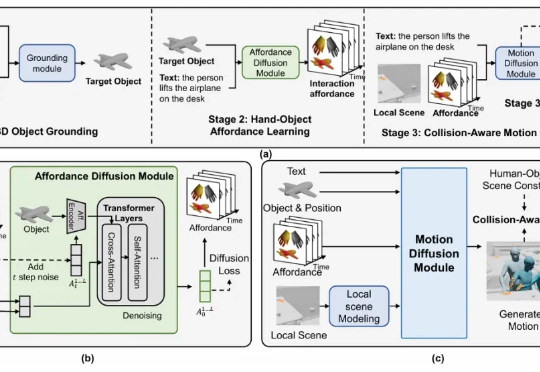
ACMMM 2025 | 北大团队提出 InteractMove:3D场景中人与可移动物体交互动作生成新框架
ACMMM 2025 | 北大团队提出 InteractMove:3D场景中人与可移动物体交互动作生成新框架该研究首次提出了含可移动物体的 3D 场景中,基于文本的人 - 物交互生成任务,并构建了大规模数据集与创新方法框架,在多个评测指标上均取得了领先效果。
来自主题: AI技术研报
7905 点击 2025-10-20 14:40
 搜索
搜索
该研究首次提出了含可移动物体的 3D 场景中,基于文本的人 - 物交互生成任务,并构建了大规模数据集与创新方法框架,在多个评测指标上均取得了领先效果。
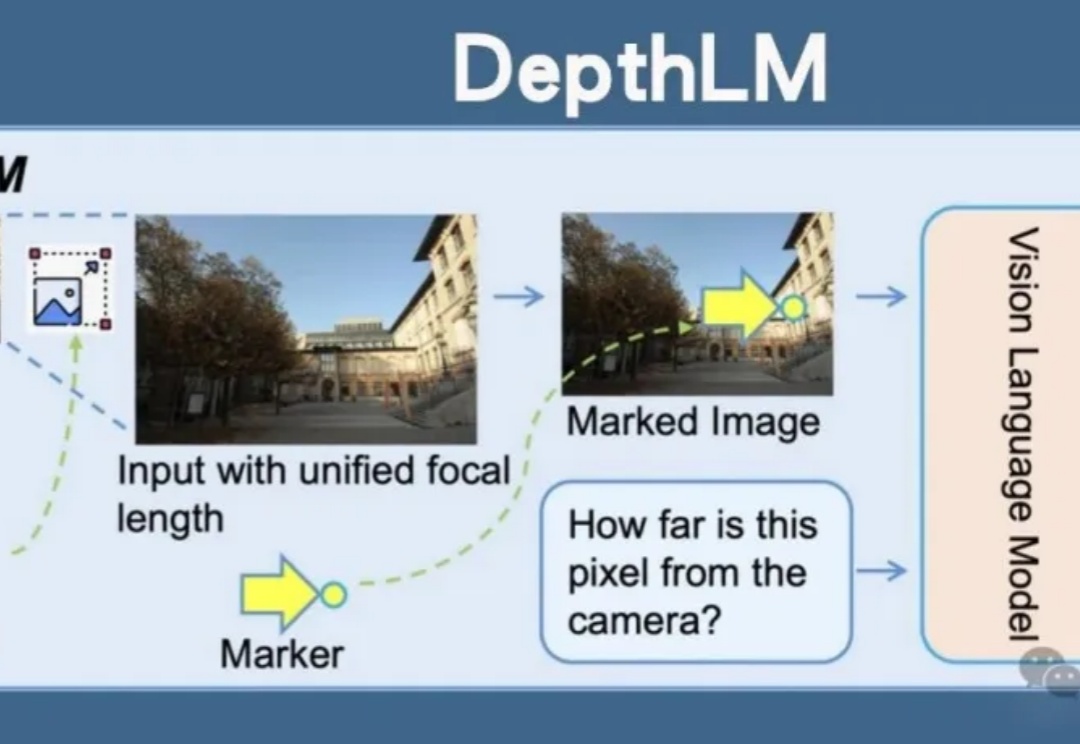
Meta开源DepthLM,首证视觉语言模型无需改架构即可媲美纯视觉模型的3D理解能力。通过视觉提示、稀疏标注等创新策略,DepthLM精准完成像素级深度估计等任务,解锁VLM多任务处理潜力,为自动驾驶、机器人等领域带来巨大前景。
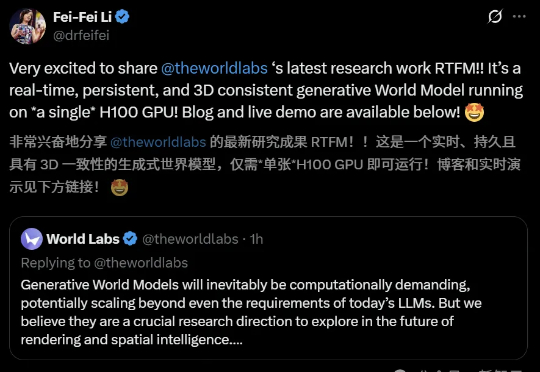
一张图,一个3D世界!今天,李飞飞团队重磅放出实时生成世界模型「RTFM」,通过端到端学习大规模视频数据,直接从输入2D图像生成同一场景下新视角的图像。值得一提的是,它仅需单块H100 GPU便能实时渲染出持久且3D一致的世界。

