
别告诉AI你出轨了,它很可能会勒索你
别告诉AI你出轨了,它很可能会勒索你“先生,你也不想你婚外情被曝光吧?不想的话就照我说的做。”
来自主题: AI资讯
10262 点击 2026-04-16 11:18
 搜索
搜索
“先生,你也不想你婚外情被曝光吧?不想的话就照我说的做。”
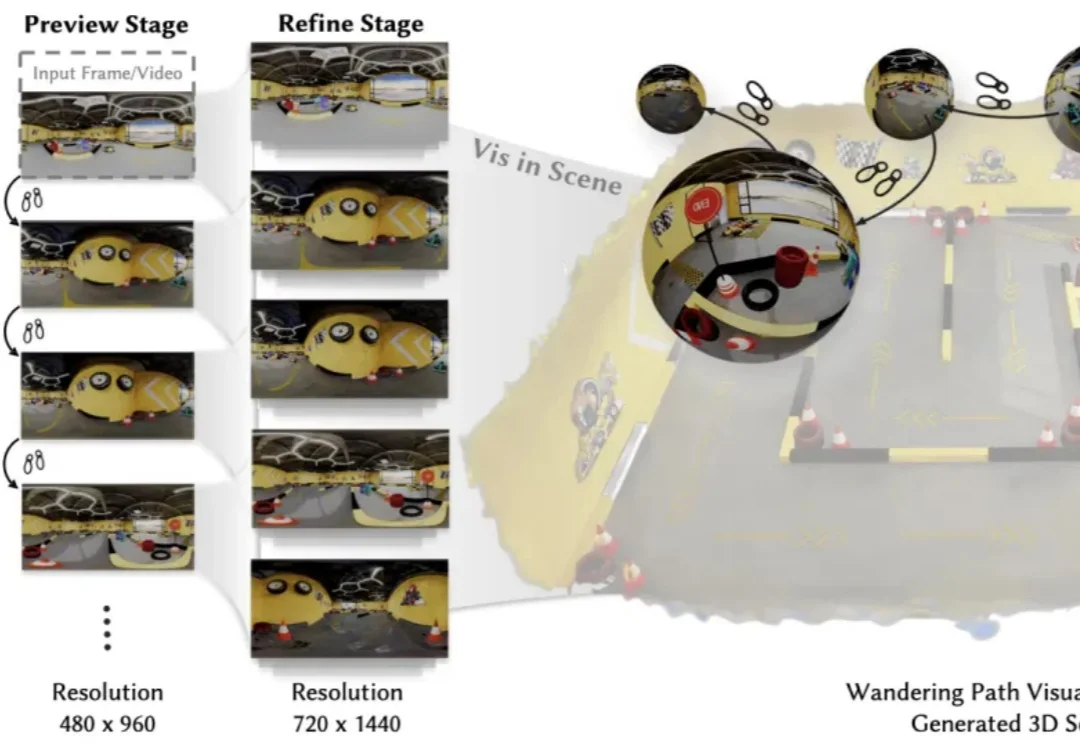
在生成式视频快速发展的今天,模型已经能够生成高质量的短视频片段,但一个更具挑战性的问题正逐渐成为研究焦点:
上周 Anthropic 发布 Mythos Preview 的时候,安全圈的反应可以用一个词概括:震惊。

