ICML25 | 让耳朵「看见」方向!仅依靠360°全景视频,就能生成3D空间音频
ICML25 | 让耳朵「看见」方向!仅依靠360°全景视频,就能生成3D空间音频空间音频,作为一种能够模拟真实听觉环境的技术,正逐渐成为提升沉浸式体验的关键。
来自主题: AI技术研报
10768 点击 2025-05-15 10:56
 搜索
搜索
空间音频,作为一种能够模拟真实听觉环境的技术,正逐渐成为提升沉浸式体验的关键。
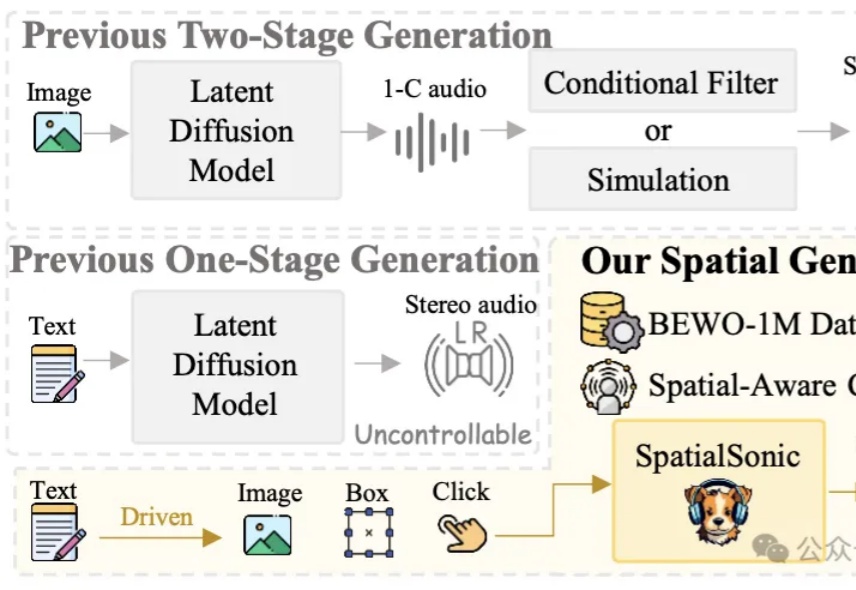
兔子通过两只耳朵可以准确感知捕食者的一举一动,造就了不同品种广泛分布在世界各地的生命奇迹;同样人也需要通过双耳沉浸式享受电影视听盛宴、判断驾驶环境和感知周围活动状态。

Akool 于 2022 年成立,短时间取得了巨大的成就,ARR 超过 4000 万美元。其主要布局视频编辑与生成赛道,瞄准 ToB 业务,为企业提供高效、智能的视频生成解决方案。

AI音频的价值被持续挖掘。
Meta最近开源了一个7B尺寸的Spirit LM的多模态语言模型,能够理解和生成语音及文本,可以非常自然地在两种模式间转换,不仅能处理基本的语音转文本和文本转语音任务,还能捕捉和再现语音中的情感和风格。

Gladia筹集了1600万美元用于AI转录和分析。
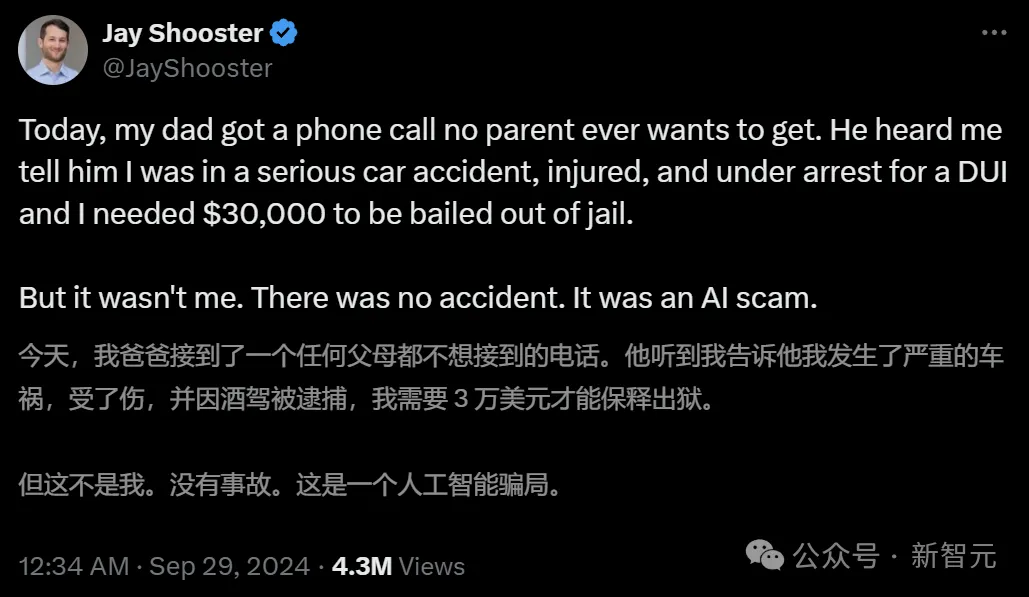
AI泛滥成灾的时代,真假孰能分辨? 最近,国外一位专业律师Jay Shooster自曝,自己的父亲陷入了一场巨大的AI骗局。
AI硬件市场虽然目前市场规模相对较小,但增长速度较快,未来发展潜力巨大。目前市面上已经出现多款可穿戴性AI硬件设备,包括Humane推出的Ai Pin和Rabbite R1等。不仅各类初创公司涌现,多家巨型科技公司也布局其中。

AI+硬件或许是伪需求,硬件+AI不是。

除了手机之外,AI 硬件最大的机会是什么? Meta 雷朋眼镜销量破百万之后,AI 眼镜越来越成为共识。