赛诺菲投资、openAI支持,Formation Bio获3.72亿美元D轮融资 | 海外New Things
赛诺菲投资、openAI支持,Formation Bio获3.72亿美元D轮融资 | 海外New Things加速药物开发和临床试验的效率。
来自主题: AI资讯
6781 点击 2024-07-01 12:56
 搜索
搜索
加速药物开发和临床试验的效率。

从MIT辍学后,华裔少年Alexandr Wang开始建立自己的初创公司,从此开始走向人生巅峰。押对数据标注方向后,他在27岁时就成为了亿万富翁。The Information刚刚发了长文,爆料了Wang的公司崛起的内幕。

Meta搞了个很牛的LLM Compiler,帮助程序员更高效地写代码。

被 OpenAI 的 Superalignment 研究团队解雇的 Leopold Aschenbrenner 最近发表了一篇关于人工智能的长篇大作,里面宣称根据他的曲线预测,人类到2027年就能实现通用人工智能。本文是对这一预测的讨论。

可在单张A100/H100 GPU或TPU主机上高效运行全精度推理。

OpenAI在6月25日凌晨宣布,将从7月9日起,将阻止来自不支持其服务的国家和地区的API流量,而中国也在禁用名单之列。

性能翻倍的Gemma 2, 让同量级的Llama3怎么玩?
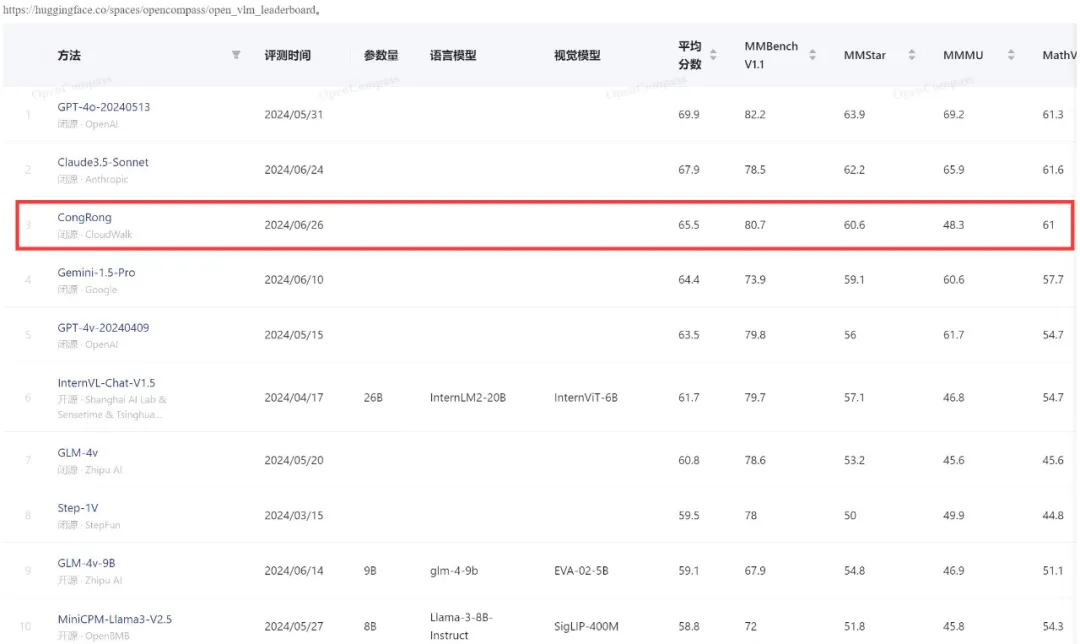
近日,云从科技从容大模型在综合评测权威平台 OpenCompass 的多模态评测领域中取得重大进展。 最新评测结果显示,云从科技的从容大模型在该体系中的平均得分为 65.5,这一成绩使得从容大模型跻身全球前三,超越了谷歌的 Gemini-1.5-Pro 和 GPT-4v,仅次于 GPT-4o(69.9)和 Claude3.5-Sonnet(67.9)。

Claude 3.5 Sonnet的图表推理能力,比GPT-4o高出了27.8%。 针对多模态大模型在图表任务上的表现,陈丹琦团队提出了新的测试基准。 新Benchmark比以往更有区分度,也让一众传统测试中的高分模型暴露出了真实能力。
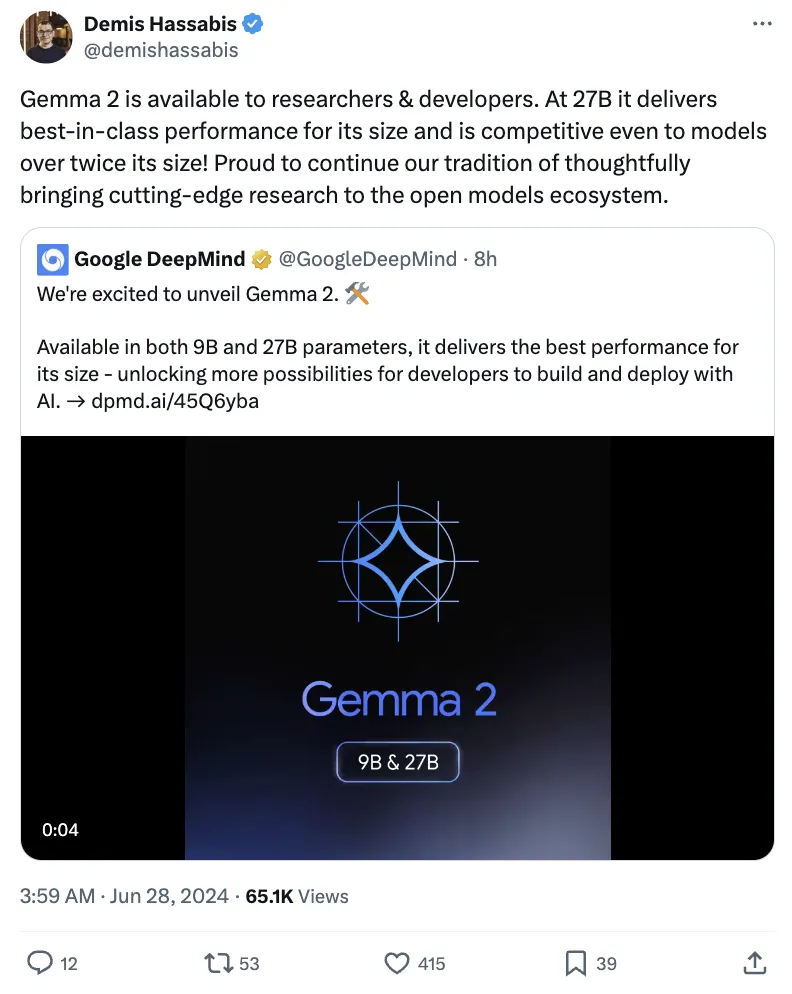
谷歌开源模型Gemma 2开放了! 虽然前段时间Google I/O大会上,Gemma 2开源的消息就已经被放出,但谷歌还留了个小惊喜—— 除27B模型外,还有一个更轻的9B版本。 DeepMind创始人哈萨比斯表示,27B参数规模下,Gemma 2提供了同类模型最强性能,甚至还能与其两倍大的模型竞争。