
MVDrag3D:灵活强大的拖拽式多视图3D编辑技术
MVDrag3D:灵活强大的拖拽式多视图3D编辑技术MVDrag3D 是一种创新的3D编辑框架,它通过结合多视图生成和重建先验来实现灵活且富有创造性的拖拽编辑。
来自主题: AI技术研报
4775 点击 2024-11-05 09:38
 搜索
搜索
MVDrag3D 是一种创新的3D编辑框架,它通过结合多视图生成和重建先验来实现灵活且富有创造性的拖拽编辑。

创新是避免内卷的终极解药,这在3D打印行业同样适用。

个性化精品数字人(Personalized Talking Face Generation)强调合成的数字人视频在感官上与真人具有极高的相似性(不管是说话人的外表还是神态)。

日前,MLCommons协会发布最新MLPerf™ Storage v1.0 AI存储基准测试成绩。浪潮信息分布式存储平台AS13000G7表现出众,在3D-UNet和CosmoFlow两个模型共计8项测试中,斩获5项性能全球第一。

前段时间,UGC内容平台Roblox玩家“RG”使用Tripo生成的一顶粉色贝雷帽,在1小时内吸引了超3000名玩家涌入Tripo。“RG”也靠售卖游戏配饰赚到了超过1亿Robux(Roblox内的代币,折合约35万美元,近250万元人民币)。

斯坦福吴佳俊团队与MIT携手打造的最新研究成果,让我们离实时生成开放世界游戏又近了一大步。

在魔珐科技旗下的一站式AIGC(3D)视频创作平台“有言”,其最新版本上线了面容编辑新功能,实现了3D数字人的自定义编辑。
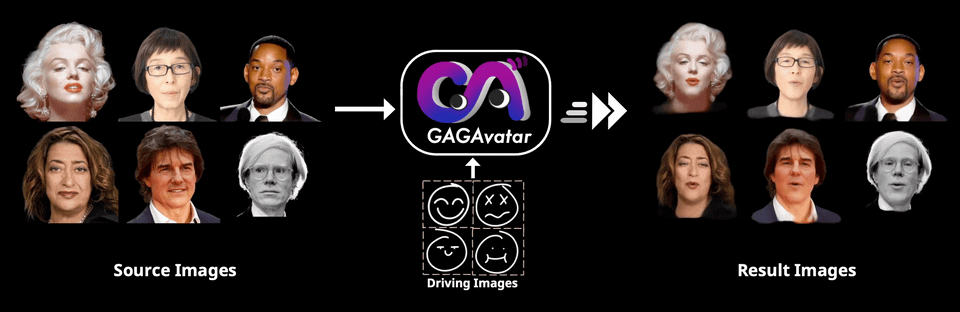
GAGAvatar的出现正是为了解决这一瓶颈,通过一次前向传播就能生成3D高斯参数,实现高效的渲染与动画驱动。

在全球三大IT展之一的GITEX GLOBAL上,量子位在某个展台,先后体验了和Chatbot聊天、用AI创建属于自己的3D数字人形象、和3D形象实时语言、肢体互动。 也就是说,《Her》有了3D虚拟人版。

10 月 12 日,一个平平无奇的周六上午,B 站首页给笔者推送了一个名为「EVE」的 AI 社交新品的预告片