李飞飞的世界模型创业,最新成果来了!刚刚,教母亲自宣布对外推出全新模型RTFM(A Real-Time Frame Model),不仅具备实时运行、持久性和3D一致性,更关键的是——单张H100 GPU就能跑。
近年来,NeRF、SDF 与 3D Gaussian Splatting 等方法大放异彩,让 AI 能从图像中恢复出三维世界。但随着相关技术路线的发展与完善,瓶颈问题也随之浮现:

3D 生成正从纯虚拟走向物理真实,现有的 3D 生成方法主要侧重于几何结构与纹理信息,而忽略了基于物理属性的建模。

本周,我们邀请 3D 大模型公司 VAST 的创始人和 CEO 宋亚宸(Simon),和我们聊聊 VAST 最新 3D 生成大模型 Tripo 3.0 背后的故事。这位 97 年的创业者短期内连续融资三轮、每轮数千万美金,积攒了足够的子弹,在闷头苦干一年后,Simon 今年首次上播客,和我们探讨了几个关键的战略问题:
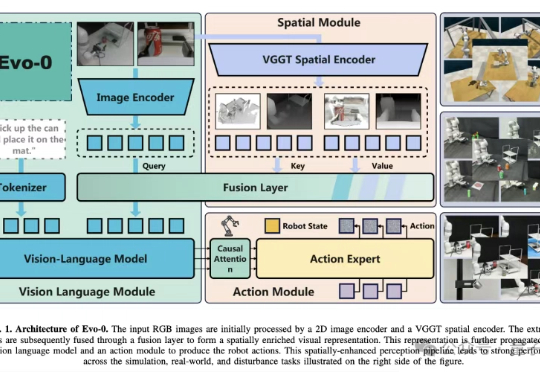
VLA模型通常建立在预训练视觉语言模型(VLM)之上,仅基于2D图像-文本数据训练,缺乏真实世界操作所需的3D空间理解能力。
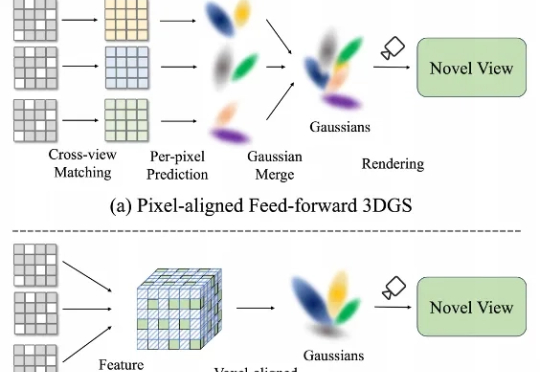
在三维重建不断走向工程化的今天,前馈式3D Gaussian Splatting(Feed-Forward 3DGS)正火速走向产业化。 然而,现有的前馈3DGS方法主要采用“像素对齐”(pixel-aligned)策略——即将每个2D像素单独映射到一个或多个3D高斯上。

由华中科技大学与小米汽车提出了业内首个无需 OCC 引导的多模态的图像 - 点云联合生成框架 Genesis。该算法只需基于场景描述和布局(包括车道线和 3D 框),就可以生成逼真的图像和点云视频。