

速递|为什么红杉资本知名合伙人看好成立一年的AI视频初创?
速递|为什么红杉资本知名合伙人看好成立一年的AI视频初创?红杉资本合伙人肖恩·马奎尔 在过去一年中因与埃隆·马斯克的友谊而声名鹊起,这帮助公司参与了 SpaceX 和 X 的热门融资轮。通过 X,红杉资本还将获得 xAI,马斯克的人工智能实验室的股份。
来自主题: AI资讯
5814 点击 2024-11-02 19:57
红杉资本合伙人肖恩·马奎尔 在过去一年中因与埃隆·马斯克的友谊而声名鹊起,这帮助公司参与了 SpaceX 和 X 的热门融资轮。通过 X,红杉资本还将获得 xAI,马斯克的人工智能实验室的股份。

专注金融领域的AI Agent平台Interface.ai宣布完成3000万美元首次融资,由Avataar Venture Partners领投。

OpenAI 2024年开发者大会第二场(伦敦场)刚结束。 10月初在旧金山举办了第一场 OpenAI 开发者大会,但这次没有像上一场放出很多花活,这次开始走剧透局了!

个性化精品数字人(Personalized Talking Face Generation)强调合成的数字人视频在感官上与真人具有极高的相似性(不管是说话人的外表还是神态)。
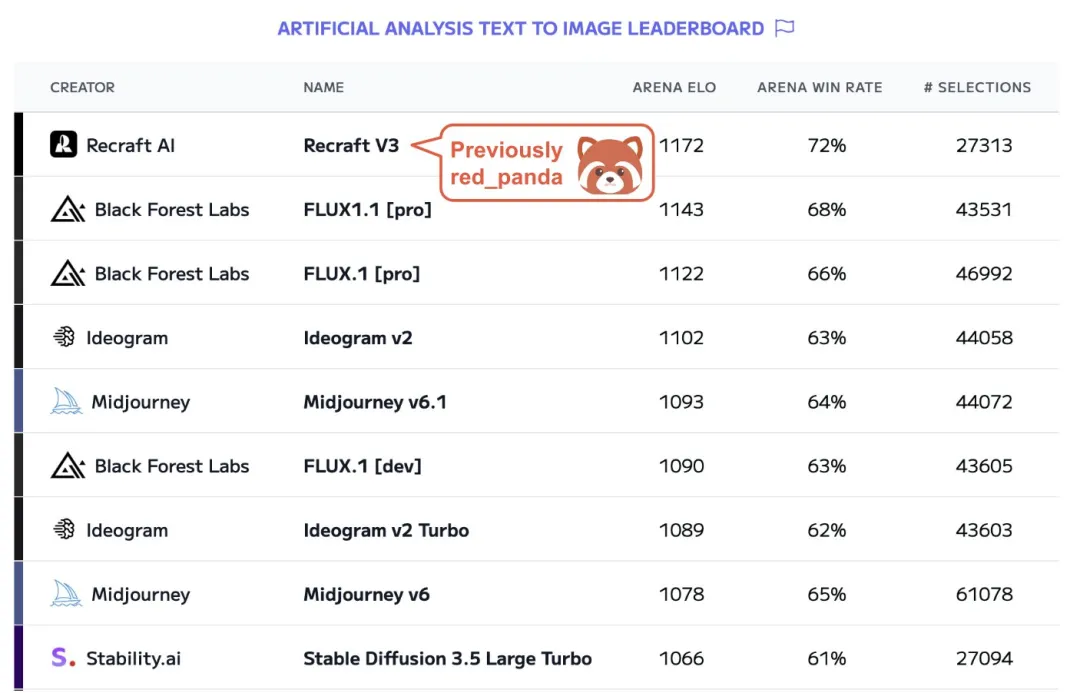
前几天在 Hugging Face 文本转图像排行榜上排名第一的 red_panda,是一个名为 Recraft V3 的模型,由 AI 初创公司 Recraft 提供。 Recraft V3 以 1172 的 ELO 评分位居第一,超越了 Midjourney、OpenAI 和其他公司的模型。

