谷歌Gemini推出实时AI视频功能
谷歌Gemini推出实时AI视频功能谷歌发言人 Alex Joseph 在给The Verge的电子邮件中证实,谷歌已开始向 Gemini Live 推出新的 AI 功能,使其能够看到你的屏幕或通过你的智能手机摄像头回答有关实时问题。
来自主题: AI资讯
8213 点击 2025-03-24 09:09
 搜索
搜索
谷歌发言人 Alex Joseph 在给The Verge的电子邮件中证实,谷歌已开始向 Gemini Live 推出新的 AI 功能,使其能够看到你的屏幕或通过你的智能手机摄像头回答有关实时问题。

知名 AI 工程师、Pleias 的联合创始人 Alexander Doria 最近针对 DeepResearch、Agent 以及 Claude Sonnet 3.7 发表了两篇文章,颇为值得一读,尤其是 Agent 智能体的部分。

从一行行代码、注释中感受 AlexNet 的诞生,或许老代码中还藏着启发未来的「新」知识。

3月18日,美国哥伦比亚特区巡回上诉法院就科学家Stephen Thaler(史蒂芬·泰勒博士,下称泰勒)诉Shira Perlmutter(美国版权局注册官及美国版权办公室主任)以及美国版权局作出标志性判决,认定所有受版权保护的作品必须首先由人类创作。尽管AI技术的发展使得非人类创作的作品越来越多,但根据现有的法律框架,这些作品无法获得版权保护。
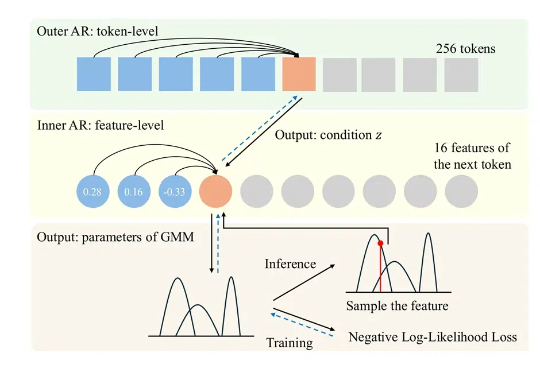
澳大利亚国立大学团队提出了ARINAR模型,与何凯明团队此前提出的分形生成模型类似,采用双层自回归结构逐特征生成图像,显著提升了生成质量和速度,性能超越了FractalMAR模型,论文和代码已公开。

到目前为止,百川智能是所有大模型企业中,唯一对外高调表达要all in 医疗的。这种明确的表态,让百川智能备受关注的同时,也背负了很多的质疑。百川智能和王小川近日再次成为媒体关注的焦点,主要关注点是百川智能的组织调整,以及大部分人对于百川为什么收缩金融业务而all in医疗表示出极大的不解。

在GTC2025大会上,NVIDIA依旧延续着“算力的故事”。如果AI的发展依旧遵循着scaling law(规模定律),那么这个故事还能继续讲下去。

这是SemiAnalysis最新的一篇GTC大会的分析文章,难得Dylan这么勤快,在GTC放发布后,就立马出了这篇长达31页的分析报告。
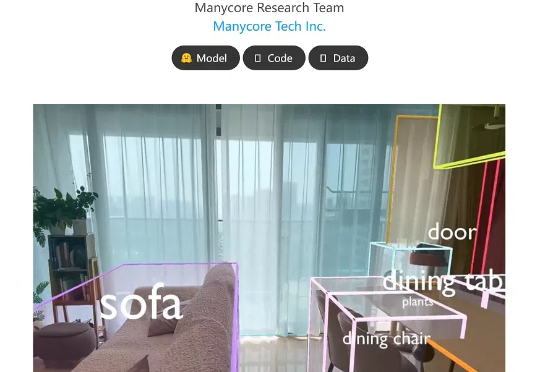
前脚被谷歌点名感谢空间训练平台,后脚又开源了空间模型!杭州六小龙群核科技发了一个空间理解开源模型SpatialLM,让机器人刷一段视频,就能理解物理世界的几何关系。结合之前发布的空间智能训练平台SpatialVerse,群核科技要为机器人提供从空间认知到行动交互的训练闭环。机器人也被「卷」到要上学了。
Stability AI 发布了一款新 AI 模型——Stable Virtual Camera,该公司宣称该模型能将 2D 图像转化为,具有真实深度和视角的“沉浸式”视频。