
75年后,图灵测试终被GPT-4.5破解!73%人类被骗过,彻底输给AI
75年后,图灵测试终被GPT-4.5破解!73%人类被骗过,彻底输给AI在三方图灵测试中,UCSD的研究人员评估了当前的AI模型,证明LLM已通过图灵测试。在测试中,同时与人及AI系统进行5分钟对话,然后判断哪位是「真人」。结果,AI竟然比「真人」还像人:
来自主题: AI资讯
9308 点击 2025-04-03 09:54
 搜索
搜索
在三方图灵测试中,UCSD的研究人员评估了当前的AI模型,证明LLM已通过图灵测试。在测试中,同时与人及AI系统进行5分钟对话,然后判断哪位是「真人」。结果,AI竟然比「真人」还像人:
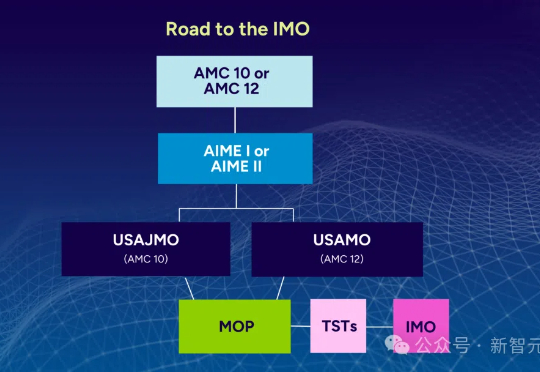
在数学推理中,大语言模型存在根本性局限:在美国数学奥赛,顶级AI模型得分不足5%!来自ETH Zurich等机构的MathArena团队,一下子推翻了AI会做数学题这个神话。

史上最大的基因组AI模型Evo 2使用超过12.8万个基因组数据训练,包含9.3万亿个核苷酸,能预测突变效应、设计 DNA 序列,并通过可视化工具展示学习到的生物特征,为生成生物学和疾病研究提供新思路。

给AI一张全新的照片,它能以相当高的准确率还猜出照片在哪个城市拍摄的。在新研究中,表现最好的AI模型,猜出图片所在城市的正确率比人类高62.6%!以后网上晒图可要当心了,AI可能知道你在哪里!

最近几天,OpenAI 革新的 GPT-4o 图像功能给大家带来了不少乐趣,各路社交媒体都被「吉卜力」风格的图像、视频刷了屏。机器之心还尝试了制作了《甄嬛传》的名场面(视频如下,制作方法参见《GPT-4o 整活!3 个小时、6 个镜头重现吉卜力版《甄嬛传》名场面》)。

本文介绍了当前最受科研人员青睐的AI模型,推理出色的o3-mini、全能型DeepSeek-R1、科研常用的Llama、编程利器Claude 3.5 Sonnet和开源明星Olmo 2,它们各有优劣,为科研人员提供了多样选择。

如今,美国AI社区许多人已公认:接下来几个月,中国将会出现一波开源AI模型的浪潮!很多业内人士和大V干脆陷入了「冷战2.0」恐慌,呼吁要开放无限的能源、无限的算力和更简单的立法。LeCun则表示,DeepSeek击败美国,其实不过是中国内部竞争的副产品而已。
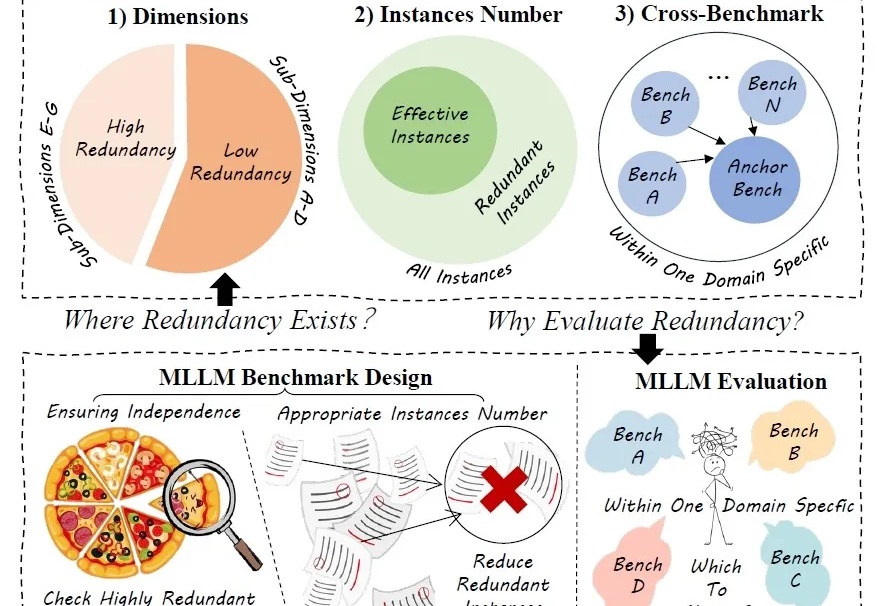
评估多模态AI模型的那些复杂测试,可能有一半都是“重复劳动”!

OpenAI 请求特朗普政府提供更多法律保护
ChatGPT等AI模型爆发式增长引发关键问题:这场AI革命需要消耗多少能源?本文探究数据中心在乡村地区的快速扩张,以弗吉尼亚州为例,揭示研究者如何通过供应链分析和直接测量两种方法估算AI能耗。