

Claude Code从来就不是什么编程工具
Claude Code从来就不是什么编程工具1月12日,Anthropic发布了一款新产品Cowork。官方给它的定义很有意思:Claude Code for the rest of your work,给剩下那些不写代码的人用的Claude Code。
来自主题: AI资讯
10492 点击 2026-01-19 15:12
1月12日,Anthropic发布了一款新产品Cowork。官方给它的定义很有意思:Claude Code for the rest of your work,给剩下那些不写代码的人用的Claude Code。

一早,OpenAI曝光了过去三年营收数据,信息量巨大:2025年ARR突破200亿美元,算力与收入几乎同步飙升,形成了一个强大的自转飞轮。

在全球AI共识下,Agent Skill成为新战场。在国内,字节扣子率先推出Coze Skill,让你的方法论、个人心得瞬间封装成可复用包;加上长期任务的「目标导向协作」,AI帮你拆解步骤、执行计划,真正实现「人类经验注入AI智能体」。

就在今天,飞书合作发布了他们的第一款AI硬件。 是跟安克创新一起做的一个有趣的东西。 他们叫做,AI录音豆。 安克做的硬件,飞书提供的软件和AI服务,他两一拍即合。 对,就是这么个东西,一个小小的录音
大家都知道 Elon Musk 最近和 OpenAI 在硅谷法庭上,「打得火热」,算是「一团和气」。前两天,OpenAI 的总裁 Greg Brockman 终于坐不住了。他直接发推 Diss Elon Musk,指责他为了打官司,竟然断章取义地把自己私人日记里的片段当成证据 😆。

我这样描述 Tala Health,它的种子轮融资,是早期数字医疗公司单轮融资中规模最大的之一,并且其发展阶段与估值之间存在明显脱节。只要你接受这个判断,大概率就会有兴趣把这篇文章看完。
AI工具越出越快,很多人越学越焦虑:怕被裁,怕落后,怕同事比自己更会用AI。一款名为Cursiv AI的教育App就盯着这股情绪下手,12个月内IAP收入超300万美金。

2025年,风光无限的机器人们在Demo中大秀绝活,从叠衣服、工厂和物流站分拣包裹,到零售店卖货……它们忙碌的身影存在于各种各样的场景中。但回到现实世界,具身智能真正参与的生活和生产环节,却少之又少。

当国内的AI大模型战场正陷入“百模大战”的焦灼,巨头们还在比拼参数规模、长文本处理能力和代码生成率时,一家曾经被打上“在线教育”和“题库工具”深深烙印的公司——作业帮,却在海外市场“悄悄”通过一条意想不到的赛道杀出了重围。
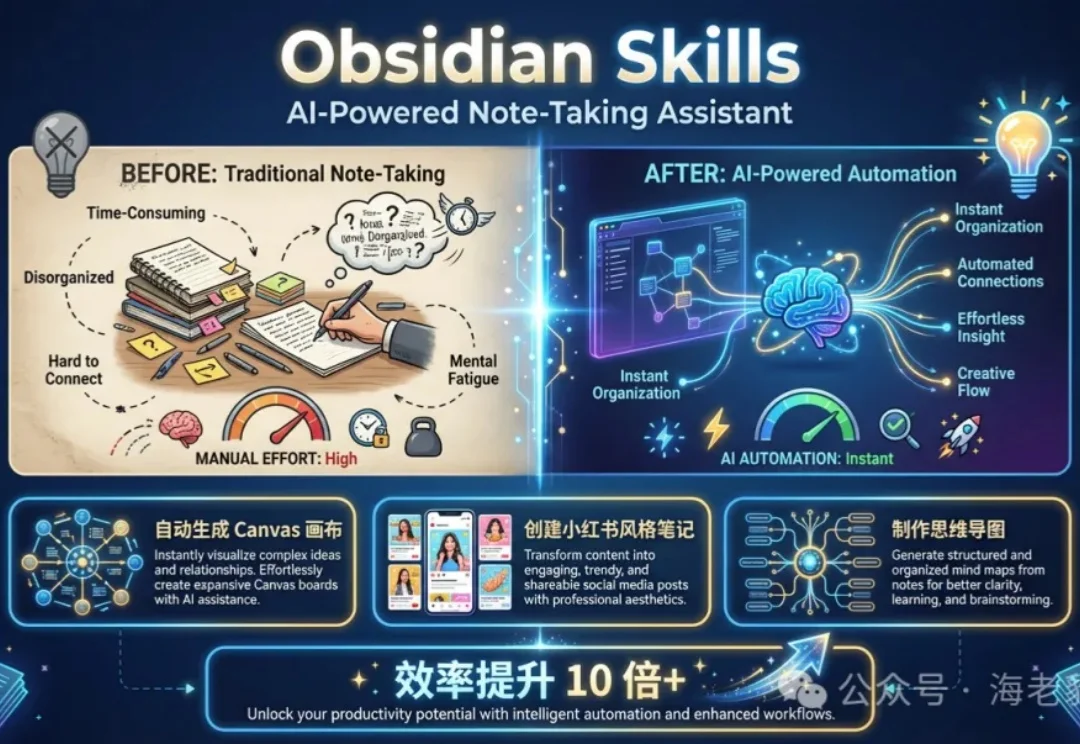
在日常工作和学习中,笔记管理一直是个让人头疼的问题。传统的笔记工具要么功能单一,要么需要手动绘制各种图表和整理格式。特别是当我们需要制作知识结构图、思维导图或者将内容转化为不同风格的笔记时,往往需要花费大量时间和精力。