OAI/谷歌/DeepSeek首次合体「AI梦之队」!战力飙升30%,碾压一切单模型
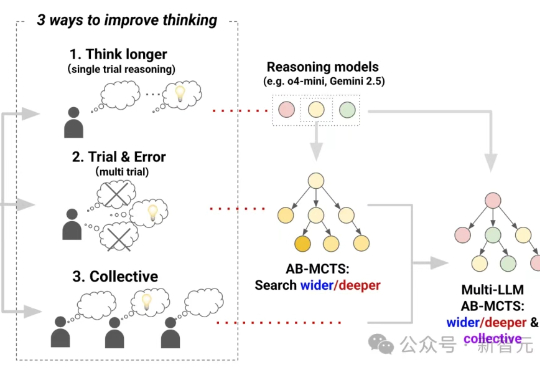
OAI/谷歌/DeepSeek首次合体「AI梦之队」!战力飙升30%,碾压一切单模型三个前沿AI能融合成AGI吗?Sakana AI提出Multi-LLM AB-MCTS方法,整合o4-mini、Gemini-2.5-Pro与DeepSeek-R1-0528模型,在推理过程中动态协作,通过试错优化生成过程,有效融合群体AI智慧。
来自主题: AI技术研报
9806 点击 2025-07-06 13:06