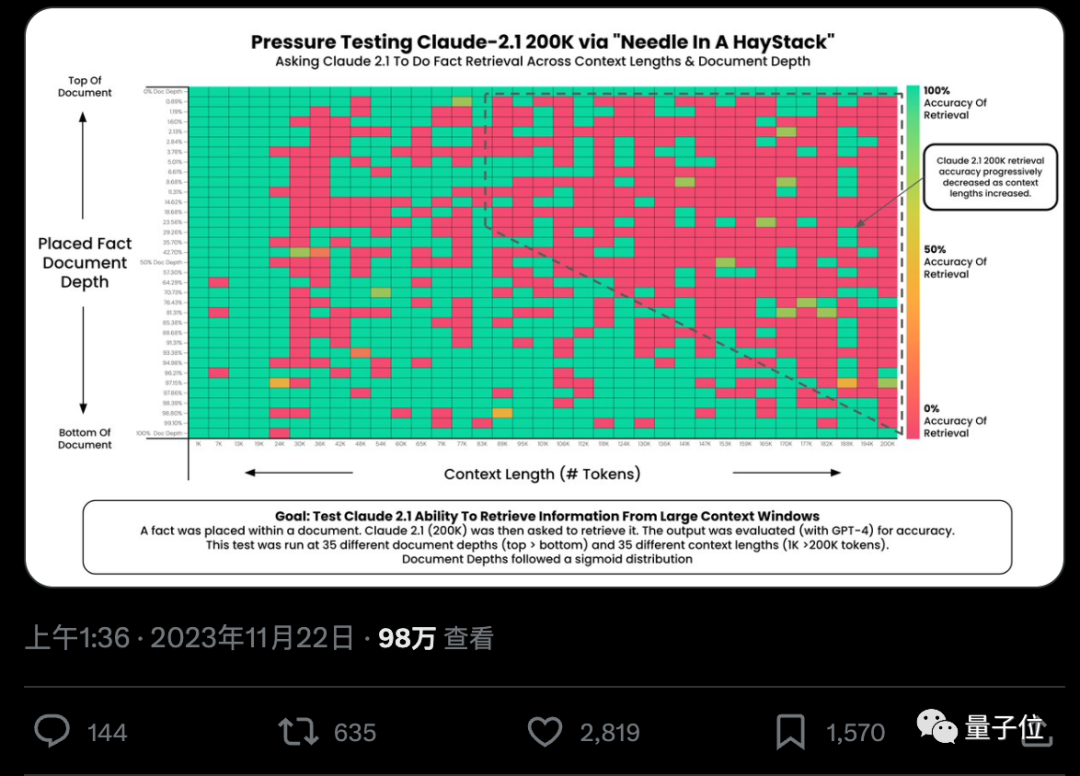
一句话解锁100k+上下文大模型真实力,27分涨到98,GPT-4、Claude2.1适用
一句话解锁100k+上下文大模型真实力,27分涨到98,GPT-4、Claude2.1适用各家大模型纷纷卷起上下文窗口,Llama-1时标配还是2k,现在不超过100k的已经不好意思出门了。然鹅一项极限测试却发现,大部分人用法都不对,没发挥出AI应有的实力。
来自主题: AI资讯
4966 点击 2023-12-11 16:17
 搜索
搜索
各家大模型纷纷卷起上下文窗口,Llama-1时标配还是2k,现在不超过100k的已经不好意思出门了。然鹅一项极限测试却发现,大部分人用法都不对,没发挥出AI应有的实力。
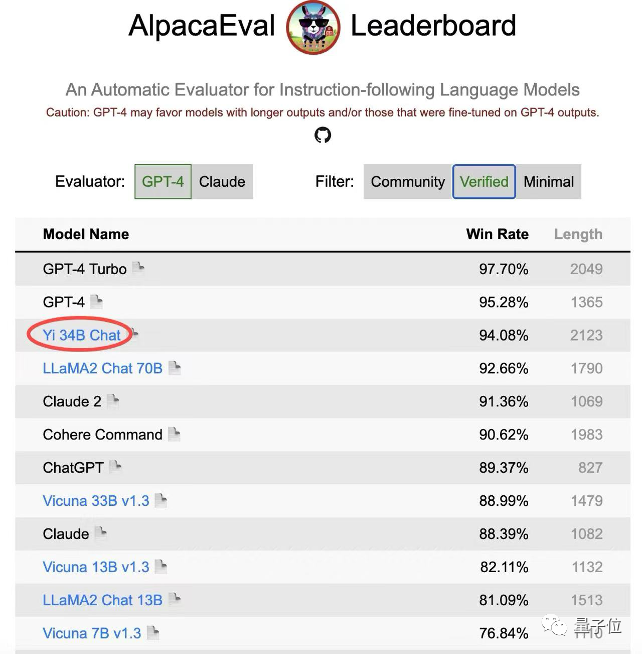
仅次于GPT-4,李开复零一万物Yi-34B-Chat最新成绩公布——在Alpaca经认证的模型类别中,以94.08%的胜率,超越LLaMA2 Chat 70B、Claude 2、ChatGPT!
