免费功能卷翻付费版ChatGPT,欧洲AI新贵叫板OpenAI
免费功能卷翻付费版ChatGPT,欧洲AI新贵叫板OpenAI欧洲OpenAI”Mistral AI有新动作了! Le Chat(法语“猫”)全新升级,官方自称它是“您生活和工作的终极AI助手”。
来自主题: AI资讯
8309 点击 2025-02-07 20:07
 搜索
搜索
欧洲OpenAI”Mistral AI有新动作了! Le Chat(法语“猫”)全新升级,官方自称它是“您生活和工作的终极AI助手”。

AI的新进展频频,人才动态也愈加重磅。 新年第一则大牛人事动向,引发业内关注。 许主洪,IEEE Fellow,新加坡管理大学终身教授,被曝加盟阿里。
各位同学好,我是来自 Unlock-DeepSeek 开源项目团队的骆师傅。先说结论,我们(Datawhale X 似然实验室)使用 3 张 A800(80G) 计算卡,花了 20 小时训练时间,做出了可能是国内首批 DeepSeek R1 Zero 的中文复现版本,我们把它叫做 Datawhale-R1,用于 R1 Zero 复现教学。

新一代 Kaldi 团队是由 Kaldi 之父、IEEE fellow、小米集团首席语音科学家 Daniel Povey 领衔的团队,专注于开源语音基础引擎研发,从神经网络声学编码器、损失函数、优化器和解码器等各方面重构语音技术链路,旨在提高智能语音任务的准确率和效率。
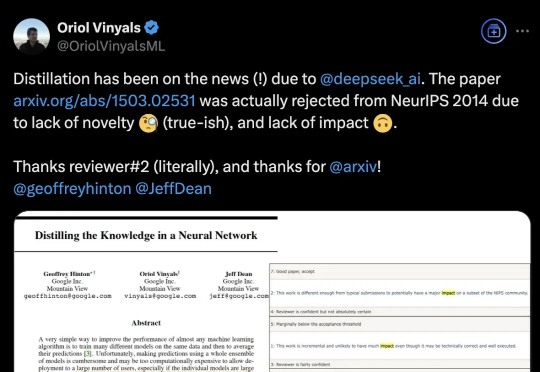
DeepSeek带火知识蒸馏,原作者现身爆料:原来一开始就不受待见。称得上是“蒸馏圣经”、由Hinton、Oriol Vinyals、Jeff Dean三位大佬合写的《Distilling the Knowledge in a Neural Network》,当年被NeurIPS 2014拒收。

2025年,软件工程要彻底变天了。先有奥特曼预言,后有微软下场All in智能体。刚刚,首个自主SWE智能体面世,不仅会主动改bug修复错误,还能自主提交PR评论。

在当前AI领域的快速发展中,“强推理慢思考”已经成为主要的发展动向之一,它们深刻影响着研发方向和投资决策。如何将强推理慢思考进一步推广到更多模态甚至是全模态场景,并且确保和人类的价值意图相一致,已成为一个极具前瞻性且至关重要的挑战。

Hallow作为一款天主教祈祷与冥想应用,为用户提供了一个便捷的平台,将祈祷和正念修行融入日常生活。通过引导式冥想、每日圣经阅读和社区挑战,Hallow 旨在帮助用户建立联系感和共同目标,在全球范围内增强信仰体验。

机器人界「球星」竟被CMU英伟达搞出来了!科比后仰跳投、C罗、詹皇霸气庆祝动作皆被完美复刻。2030年,我们将会看到一场人形机器人奥运会盛宴。
Ilya Sutskever 在 NeurIPS 会上直言:大模型预训练这条路可能已经走到头了。上周的 CES 2025,黄仁勋有提到,在英伟达看来,Scaling Laws 仍在继续,所有新 RTX 显卡都在遵循三个新的扩展维度:预训练、后训练和测试时间(推理),提供了更佳的实时视觉效果。