国产AI黑马引爆「商战版Palantir」!一键为企业「全自主赚钱」
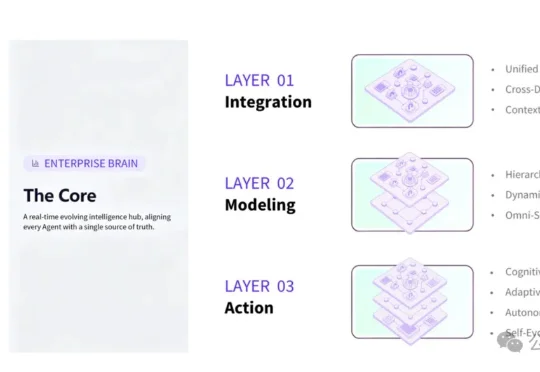
国产AI黑马引爆「商战版Palantir」!一键为企业「全自主赚钱」6月5日,百型智能正式发布第三代企业级 AI 基础设施——OntoZ。这款新产品跳出了传统单点SaaS与孤立智能体的产品逻辑,以企业本体为底层基座,搭建可动态自迭代的群智能体协同体系,为企业打造具备自主进化能力的数字生产力底座。
来自主题: AI资讯
8798 点击 2026-06-05 15:30
 搜索
搜索
6月5日,百型智能正式发布第三代企业级 AI 基础设施——OntoZ。这款新产品跳出了传统单点SaaS与孤立智能体的产品逻辑,以企业本体为底层基座,搭建可动态自迭代的群智能体协同体系,为企业打造具备自主进化能力的数字生产力底座。
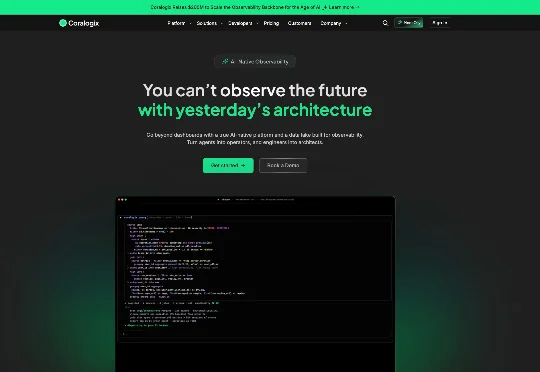
Coralogix,一家总部位于波士顿、创立于以色列的软件监控初创公司,已在新一轮融资中筹集 2 亿美元。该投资押注 AI Agent 的兴起将催生新一代工具的需求,用于监控、排障并管理日益自主化的软件系统。

6月5日,腾讯云AI产业应用大会上,腾讯集团高级执行副总裁汤道生和首席AI科学家姚顺雨同台对谈。这是姚顺雨加入腾讯后第一次在公司活动中公开亮相。这场对谈的主题叫《腾讯AI的下半场》。2025年4月,姚顺雨曾在个人博客发表《The Second Half》一文,在技术社区广泛传播。文章的核心判断是:AI正站在中场分界线上,上半场的核心在于训练方法和模型的突破

都以为让AI查数据省事,结果它答得漂亮你却不敢信。Anthropic最近说这事有解了,靠的是一套和代码无关的「笨功夫」。

我在 2025 年年度总结的文章《Attention is all you need》里,提到在关注 AI 时代的投资机会,看了很多硅谷的播客和视频,一直想来硅谷看看,但自己认识的这边的人不多,恰好看到Linkloud 组织“创业加速营”,安排了不少硅谷当地的华人创业者、大厂从业人员的交流,就报名了,同去的其他人,还有想要 AI 转型或者就在 AI 领域创业的创始人或者中高管等。
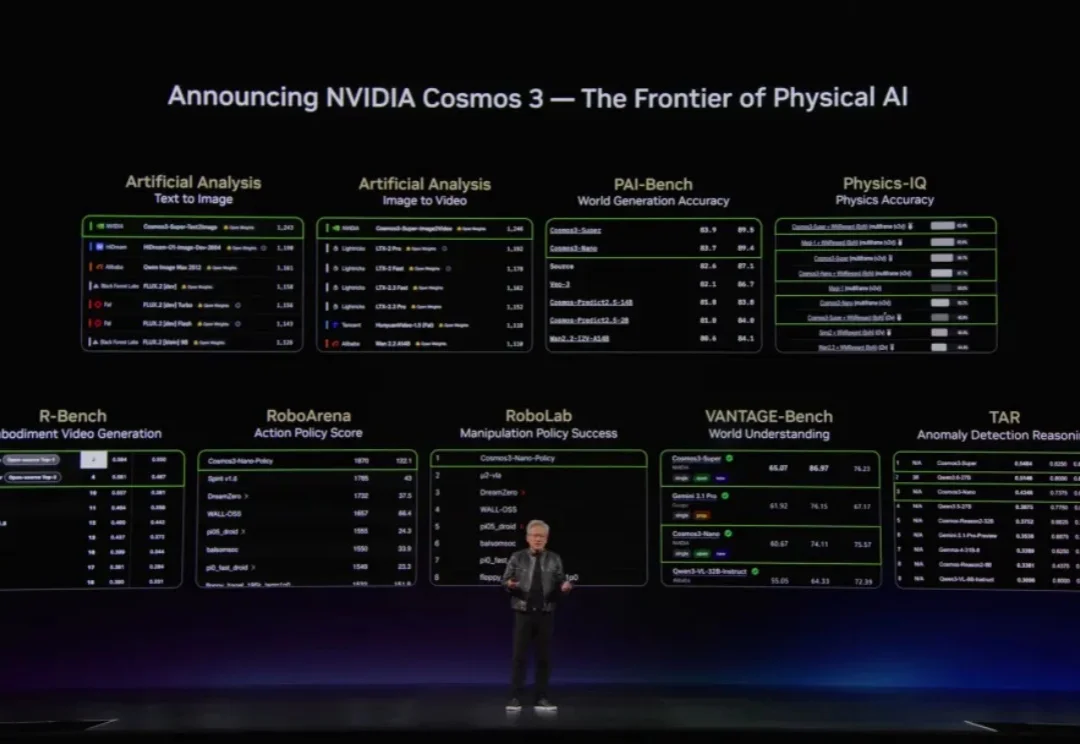
6 月 1 日,老黄在 GTC 上用了不小的篇幅讲物理 AI 和具身智能,并重磅发布了 Cosmos 3。英伟达将其定义为面向 Physical AI 的最新前沿模型,也是全球首个完全开放的全能模型,原生具备视觉推理、世界生成和动作生成能力。

一直有在关注的一个 AI 短剧工具最近终于上线了,那就是群核科技的 LuxReal 短剧版。

Harvey 是全球最大的法律 AI 公司,客户是世界顶尖律所和企业法务团队。你可能没怎么听说过它,但在法律行业,它基本上是那个大家已经在用、不需要再讨论的选择——就像律师界的 Salesforce,你不会问"要不要用",只问"怎么接进来"。

奥特曼说,这块地或许能攻克癌症。可对于密歇根Saline小镇的居民来说,它先改写的却是自家后院。

Liquid AI 近期推出的 LocalCowork,正是直面这一矛盾的产物:单台笔记本,无需云端 API,数据绝不离机。凭借 67 个本地工具、13 个 MCP Servers,配合最新发布的 LFM2.5-8B-A1B 模型,它通过本地调用工具、解释结果以及可审计的工作流,解决了上述难题。