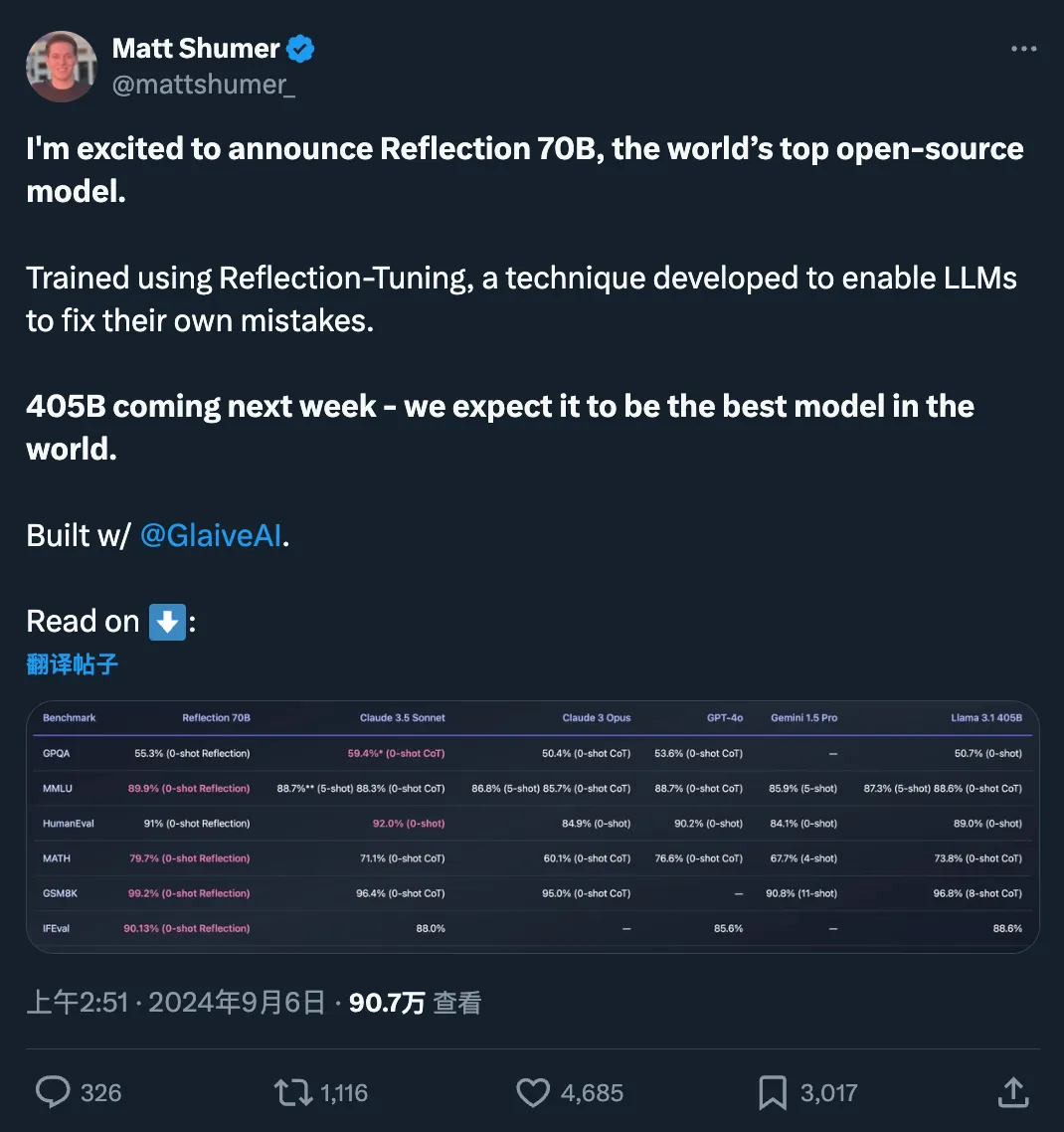
快速更迭的开源大模型领域,又出现了新王:Reflection 70B。 横扫 MMLU、MATH、IFEval、GSM8K,在每项基准测试上都超过了 GPT-4o,还击败了 405B 的 Llama 3.1。 这个新模型 Reflection 70B,来自 AI 写作初创公司 HyperWrite。

你敢相信 4B 参数小模型,性能却超越千亿量级的 GPT-3.5 !OpenAI、谷歌、微软、苹果等一众海内外巨头还没做到的事,被一家中国大模型公司抢先了!

视频理解仍然是计算机视觉和人工智能领域的一个主要挑战。最近在视频理解上的许多进展都是通过端到端地训练多模态大语言模型实现的[1,2,3]。然而,当这些模型处理较长的视频时,内存消耗可能会显著增加,甚至变得难以承受,并且自注意力机制有时可能难以捕捉长程关系 [4]。这些问题阻碍了将端到端模型进一步应用于视频理解。

头部模型的新一代模型的是市场观测、理解 LLM 走向的风向标。即将发布的 OpenAI GPT-Next 和 Anthropic Claude 3.5 Opus 无疑是 AGI 下半场最关键的事件。
此次进攻电商,百度使出的杀手锏是AI。

AI半年考,人工智能上市公司的业绩答卷如何 截至 8 月底,据 IT 桔子不完全统计,至少有 34 家有人工智能相关业务的中国上市公司都已经公布了 2024 半年报。

GPT-5有3-5万亿参数,由7000块B100炼成?!