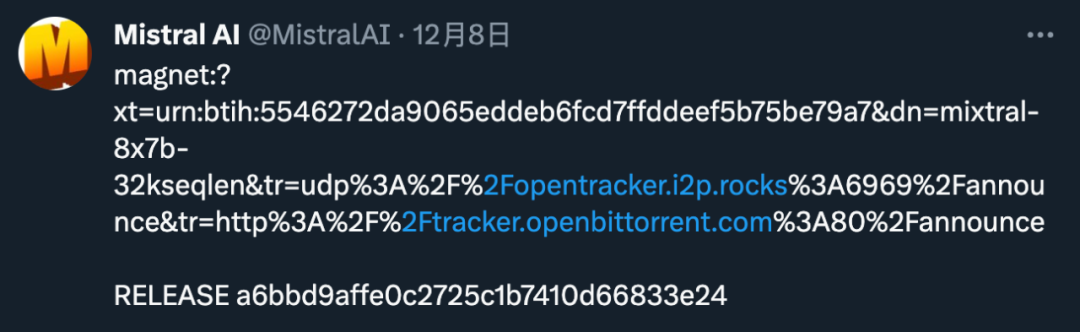
「高端」的开源,往往采用最朴素的发布方式。昨天,Mistral AI 在 X 平台甩出一条磁力链接,宣布了新的开源动作。
“取消今晚所有计划!”,许多AI开发者决定不睡了。只因首个开源MoE大模型刚刚由Mistral AI发布。
苹果M系列芯片专属的机器学习框架,开源即爆火!现在,用上这个框架,你就能直接在苹果GPU上跑70亿参数大模型、训练Transformer模型或是搞LoRA微调。
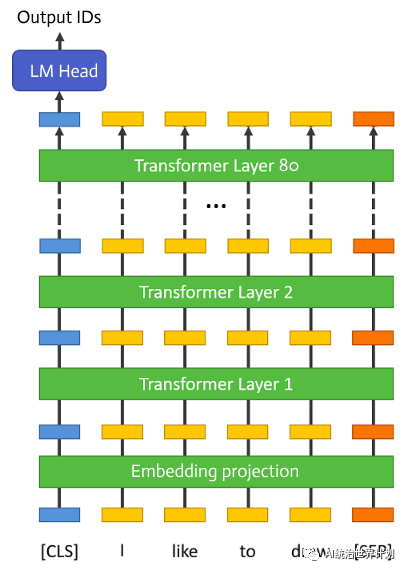
大语言模型需要消耗巨量的GPU内存。有可能一个单卡GPU跑推理吗?可以的话,最低多少显存?70B大语言模型仅参数量就有130GB,仅仅把模型加载到GPU显卡里边就需要2台顶配100GB内存的A100。
