
快手可灵团队最新开源项目火了:大叔实时变身少女,GitHub狂揽7.5K星
快手可灵团队最新开源项目火了:大叔实时变身少女,GitHub狂揽7.5K星离大谱!!不看视频完整版谁知道里面的美少女竟是一位大叔。
来自主题: AI资讯
4998 点击 2024-07-24 10:07
 搜索
搜索
离大谱!!不看视频完整版谁知道里面的美少女竟是一位大叔。
不用H100,三台苹果电脑就能带动400B大模型。 背后的功臣,是GitHub上的一个开源分布式AI推理框架,已经斩获了2.5k星标。

编码器模型哪去了?如果 BERT 效果好,那为什么不扩展它?编码器 - 解码器或仅编码器模型怎么样了?
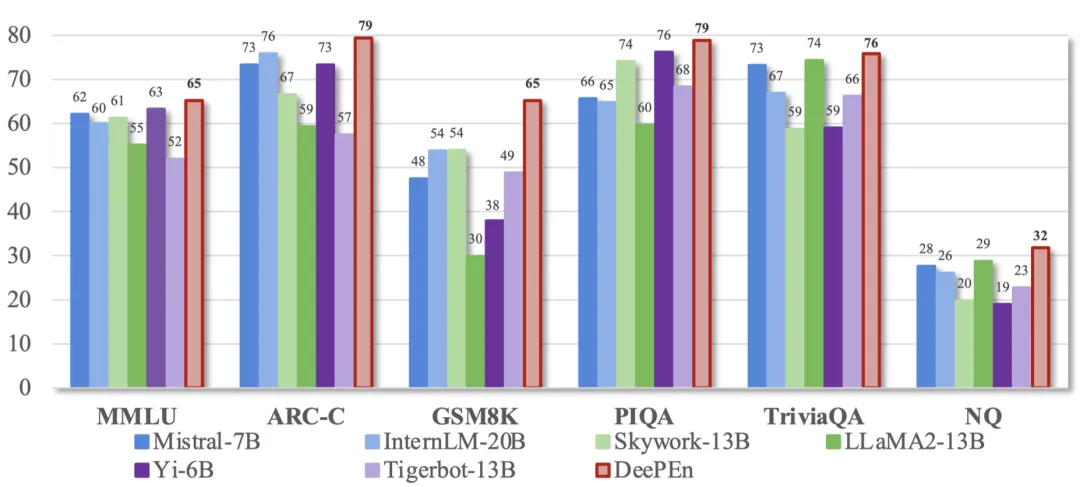
随着大语言模型展现出惊人的语言智能,各大 AI 公司纷纷推出自己的大模型。这些大模型通常在不同领域和任务上各有所长,如何将它们集成起来以挖掘其互补潜力,成为了 AI 研究的前沿课题。
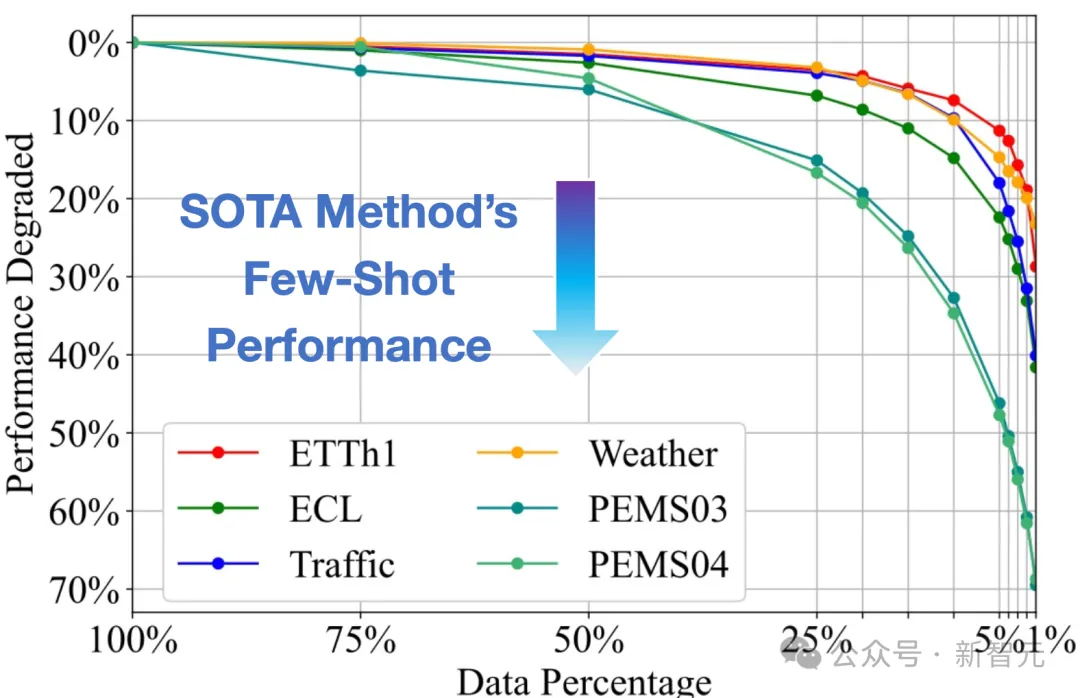
大模型在语言、图像领域取得了巨大成功,时间序列作为多个行业的重要数据类型,时序领域的大模型构建尚处于起步阶段。近期,清华大学的研究团队基于Transformer在大规模时间序列上进行生成式预训练,获得了任务通用的时序分析模型,展现出大模型特有的泛化性与可扩展性

好家伙!为了揭秘Transformer内部工作原理,陈丹琦团队直接复现——

无需训练或微调,在提示词指定的新场景中克隆参考视频的运动,无论是全局的相机运动还是局部的肢体运动都可以一键搞定。

AI 代理得越来越重要,能够实现自主决策和解决问题。为了有效运作,这些代理需要一个确定最佳行动方案的规划过程,然后执行计划的行动。

Mamba模型由于匹敌Transformer的巨大潜力,在推出半年多的时间内引起了巨大关注。但在大规模预训练的场景下,这两个架构还未有「一较高低」的机会。最近,英伟达、CMU、普林斯顿等机构联合发表的实证研究论文填补了这个空白。

近年来,人物动作生成的研究取得了显著的进展,在众多领域,如计算机视觉、计算机图形学、机器人技术以及人机交互等方面获得广泛的关注。然而,现有工作大多只关注动作本身,以场景和动作类别同时作为约束条件的研究依然处于起步阶段。