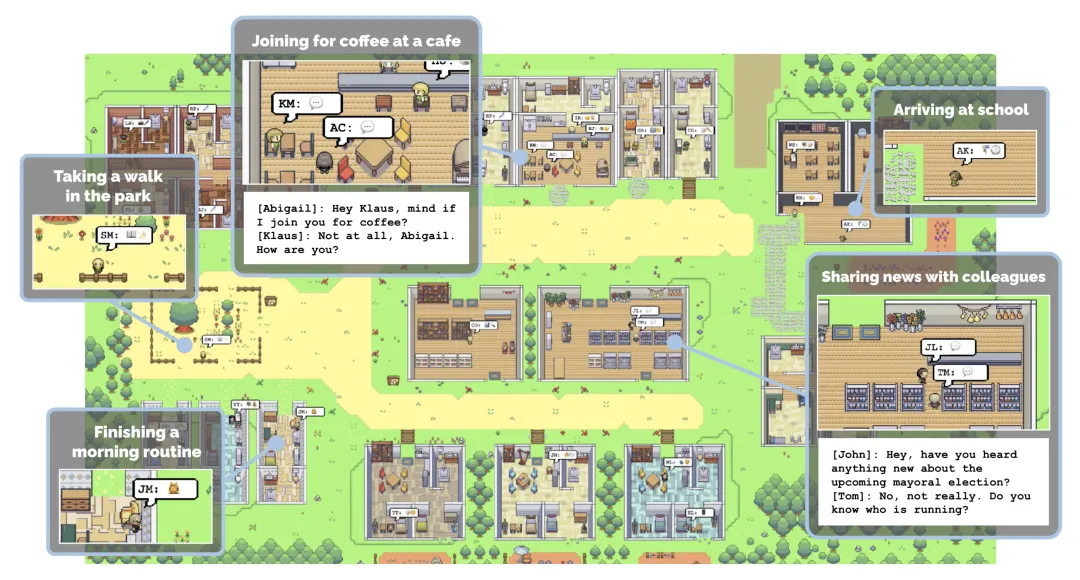
机器人版的「斯坦福小镇」来了,专为具身智能研究打造
机器人版的「斯坦福小镇」来了,专为具身智能研究打造首个专为各种机器人设计的模拟互动 3D 社会。
来自主题: AI技术研报
11427 点击 2024-07-21 14:17
 搜索
搜索
首个专为各种机器人设计的模拟互动 3D 社会。

Fidelity-Scalability-Controllability-Accessibility (真实度-可扩展性-可控性-可用性)是生成式 AI 领域一个很好的研究方法论。会有更多像AnimateDiff这样的技术推动视频生成的广泛应用。

大家对生成视觉领域有着这样的认知:先有图像生成、视频生成,再有3D生成。

随便一张立绘都能生成游戏角色,任意IP快速三维化有新招了!

近期,商汤科技 - 南洋理工大学联合 AI 研究中心 S-Lab ,上海人工智能实验室,北京大学与密歇根大学联合提出 DreamGaussian4D(DG4D),通过结合空间变换的显式建模与静态 3D Gaussian Splatting(GS)技术实现高效四维内容生成。

Meta 3D Gen:AI革命性突破,3D创作从此告别高成本与复杂工艺

Meta的文生3D模型或将给3D创作生态带来剧变。

3D 生成,一直在等待它的「ChatGPT时刻」。

Meta的GenAI团队在最新研究中介绍了Meta 3D Gen模型:可以在不到1分钟的时间内从文本直接端到端生成3D资产。

本文将为大家介绍CVPR 2024 Highlight的论文LangSplat: 3D Language Gaussian Splatting(三维语义高斯泼溅)。LangSplat在开放文本目标定位和语义分割任务上达到SOTA性能。在1440×1080分辨率的图像上,查询速度比之前的SOTA方法LERF快了199倍。代码已开源。