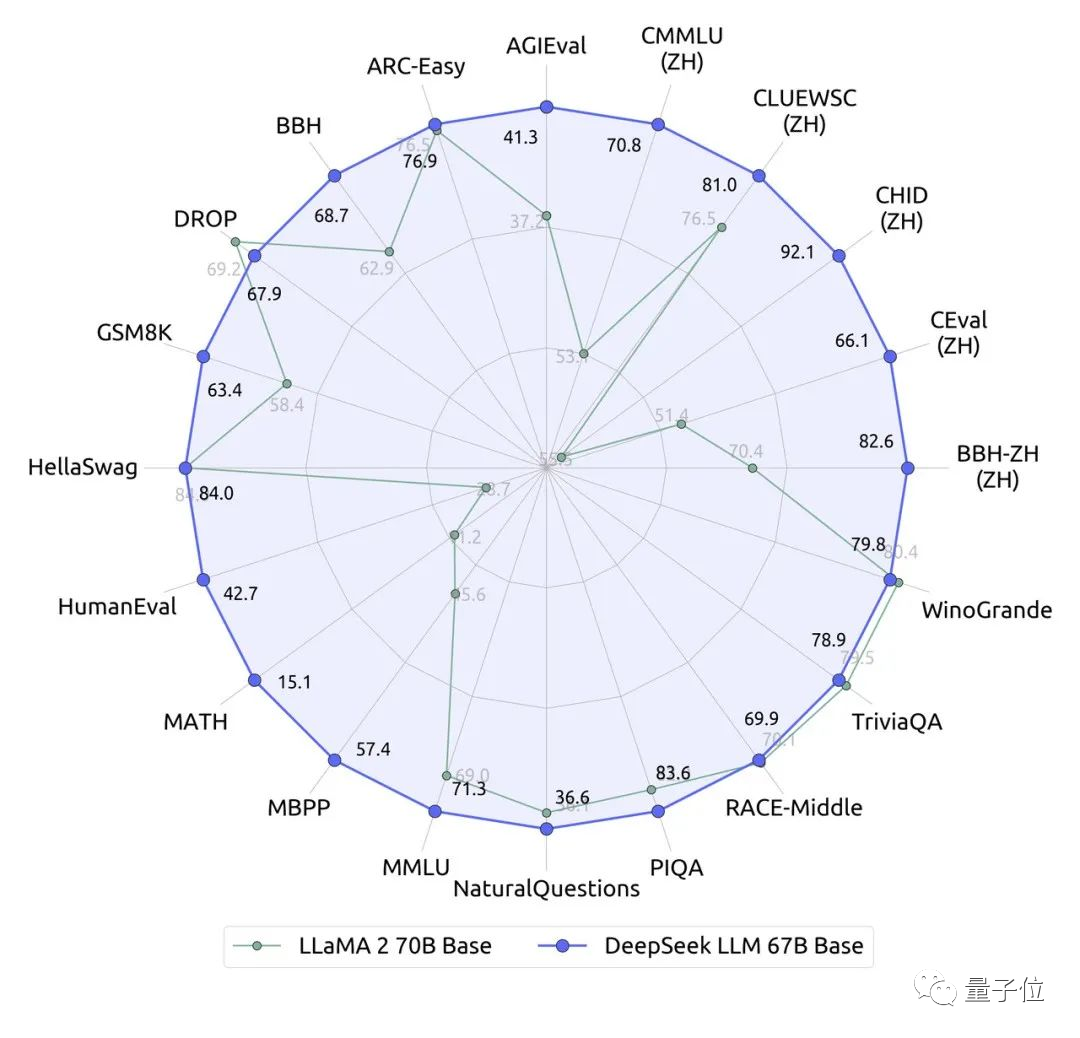
国产大模型刚刚出了一位全新选手:参数670亿的DeepSeek。它在近20个中英文的公开评测榜单上直接超越了同量级、700亿的Llama 2。

“欧洲版OpenAI”最新估值,逼近20亿美元!总部位于巴黎的大模型初创公司Mistral AI最新一轮融资,4.87亿美元。

今年 4 月 7 日,斯坦福大学发表的《Generative Agents: Interactive Simulacra of Human Behavior》论文出来之后的几天内,其中提到了一个很有趣的细节是信息的传递:一个 agent 想要举办情人节派对的消息会在小镇中逐渐扩散开来。

通义千问开源全家桶正式上线!业界最强72B模型直接超越开源标杆Llama 2-70B,还有1.8B模型、音频大模型全部开源,阿里云这次真的把家底都掏出来了。