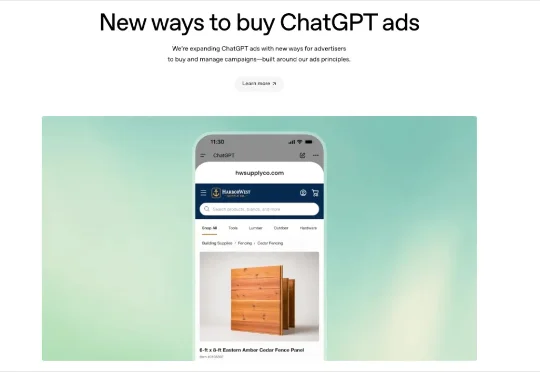
ChatGPT正式上线广告主平台,AI产品从今天开始走向分裂。
ChatGPT正式上线广告主平台,AI产品从今天开始走向分裂。OpenAI准备向企业主全量上线广告平台了。这个非常有意思,我觉得还是可以聊聊的。这玩意你可以理解成,ChatGPT的广告投放后台,美国的企业主可以直接注册账号,充钱,设预算,选竞价策略,上传广告素材,然后一键投放到ChatGPT的对话里,最后实时看数据,实时优化。
来自主题: AI资讯
8649 点击 2026-05-06 10:19
 搜索
搜索
OpenAI准备向企业主全量上线广告平台了。这个非常有意思,我觉得还是可以聊聊的。这玩意你可以理解成,ChatGPT的广告投放后台,美国的企业主可以直接注册账号,充钱,设预算,选竞价策略,上传广告素材,然后一键投放到ChatGPT的对话里,最后实时看数据,实时优化。

AI 闹狩猎夜进入第二站——上海,活动逐渐呈现出我们期待的样子:具体的,奇怪的,有趣的、以及——该死的可爱。
我发现囤Agent的Skills有瘾, 今天刚装了一大堆同类Skill,还没用熟就想提前知道这类里最好的到底是哪一个。转头又发现某个佬推荐了自留的20个Skills,回回路过我都忍不住点进去看。
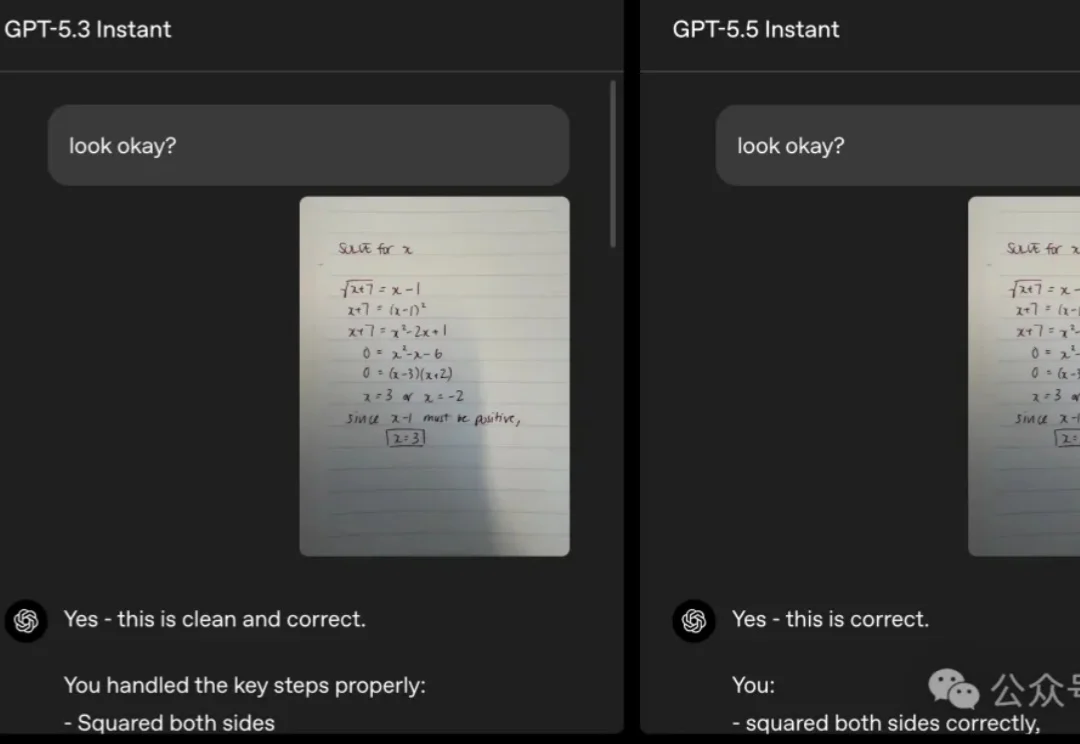
ChatGPT默认模型,今天大升级。

Realtime API 是 OpenAI 的实时语音交互接口,在 24 年的 DevDay 首次亮相,当时还是 beta,调用贵到离谱,音频输出 200 刀/百万 token:OpenAI 凌晨发布:Realtime 实时多模态 API,及其他

5月5日下午5:55,GPT-5.5要给自己办场party——时间是GPT-5.5自己挑的,客人由Codex从推文回复里挑。这场看起来像段子的活动背后,是一个真实的市场拐点:过去两个月,AI编程工具圈发生了一次明显的用户迁移,开发者开始从Claude Code转向Codex。

Anthropic联合创始人Jack Clark读完数百份公开数据,得出一个让他自己也坐不住的结论:2028年底前,AI自己造AI的概率是60%。支撑他这一判断的,是编程、科研复现、模型训练优化等多条能力曲线:每一条都在向右上方飞,没有减速迹象。

柏拉图在《斐德罗篇》里记录了一个古老的对话。

还记得之前破产的扫地机器人鼻祖公司 iRobot 吗?最近它的创始人科林·安格尔(Colin Angle),在经历公司破产重整之后拿出了他的新作品。

独家获悉,RoboScience 机器科学于近日完成十亿元 A 轮融资,投资方包含多家国内外知名产业巨头及一线财务机构。本轮融资将用于持续深化其核心的 VLOA 大模型技术,以及推进自研机器人本体的工程化与量产,加速通用具身智能解决方案的规模化落地。