北京时间 10 月 30 日,GitHub Universe 2024 如约而至,而今年正值大会十周年纪念日。本文将从 GitHub 发布的 AI 新进展入手,围绕开源模型、用户数量、盈利模式、发展历程等几个方面,全面梳理 GitHub 与 Hugging Face 两大开源平台的异同。
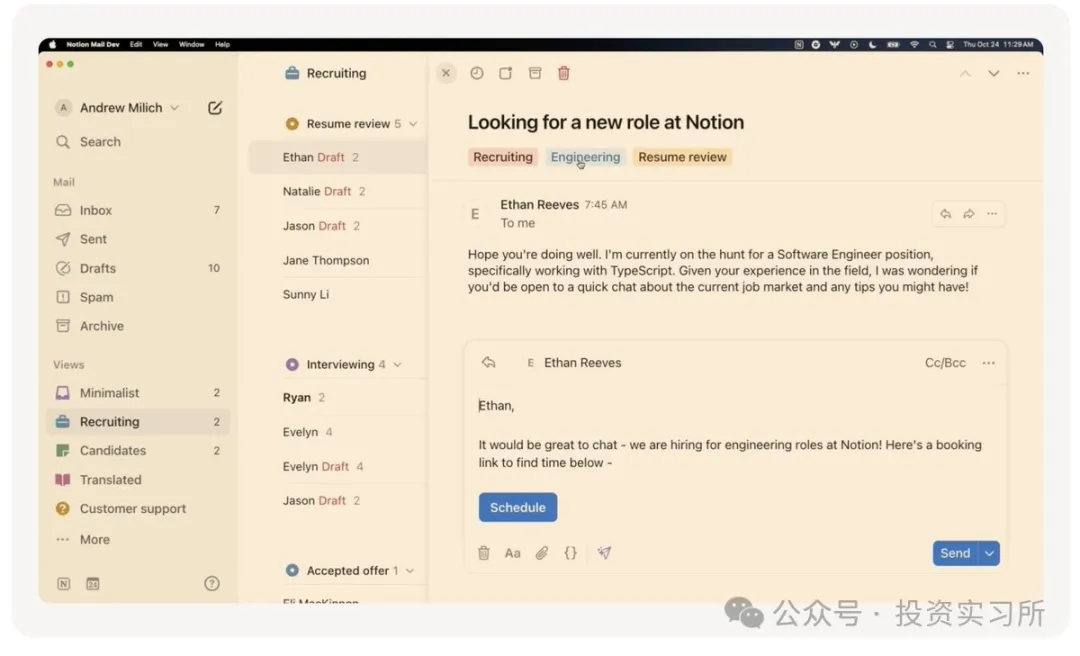
Notion 今天举行了一个叫 Make with Notion 的发布会,这次发布会发布了一系列的新功能和产品,包括了表单(Forms)、布局(Layouts)、自动化(Automations)、Notion AI、交易市场(Marketplace) 以及大家最期待的 Notion Email。
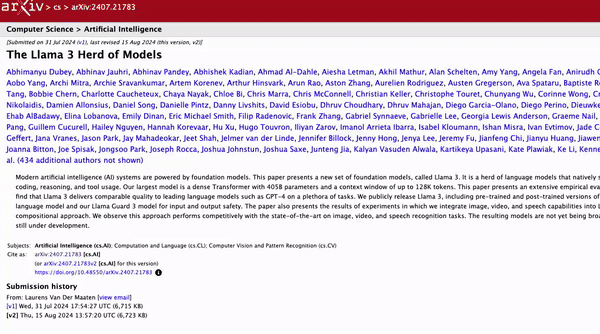
「这才是开放研究该有的样子。」 经常刷 arXiv 的同学,你有没有发现页面上多了个新功能?这个新功能(图中的「Hugging Face」按钮)隐藏在「Code, Data, Media」选项卡下,选中之后就可以直达相关的 Hugging Face 论文、模型和数据集。

2023年8月18日,字节跳动旗下AI对话产品Grace,更名为「豆包」。

10 月 14 日,达龙·阿西莫格鲁(Daron Acemoglu)在希腊雅典一家酒店的阳台上,接到了诺贝尔奖委员会的电话。“人们很早就说过你会获奖,你一定想到了这一刻的到来。” 工作人员说。