当大模型训练进入深水区,竞争的关键已经不再只是「模型参数怎么调」,而逐渐转向一个更核心、也更难系统解决的问题:模型在训练过程中究竟看到了什么数据、以什么比例看到、哪些样本应该被更频繁地学习。
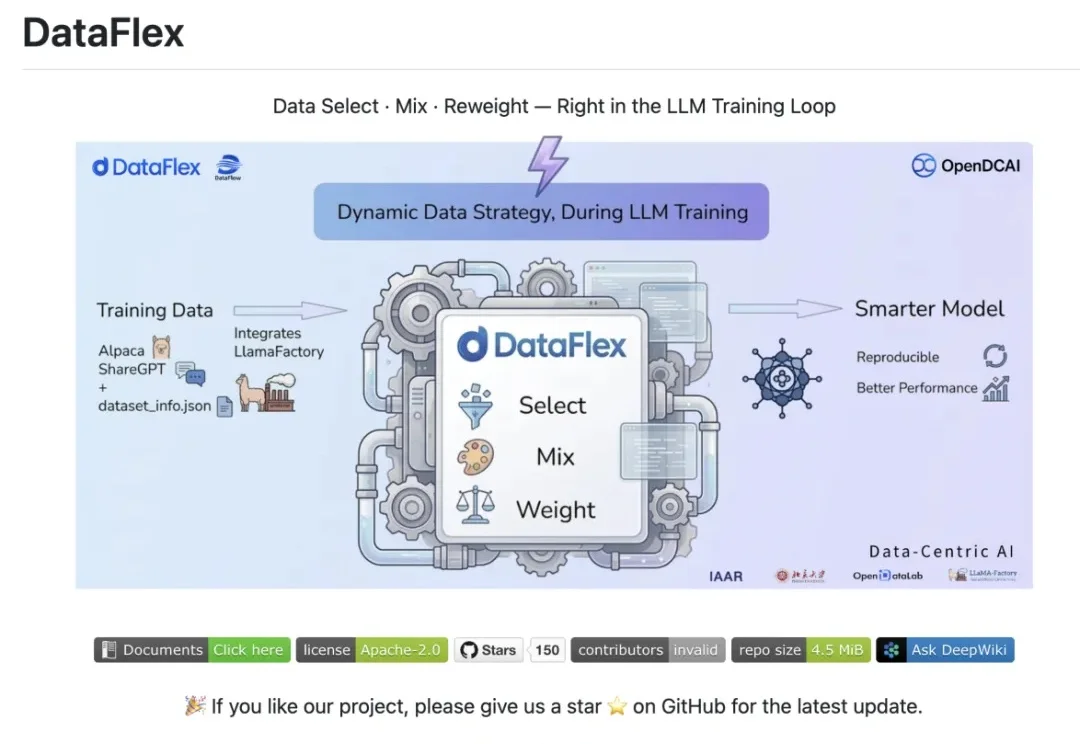
当大模型训练进入深水区,竞争的关键已经不再只是「模型参数怎么调」,而逐渐转向一个更核心、也更难系统解决的问题:模型在训练过程中究竟看到了什么数据、以什么比例看到、哪些样本应该被更频繁地学习。

今日,腾讯正式发布并开源混元3D世界模型2.0(HY-World 2.0)。作为一款多模态的世界模型,HY-World 2.0支持文字、图片和视频等形式输入,可自动生成、重建并模拟完整的3D世界。

如果你是一家连年亏损、销售额腰斩、连线下门店都要全部关停的卖鞋公司,你要怎么做才能让公司股价在一天之内原地起飞,暴涨 700%?答案是停止卖鞋,然后大声喊出那五个拥有起死回生魔力的字母:AI+GPU。

当一家成立不到两年、团队规模不过 10 人的创业公司被收购,并在数周内关闭产品、清空数据,这通常不会成为行业关注的焦点。但这一次不同。收购方是 OpenAI,而被收购的,是一家试图用模型重写个人理财方式的初创公司——Hiro Finance。
刚刚,图灵联合创始人刘江在海外社交媒体X上透露,DeepSeek核心研究院——郭达雅已加入字节跳动。 郭达雅2023年博士毕业后加入DeepSeek,title是AI Researcher。公开论文显示,从 DeepSeek-Coder、DeepSeek-Math、DeepSeek-Prover、DeepSeek-V3到 DeepSeek-R1,他都出现在核心作者名单中。

Anthropic 正式宣布在 Claude 平台推出身份验证功能。为了防止滥用、落实平台政策及履行法律合规义务,部分用户在访问特定功能或触发平台风控(完整性检查)时,将弹出强制验证提示。Anthropic 要把中国用户往绝路上逼!