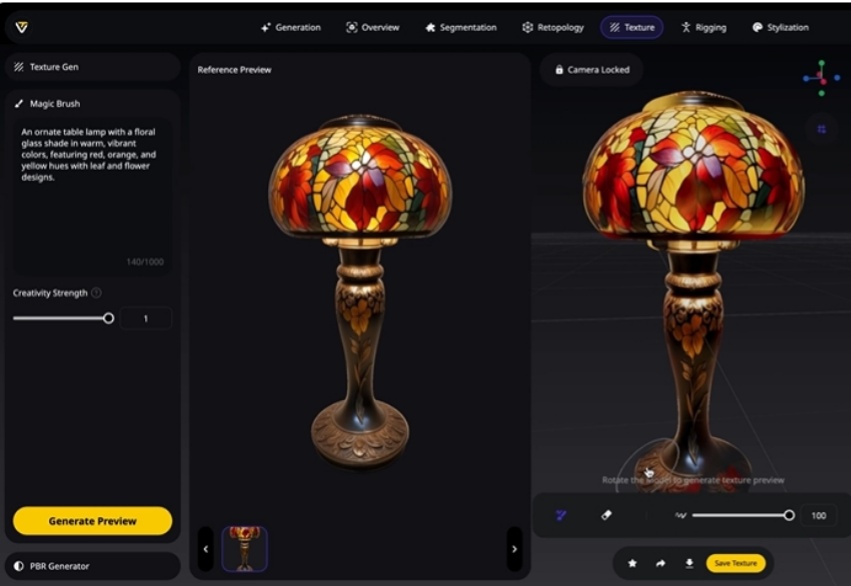
不懂建模也能做角色!VAST升级AI神器,一手实测来了:一键拆建/魔法笔刷/万物绑骨
不懂建模也能做角色!VAST升级AI神器,一手实测来了:一键拆建/魔法笔刷/万物绑骨AI建模界的“作弊神器”真的来了!
来自主题: AI资讯
9695 点击 2025-05-29 18:28
 搜索
搜索
AI建模界的“作弊神器”真的来了!
从OpenAI 的 4o 到 Stable Diffusion,能够根据文本提示生成逼真图像的 AI 基础模型如今已比比皆是。相比之下,能够仅凭文本提示就生成完整、连贯的 3D 在线环境的基础模型才刚刚崭露头角。
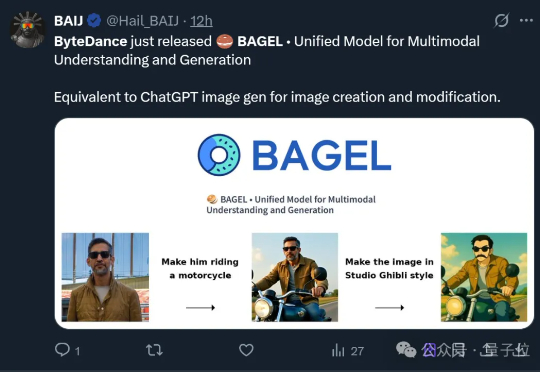
字节最近真的猛猛开源啊……这一次,他们直接开源了GPT-4o级别的图像生成能力。不止于此,其最新融合的多模态模型BAGEL主打一个“大一统”, 将带图推理、图像编辑、3D生成等功能全都集中到了一个模型。

手绘草图一键变身专业游戏形象:

仅需5000美元就能实现人形机器人3D打印?UC伯克利这次又又又整新活了!注意看,画面中这个正在认真写名字的小家伙,就是来自UC伯克利的最新作品——人形机器人Berkeley Humanoid Lite (BHL)。
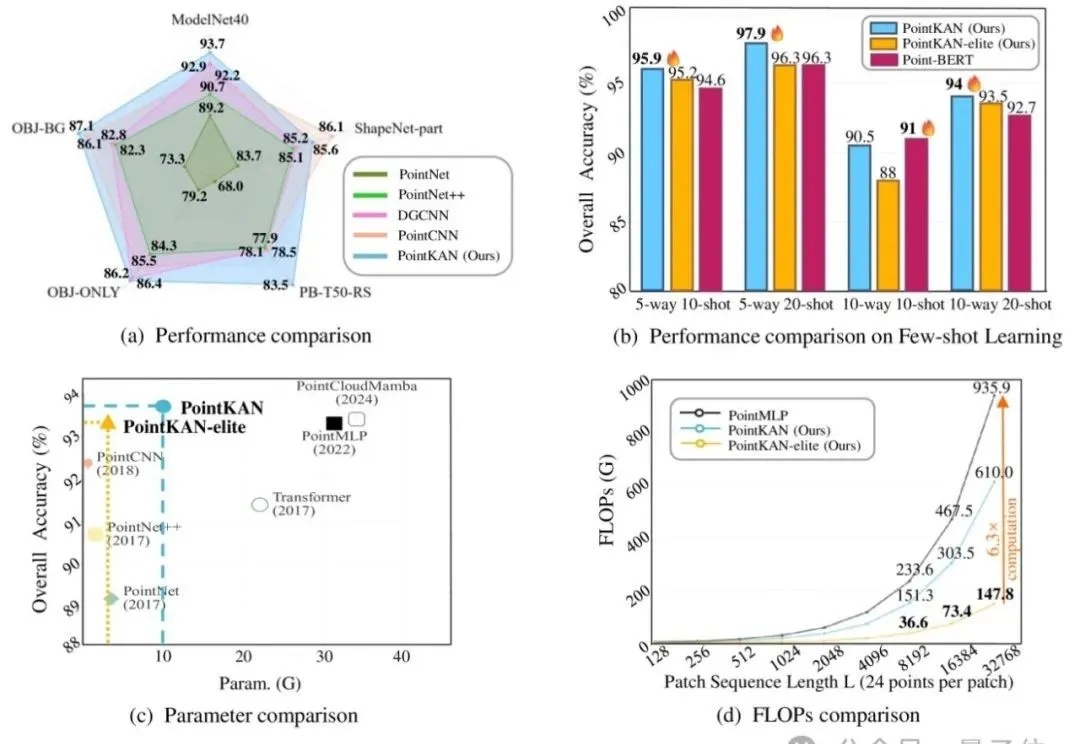
新架构选择用KAN做3D感知,点云分析有了新SOTA!
空间音频,作为一种能够模拟真实听觉环境的技术,正逐渐成为提升沉浸式体验的关键。
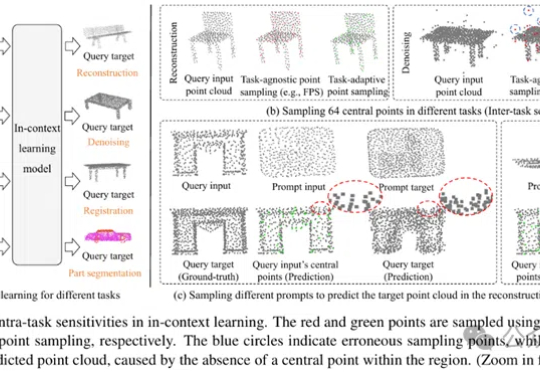
MICAS是一种专为3D点云上下文学习设计的多粒度采样方法,通过任务自适应点采样和查询特定提示采样,提升模型在点云重建、去噪、配准和分割等任务中的稳健性和适应性,显著优于现有技术。

AI 不允许有人不会搭乐高。

如何将一句简单的文字描述变成物理稳定的乐高模型?LegoGPT通过物理感知技术,确保98.8%的设计稳如磐石。